
What are Machine Learning Models?: Definition, Types & How to Build
In this in-depth guide, we’ll closely examine the true nature of machine learning models, explore the various kinds they come in, understand how to build them, and also discuss the advantages and difficulties they bring.
Here are the following topics we are going to discuss:
- What is a Machine Learning Model?
- Types of Machine Learning Models
- How to Build a Machine Learning Model?
- Benefits of Machine Learning Model
- Challenges of Machine Learning Model along with Potential Solutions
- Future Trends in Machine Learning Models
- Conclusion
Watch this complete course video on Machine Learning
{
“@context”: “https://schema.org”,
“@type”: “VideoObject”,
“name”: “What is Machine Learning | Machine Learning | Intellipaat”,
“description”: “What are Machine Learning Models?: Definition, Types & How to Build”,
“thumbnailUrl”: “https://img.youtube.com/vi/MaTrmz3dqRU/hqdefault.jpg”,
“uploadDate”: “2023-08-29T08:00:00+08:00”,
“publisher”: {
“@type”: “Organization”,
“name”: “Intellipaat Software Solutions Pvt Ltd”,
“logo”: {
“@type”: “ImageObject”,
“url”: “https://intellipaat.com/blog/wp-content/themes/intellipaat-blog-new/images/logo.png”,
“width”: 124,
“height”: 43
}
},
“embedUrl”: “https://www.youtube.com/embed/MaTrmz3dqRU”
}
What is a Machine Learning Model?
A machine learning model is a computer program that learns patterns from data, allowing it to make predictions or decisions. It’s like a digital brain that recognizes relationships in information and becomes smarter as it encounters more examples. Unlike traditional software, these models adjust themselves without explicit programming, adapting to new information and improving their performance over time.
At its core, a machine learning model uses algorithms to find meaningful patterns within a dataset. These patterns might involve correlations, trends, or associations that are not immediately apparent to humans. By analyzing and learning from these patterns, the model gains the ability to generalize and make predictions about new, unseen data.
Are you interested in learning about Machine Learning? Enroll in our machine learning certification course!
Types of Machine Learning Models
There are various kinds of machine learning models, each designed to address specific tasks and difficulties. Here are some of the primary types of machine learning models:
- Supervised Learning Models
- Unsupervised Learning Models
- Semi-Supervised Learning Models
- Reinforcement Learning Models
To begin, let’s explore the significant role played by supervised learning models within the field of machine learning.
Supervised Learning Models
Supervised learning involves a machine learning algorithm learning from data that is labeled. This means the data has input features and corresponding known outcomes. The model trains on this data to establish relationships between inputs and outputs. Once trained, it can make predictions based on new, unseen data. For instance, in a classification task, it can determine whether an email is spam or not. Linear regression and decision trees are common examples. The model’s accuracy improves as it encounters more labeled examples, allowing it to generalize and make accurate predictions on similar data.
Supervised Learning is further divided into two categories:
- Classification
In the context of supervised learning, classification is a crucial technique. It involves training a machine learning model to categorize input data into predefined classes based on labeled examples. This means the model learns from data where each input is associated with a known output category. The goal is for the model to accurately predict the correct category for new, unseen data.
Classification is used in a wide range of applications, such as identifying whether an email is spam or not, classifying images of objects or animals, and diagnosing medical conditions based on patient data. The model’s accuracy improves as it learns from more labeled examples, allowing it to generalize and make accurate predictions on similar data points.
Below are several renowned classification algorithms that find extensive application in real-world situations:
K-Nearest Neighbors (KNN): It is a supervised machine learning algorithm used for classification tasks. It’s a simple and intuitive algorithm that operates based on the principle of similarity between data points. In KNN, the idea is that similar data points tend to have similar labels or outcomes.
Logistic Regression: Logistic Regression functions as a classification technique that estimates the likelihood of an input being associated with a particular category. In situations involving binary classification, where the choices are limited to two potential results (such as Yes or No, 1 or 0), Logistic Regression employs the numerical values of 0 and 1 to symbolize these respective outcomes.
Support Vector Machines (SVM): Support Vector Machines (SVM) are a powerful machine learning algorithm used for classification and regression tasks. SVMs excel at finding the optimal boundary, called the hyperplane, that best separates data points of different classes.
Naive Bayes: Naive Bayes is a probabilistic machine learning algorithm commonly used for classification tasks, especially in natural language processing and text analysis. It’s based on Bayes’ theorem and makes predictions by calculating the probability of a data point belonging to a certain class.
