
What is AWS Data Lake?
A data lake is a versatile, low-cost data repository that can hold massive amounts of structured and unstructured data. Organizations can use it to keep data in its original form, search for it, analyze it, and then change it as necessary on an as-needed basis.
In this article, we will be discussing the below-mentioned aspects of AWS Data Lake:
- What is Data Lake?
- Why build Data Lake on Amazon S3?
- AWS Data Lake Architecture
- AWS Data Lake best practices
- What is AWS Lake Formation?
- Conclusion
Check out this AWS Training video by Intellipaat
What is Data Lake?
A data lake is a centralized location where both organized and unstructured data are stored. It is a site where we may store and manage all types of files, independent of their source, scale, or format, to do analysis, visualization, and processing in accordance with the organization’s goals.
To give you an example, Data Lake is utilized for Big Data Analytics projects in a variety of industries, ranging from public health to R&D, as well as in many business domains such as market segmentation, marketing, Sales, and HR, where Business Analytics solutions are critical.
When employing a data lake, all data is retained; none is deleted or filtered before storage. The data could be analyzed immediately, later, or never at all. It could also be reused numerous times for multiple purposes, as opposed to when data has been polished for a certain purpose, making it difficult to reuse data in a new way.
Why build Data Lake on Amazon S3?
Amazon S3 is built for data durability of 99.999999999%. With that level of durability, you should only expect to lose one object every 10,000 years if you save 10,000,000 objects in Amazon S3. All uploaded S3 items are automatically copied and stored across many systems by the service. This ensures that your data is always available and safe from failures, faults, and threats.
Other features include:
- Security by design
- Scalability on demand
- Durable
- Integration with 3rd party service providers
- Vast data management features
AWS Data Lake Architecture
A data lake is an architecture pattern, not a specific platform, that is constructed around a large data store that employs a schema-on-read approach. In Amazon data lake, you store vast amounts of unstructured data in object storage, such as Amazon S3, without pre-structuring the data but with the option to do future ETL and ELT on the data.
As a result, it is perfect for enterprises that require the analysis of constantly changing data or very huge datasets.
While there are numerous different data lake architectures, Amazon provides a standard architecture that includes the following features:
- Stores datasets in their original form, regardless of size, on Amazon S3
- Ad hoc modifications and analyses are performed using AWS Glue and Amazon Athena
- Stores user-defined tags in Amazon DynamoDB to contextualize datasets, allowing governance policies to be applied and datasets to be browsed by their metadata
- Federated templates are used to establish a data lake that is pre-integrated with current SAML providers such as Okta or Active Directory
The architecture is composed of 3 major components:
- Landing zone – ingests raw data from various sources both inside and outside the business There is no data modeling or transformation.
- Curation zone – This is the stage at which you do extract-transform-load (ETL), crawl data to recognize its structure and value, add metadata, and employ modeling approaches.
- Production zone – contains processed data that is ready to be used by business apps or direct by analysts or data scientists
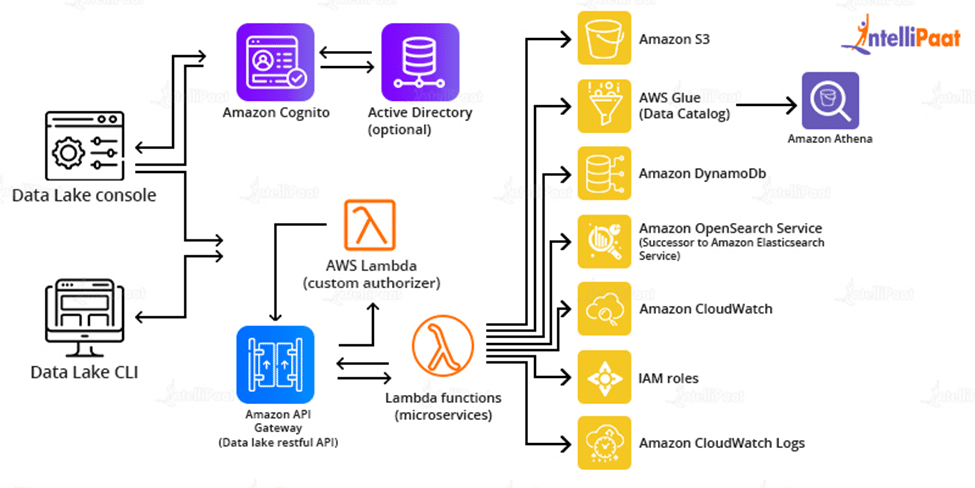
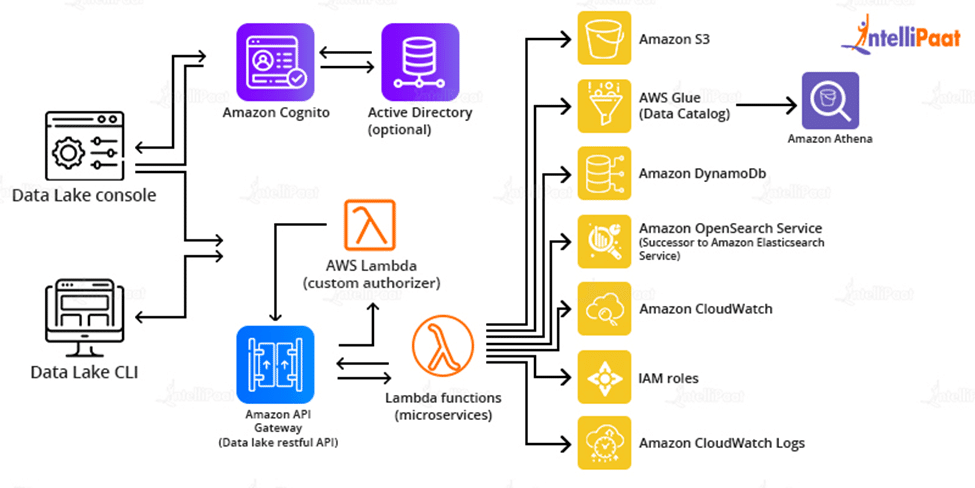
Steps for deploying reference architecture-
- For deployment of infrastructure components, AWS CloudFormation is used
- For creating data packages, ingestion of data, creating manifest and performing administrative tasks API Gateway and Lambda functions are used.
