
What is Data Classification?
The process of organization and categorization of data is known as data classification. In this blog, we will discuss the ways to do data classification and its essentials.
Table of Contents
- What is Data Classification?
- Importance of Data Classification
- Types of Data Classification
- How to Implement Data Classification?
- Benefits of Data Classification
- Example of Data Classification
- Challenges in Data Classification
- Conclusion
Learn the Ethical Hacking course in-depth by watching the video below
{
“@context”: “https://schema.org”,
“@type”: “VideoObject”,
“name”: “Ethical Hacking Course | Ethical Hacking Tutorial Online | Learn Ethical Hacking | Intellipaat”,
“description”: “What is Data Classification?”,
“thumbnailUrl”: “https://img.youtube.com/vi/CyRj4yGiL9A/hqdefault.jpg”,
“uploadDate”: “2023-07-18T08:00:00+08:00”,
“publisher”: {
“@type”: “Organization”,
“name”: “Intellipaat Software Solutions Pvt Ltd”,
“logo”: {
“@type”: “ImageObject”,
“url”: “https://intellipaat.com/blog/wp-content/themes/intellipaat-blog-new/images/logo.png”,
“width”: 124,
“height”: 43
}
},
“embedUrl”: “https://www.youtube.com/embed/CyRj4yGiL9A”
}
What is Data Classification?
Ensuring data security is the purpose of data classification. It carefully looks into the way data is stored, processed, and transmitted securely. It involves analyzing data, evaluating its importance, and assigning a classification level based on its attributes. The classification level determines the level of protection and management requirements for the data.
The data classification process consists of the following steps:
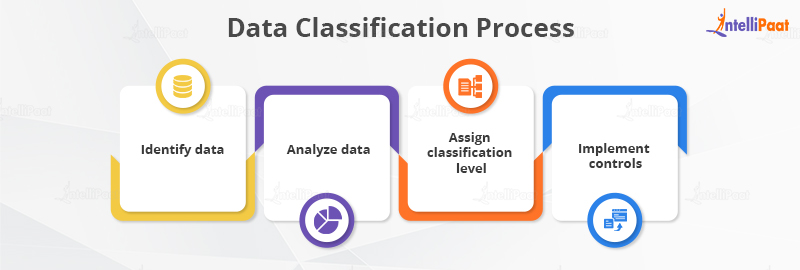
- Identify Data: It involves identifying the data that needs to be classified. This includes understanding the type of data, its value, and the risks associated with it.
- Analyze Data: Analyzing the data to understand its sensitivity level is an important part of data classification. The process involves identifying the confidentiality, integrity, and availability requirements of the data.
- Assign Classification Level: Based on the analysis, the data is assigned to a classification level. It will be according to the sensitivity, regulatory requirements, and value of the data.
- Implement Controls: The final step involves implementing appropriate controls to protect the data based on the classification level. This includes access controls, encryption, and monitoring.
Interested to learn about Ethical Hacking? Enroll now in Ethical Hacking Training!
Importance of Data Classification
Data classification is crucial for organizations for the following reasons:
- Risk Management: Data classification helps organizations identify and mitigate risks associated with their data. By categorizing data based on its sensitivity level, organizations can prioritize their security efforts and allocate resources accordingly.
- Compliance: Many industries have specific regulatory requirements for handling sensitive data. Data classification helps organizations to ensure compliance with these regulations by implementing appropriate controls based on the classification level.
- Data Protection: Data classification helps organizations to protect their data from unauthorized access, theft, and misuse. By assigning a classification level, organizations can implement appropriate controls to protect the data based on its sensitivity level.
- Efficiency: Data classification helps organizations to manage their data more efficiently. By categorizing data based on its value and sensitivity, organizations can allocate resources more effectively and ensure that data is stored and processed securely and efficiently.
Check Out Ethical Hacking Interview Questions to crack your ethical hacking job interview!
Types of Data Classification
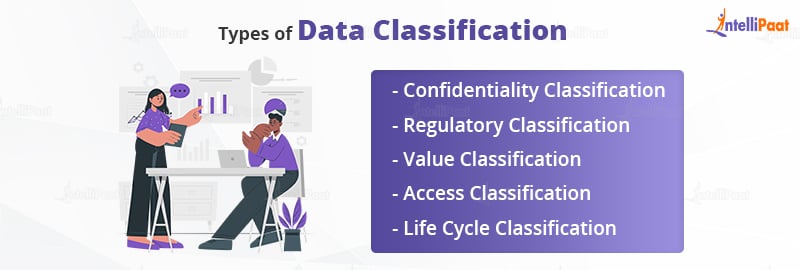
There are different types of data classification based on the attributes. Some of the common types of data classification are:
- Confidentiality Classification: This type of data classification is based on the level of confidentiality required for the data. The data is classified as confidential, internal use only, or public based on its sensitivity level.
- Regulatory Classification: This type of data classification is based on the regulatory requirements for handling the data. The data is classified as highly regulated, regulated, or non-regulated based on the level of regulatory requirements.
- Value Classification: This type of data classification is based on the value of the data to the organization. The data is classified as critical, important, or routine based on its importance to the organization.
- Access Classification: This type of data classification is based on the level of access required for the data. The data is classified as restricted, controlled, or open based on the level of access required.
- Life Cycle Classification: This type of data classification is based on the life cycle stage of the data. The data is classified as active, inactive, or archived based on its life cycle stage.
Read On: Ethical Hacking Tutorial to enhance your knowledge!
How to Implement Data Classification?
Once the data has been identified, it can be classified based on various criteria, such as content, format, purpose, and sensitivity. Some common classification categories include confidential, internal use only, public, and restricted access.