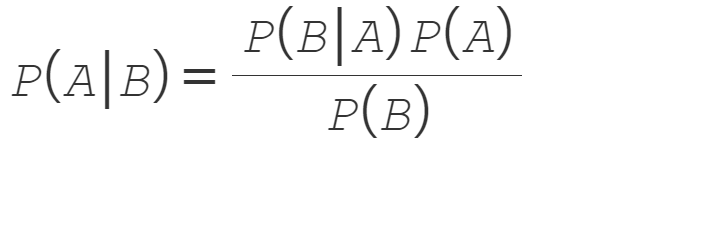
Now we will look into another type of Supervised Learning Model that is quite famous in the machine learning domain.
- Regression
Regression in machine learning is a predictive modeling technique used to estimate continuous numerical values based on input features. It’s a type of supervised learning where the goal is to create a mathematical function that can map input data to a continuous output range.
Some commonly used Regression models are as follows:
Linear Regression: Linear regression stands as the most basic machine learning model, aiming to forecast an output variable with the help of one or more input variables. The depiction of linear regression involves an equation that takes a group of input values (x) and provides a projected output (y) for those inputs. This equation adopts a linear form, typically appearing as a straight line: y=a+bx
Decision Trees: Decision Trees are versatile classification algorithms in machine learning used for both classification and regression tasks. They represent a tree-like structure where each internal node denotes a decision based on input features, and each leaf node represents an outcome or a prediction.
Neural Networks: Neural Networks, often referred to as artificial neural networks (ANNs), are a sophisticated class of machine learning models inspired by the structure and functioning of the human brain. These networks consist of interconnected nodes, also known as neurons or units, organized in layers.
Random Forest: Random Forests are highly robust and perform well on a wide range of problems. They are particularly effective in handling complex data relationships and mitigating the overfitting issues commonly associated with individual Decision Trees. Their ensemble nature allows them to capture a broader range of patterns present in the data.
Interested in learning about machine learning, but don’t know where to start? Check out our blog on Prerequisites for Learning Machine Learning.
Unsupervised Learning Models
Unsupervised learning models are a category of machine learning algorithms that deal with data where the target variable (output) is not explicitly provided. Instead, the goal is to find patterns, relationships, or structures within the data itself. Unsupervised learning is commonly used for tasks like clustering and dimensionality reduction.
- Clustering
Clustering is a type of unsupervised machine-learning technique that involves grouping similar data points together into clusters or groups. The goal of clustering is to locate patterns, structures, or natural divisions within a dataset without using any predefined labels or target variables. Clustering is commonly used for data exploration, segmentation, and pattern recognition.
- Dimensionality Reduction
Dimensionality reduction techniques are used to reduce the number of features or dimensions in a dataset while retaining the most important information. This can help in visualizing and understanding high-dimensional data and can also reduce the complexity of subsequent modeling.
Semi-Supervised Learning Models
Semi-supervised learning is a machine learning model that involves training a model using both labeled and unlabeled data. The idea behind semi-supervised learning is that the combination of labeled examples (where the correct output is known) and unlabeled examples can lead to improved model performance compared to using only labeled data. This approach is especially useful when obtaining a large amount of labeled data is costly or time-consuming.
Reinforcement Learning Models
Reinforcement Learning (RL) is a subfield of machine learning that focuses on developing algorithms and models that enable agents to learn how to make decisions and take actions in an environment to maximize a reward signal. In RL, an agent interacts with an environment, and through a process of trial and error, it learns to optimize its actions to achieve its goals.
Some of the popular reinforcement learning algorithms are:
- Q-Learning: A model-free algorithm that learns action values for an agent’s policy by iteratively updating Q-values based on the Bellman equation.
- Deep Q-Networks (DQN): Combines Q-learning with deep neural networks to handle high-dimensional state spaces, making it suitable for complex environments.
- SARSA (State-Action-Reward-State-Action): A model-free algorithm similar to Q-learning that updates Q-values based on the next action the agent would take.
Go through our Machine Learning Tutorial to get a better knowledge of the topic.
How to Build a Machine Learning Model
Building a machine learning model involves several steps, from understanding the problem and data to training, evaluation, and deployment. Here’s a general outline of the process:
Step 1: Define the Problem
Clearly define the problem you want to solve. Is it a classification, regression, clustering, or other type of problem?
Step 2: Gather and Prepare Data
Collect and curate the data needed for your problem. This might involve data collection, data cleaning, data transformation, and dealing with missing values.
Step 3: Data Exploration and Analysis
Understand the characteristics of your data through Exploratory Data Analysis (EDA). Visualize data distributions, correlations, and anomalies.
Step 4: Feature Engineering
Identify relevant features (input variables) that can help the model learn patterns from the data. This might involve creating new features, selecting important ones, and normalizing or scaling data.
Step 5: Data Splitting
Divide your dataset into training, validation, and testing sets. The training set is used to train the model, the validation set helps tune hyperparameters, and the testing set evaluates the final model’s performance.
Step 6: Choose a Model
Based on the problem type, choose a suitable machine learning algorithm (e.g., linear regression, random forests, neural networks, etc.).