- The core microservices store, manage, and audit data using Amazon S3, Glue, Athena, DynamoDB, Elasticsearch Service, and CloudWatch.
- The CloudFormation template creates a data lake console in an Amazon S3 bucket, with Amazon CloudFront serving as the access point. After that, it establishes an administrator account and emails you an invitation.
Amazon offers many ready-made templates to easily deploy this architecture in Amazon accounts.
Check out Intellipaat’s best AWS training to get ahead in your career!
Career Transition





AWS Data Lake best practices
Let’s discuss some of the best practices that will help you optimize your AWS data lake, and help in reducing costs, decreasing time-to-insights, and getting the most value from your Amazon Data Lake deployment:
Ingestion
Amazon suggests absorbing and storing data in the original format. Any data transformation should be saved to another S3 bucket, allowing you to return to the original data and analyze it in new ways.
Although this is a wise practice, a lot of outdated data will be kept in S3. You should define when this data should be moved to an archive storage tier, such as Amazon Glacier, using object lifecycle policies. This saves money while still allowing you to access the data as needed.
Organization
Consider organization right from the start of a data lake project:
- Data must be organized in partitions in various S3 buckets
- Keys must be generated for each partition that will help in identifying them with common queries
- Partitioning buckets in day/month/year format is recommended in absence of any good organizational structure
Preparation
For various forms of data, treatment and processing should be handled differently:
- Use redshift or Apache HBase for changing data dynamically
- Immutable data can be stored in S3 for performing transformations and analysis
- Use Kinesis to stream data, Apache Flink to process it, and S3 to store the output for quick ingestion.
Interested in learning more? Go through this AWS Tutorial!
What is AWS Lake Formation?
Amazon offers AWS Lake Formation to let you personalize your deployment and enable ongoing data management.
Lake Formation is a completely managed service that simplifies the creation, protection, and management of your data lake. It streamlines the complex manual tasks that are generally required to construct a data lake, such as:
- Collecting data
- Moving data to the data lake
- Organizing data
- Cleansing data
- Making sure data is secure
To build a data lake, Lake Formation scans data sources and automatically puts data into Amazon Simple Storage Service (Amazon S3).
How is Lake Formation Related to Other AWS Services?
Lake Formation handles the following functions, either directly or indirectly via other AWS services such as AWS Glue, S3, and AWS database services:
- S3 routes and buckets are registered for your data.
- Creates data flows to consume and process raw data as needed.
- Produces data catalogs including metadata about your data sources.
- A rights/revocation approach is used to define data access policies for both metadata and actual data.
After data is placed in the data lake, end users can access and work with the data using their preferred analytics solution, such as Amazon Athena, Redshift, or EMR.
Courses you may like
Conclusion
Data lakes enable you to break down barriers, employ a variety of analytics services to gain the most information from your data, and cost-effectively expand your storage and data processing demands over time by keeping data in a uniform repository in open standards-based data formats.
A data lake on AWS provides access to the most comprehensive big data platform. AWS delivers secure infrastructure as well as a wide range of scalable, cost-effective services for collecting, storing, categorizing, and analyzing data to gain useful insights.
AWS makes it simple to construct and customize a data lake to meet your unique data analytic needs. You can get started by using one of the available Quick Starts or by leveraging the skills and knowledge of an APN partner to implement one for you. A data lake can contain both organized and unstructured data.
Enroll today in our AWS Certification Master’s Course to speed up your career!
The post What is AWS Data Lake? appeared first on Intellipaat Blog.
Blog: Intellipaat - Blog
Leave a Comment
You must be logged in to post a comment.