Manual classification is another method where a person goes through each piece of data and assigns a category. This method can be time-consuming and prone to human error. However, it allows for a more personalized and specific approach to classification.
On the other hand, automatic classification requires software to analyze data and classifies it based on predetermined rules. This method is faster and more consistent. Nevertheless, it may not be as accurate as manual classification.
There are several techniques used in data classification, such as rule-based classification, where a set of rules is used to determine the classification of data. The rules can be based on keywords, file types, or other criteria. Machine learning-based classification is another technique. In this, machine learning algorithms are used to analyze data and classify it based on patterns and characteristics.
Benefits of Data Classification
Below we will highlight some of the benefits of data classification:
- Enhanced Data Organization: Data classification provides a systematic way to organize large datasets. By categorizing and labeling data based on specific criteria, such as type, relevance, or priority, it becomes easier to locate, access, and manage information. This organized structure improves efficiency and saves time searching for specific data within a dataset.
- Improved Data Security: Data classification helps in identifying sensitive or confidential information within a dataset. Organizations can implement appropriate security measures to protect valuable data by classifying data based on its sensitivity level. It includes setting access controls, encryption, and data handling protocols, reducing the risk of data breaches and unauthorized access.
- Efficient Data Analysis: Classifying data allows for more focused and targeted analysis. By categorizing data into meaningful groups, patterns, trends, and insights can be derived more easily. Analysts can perform specific analyses on each category, enabling better decision-making and uncovering valuable insights that might have remained hidden in unstructured or unclassified data.
- Regulatory Compliance: Data classification assists organizations in complying with regulatory requirements. Specific industries like healthcare or finance have strict data handling regulations. Classifying data based on regulatory guidelines ensures compliance and facilitates the implementation of appropriate security measures, retention policies, and data handling procedures.
Career Transition






Example of Data Classification
Let’s find out an example of data classification by considering a scenario where you manage an e-commerce company’s customer database.
You have a Google Sheets spreadsheet containing customer information, such as names, email addresses, and purchase history. You classify the data based on customer types to ensure data consistency and accuracy.
Here is an example of data classification using Google Sheets with data validation:
- Open a new Google Sheets document and create a table with columns for customer name, email address, and purchase history.
- In the next column, create a new column header called “Customer Type.”
- Select the first cell under “Customer Type” (e.g., cell D2) and click on “Data” in the menu at the top.
- From the drop-down menu, select “Data validation.”
- In the “Data validation” window, choose “List of items” from the “Criteria” section.
- Enter the customer types you want to classify in the “List of items” field. For example, you could have “Regular,” “VIP,” and “Wholesale.”
- Optionally, you can check the “Show drop-down list in cell” box to create a drop-down menu for selecting the customer type.
- Click “Save” to apply the data validation to the selected cell.
- Now, whenever you need to classify a customer, you can simply select the appropriate customer type from the “Customer Type” drop-down menu.
Data validation ensures that only specific values (customer types) can be selected in the “Customer Type” column, thereby classifying the customers accordingly. This classification enables you to segment your customers and perform targeted analysis or marketing strategies based on their type.
Challenges in Data Classification
One of the challenges of Data classification is the lack of a standardized classification system. Different organizations may use different classification categories, making it difficult to share data between organizations. The constant evolution of data is another challenge. As new types of data emerge, classification criteria may need to be updated to reflect these changes.
- Lack of Clear Guidelines
One of the most significant challenges in data classification is the lack of clear guidelines or standard procedures to follow. Different organizations have different data classification criteria, which can result in inconsistent classification across departments or even within the same department. This can lead to confusion and errors in the classification process, affecting the quality and usefulness of the data.
- Incomplete or Inaccurate Data
Data classification is only as good as the data it is based on. Incomplete or inaccurate data can lead to incorrect classification, making the process of informed decisions challenging the accuracy of data classification relies heavily on the quality of data, which can be affected by various factors, such as data collection methods, data storage, and data management practices.
- Evolving Data Types
The rapid evolution of data types, particularly unstructured data, poses a significant challenge in data classification. The traditional methods of data classification may not be effective in categorizing the vast amounts of unstructured data generated daily. Unstructured data, such as emails, social media posts, and images, can be difficult to classify since they lack a standard structure, making it hard to apply consistent classification criteria.
- Human Error
Data classification is a complex process that requires a considerable amount of human input. Human error, such as typos, incorrect categorization, and inconsistent application of classification criteria, can lead to incorrect data classification, making it difficult to make informed decisions. However, clear and concise guidelines, training, and carefully assigning tasks can minimize the risk of human error.
- Cost and Resource-Intensive
Data classification can be a time-consuming and resource-intensive process. It requires a considerable amount of resources, such as personnel, technology, and infrastructure, which can be expensive for organizations, especially for small and medium-sized businesses. The cost and resource requirements of data classification can deter organizations from implementing effective data classification strategies.
- Lack of Awareness
Lack of awareness or understanding of data classification can be a significant challenge for organizations. Many businesses do not fully understand the benefits of data classification, leading to underinvestment in the process. This can result in suboptimal data management practices, compromising the quality and usefulness of data.
Courses you may like
Conclusion
Proper data classification is crucial for efficient data management and protection. It allows for easier data retrieval and protects sensitive information from unauthorized access. However, the challenges, such as the lack of a standardized classification system, the constant evolution of data, and the risk of human error, can impact the data. Therefore, it’s essential to be careful while classifying the data.
If you have any questions, ask them in our Cyber Security Community.
The post What is Data Classification? appeared first on Intellipaat Blog.
Blog: Intellipaat - Blog
Leave a Comment
You must be logged in to post a comment.