Step 7: Model Design and Training
Design the architecture of your model (if using deep learning) or configure hyperparameters (if using other algorithms). Train the model using the training data. This involves updating model parameters to minimize a loss function.
Step 8: Validation and Hyperparameter Tuning
Tune hyperparameters using the validation set to improve the model’s performance. This can involve grid search, random search, or more advanced optimization techniques.
Step 9: Model Evaluation
Evaluate the model’s performance using the testing set. Common evaluation metrics vary based on the problem type (accuracy, precision, recall, F1-score, Mean Squared Error, etc.).
Step 10: Iterate and Refine
Based on the evaluation results, adjust your approach, model architecture, or feature engineering strategy. This might involve going back to previous steps.
Step 11: Final Model Training
Train a final model using the entire labeled dataset (training + validation) if you’re satisfied with its performance.
Step 12: Model Deployment
If your model is ready for production use, deploy it to a production environment. This might involve integrating it into a web application, API, or other system.
Step 13: Monitoring and Maintenance
Continuously monitor the model’s performance in the real world and retrain it periodically to account for changes in data distribution.
Step 14: Ethical Considerations and Bias
Be aware of potential biases in your data and model predictions. Address any ethical concerns and strive for fairness.
Step 15: Documentation
Document the entire process, from data collection to deployment. This documentation is crucial for understanding, reproducing, and maintaining your work.
Benefits of Machine Learning Model
Machine learning models offer a wide range of benefits across various domains. Some key advantages of using machine learning models include:
- Automation: Machine learning models can automate complex tasks and processes, reducing the need for manual intervention and speeding up decision-making.
- Data-Driven Insights: ML models can uncover valuable insights and patterns in large datasets that might be difficult for humans to discern, leading to better understanding and informed decision-making.
- Accuracy and Consistency: Well-trained machine learning models can achieve high levels of accuracy and consistency in tasks that require precision, reducing errors and variability.
- Scalability: Once trained, machine learning models can handle large volumes of data and perform tasks at scale without a proportional increase in human effort.
Go through these Top 40 Machine Learning Interview Questions and Answers to crack your interviews.
Challenges of Machine Learning Model along with Potential Solutions
Let us explore some common challenges associated with machine learning models, along with potential solutions:
Poor Data Quality and Quantity
Challenge
- Poor-quality data can lead to inaccurate models.
Solutions
- Remove or correct noisy or erroneous data points.
- Generate additional data through techniques like rotation, flipping, or adding noise.
- Collect more diverse and representative data to improve model generalization.
Overfitting and Underfitting
Challenge
- Models might fail to generalize to new data due to overfitting or underfitting.
Solutions
- Use techniques like k-fold cross-validation to evaluate model performance on different subsets of data.
- Apply techniques like L1 or L2 regularization to penalize large model weights and prevent overfitting.
Ethical and Bias Concerns
Challenge
- Models may unintentionally reinforce biases or violate ethical norms.
Solution
- Analyze model predictions for biases based on sensitive attributes.
- Oversample or undersample to balance class representation and mitigate bias.
Lack of Generalization
Challenge
- Models might struggle to generalize to new datasets or scenarios.
Solution
- Use pre-trained models and perform fine-tuning for your specific task.
- Generate diverse training examples by applying transformations to the data.
Career Transition







Future Trends in Machine Learning Models
Machine learning is an ever-evolving field, and it’s being influenced by numerous upcoming trends that are shaping the progression of machine learning models. Below are several noteworthy trends to keep an eye on:
Zero-Shot and Few-Shot Learning
Models capable of learning from very few examples (few-shot learning) or even without any examples (zero-shot learning) will enable AI systems to generalize better from limited data.
Generative Adversarial Networks (GANs) and Creative AI
GANs and similar models are advancing creativity in AI, enabling the generation of realistic images, videos, music, and other forms of creative content.
Explainable AI (XAI)
As AI models become more complex, the need for interpretability is growing. Future models will likely focus on providing clear explanations for their decisions, enabling better understanding and trust in AI systems.
Continual and Lifelong Learning
Models that can learn incrementally over time without forgetting previous knowledge are gaining importance. Lifelong learning models can adapt to new data distributions and tasks while retaining knowledge learned previously.
Conclusion
Machine learning models have seen incredible growth and change, completely changing how we interact with technology and data. These models have established themselves in a number of industries, including healthcare and finance, where they have improved decision-making, automated procedures, and unlocked previously unattainable insights. The journey of machine learning models is destined to be a crucial part of the ongoing story of human progress, and the future holds tremendous potential.
Come to Intellipaat’s Machine Learning Community if you have more queries on Machine Learning!
The post What are Machine Learning Models?: Definition, Types & How to Build appeared first on Intellipaat Blog.
Blog: Intellipaat - Blog
Leave a Comment
You must be logged in to post a comment.






