
Loss Functions in Deep Learning
Before diving into the various types of loss functions utilized in deep learning, it’s essential to understand the fundamental question of why we even need loss functions in the first place. In this comprehensive guide, we will delve deep into the world of loss functions in deep learning, exploring their types, significance, and real-world applications.
Given below are the following topics we are going to cover:
- What is Loss Function in Deep Learning?
- Importance of Loss Function in Deep Learning
- Types of Loss Functions
- How to Implement Loss Function in Deep Learning?
- Benefits of Loss Functions
- Conclusion
Watch this Data Science Tutorial:
{
“@context”: “https://schema.org”,
“@type”: “VideoObject”,
“name”: “Data Science Course | Data Science Training | Data Science Tutorial for Beginners | Intellipaat”,
“description”: “Loss Functions in Deep Learning”,
“thumbnailUrl”: “https://img.youtube.com/vi/osHjb7QhgWk/hqdefault.jpg”,
“uploadDate”: “2023-09-13T08:00:00+08:00”,
“publisher”: {
“@type”: “Organization”,
“name”: “Intellipaat Software Solutions Pvt Ltd”,
“logo”: {
“@type”: “ImageObject”,
“url”: “https://intellipaat.com/blog/wp-content/themes/intellipaat-blog-new/images/logo.png”,
“width”: 124,
“height”: 43
}
},
“embedUrl”: “https://www.youtube.com/embed/osHjb7QhgWk”
}
What is Loss Function in Deep Learning?
In deep learning, a loss function, also known as a cost or objective function, is a crucial component that quantifies the dissimilarity between the predicted outputs generated by a neural network and the actual target values in a given dataset. The primary purpose of a loss function is to serve as a measure of how well or poorly the model is performing on a specific task.
It provides a numerical value that represents the error or deviation between predictions and the ground truth. The ultimate goal during the training process is to minimize this loss function by iteratively adjusting the model’s parameters, ensuring that the neural network becomes increasingly accurate in making predictions.
Different types of loss functions are employed depending on the nature of the problem, such as mean squared error for regression or cross-entropy loss for classification, and the choice of the appropriate loss function is pivotal in achieving successful model training and accurate predictions.
Enroll in Intellipaat’s Data Science Certification Course and make your career in data science!
Importance of Loss Function in Deep Learning
The importance of loss functions in deep learning cannot be overstated. They serve as the backbone of the training process and play a central role in the success of neural network models for several reasons:
- Quantifying Model Performance: Loss functions provide a concrete measure of how well a deep learning model is performing on a given task. They take the difference between predicted and actual values and convert it into a single numerical value, making it easy to assess the model’s accuracy and progress during training.
- Guiding Model Optimization: The primary goal during training is to minimize the loss function. By continually adjusting the model’s parameters in the direction that reduces the loss, the neural network learns to make more accurate predictions. This optimization process, often done through gradient descent, ensures that the model converges to a state where it performs well on the task.
- Customization for Task Complexity: Deep learning is applied to a wide range of tasks, from image recognition to natural language processing. Different tasks have different characteristics, and loss functions can be tailored to suit these specifics. This adaptability allows deep learning models to excel in diverse domains.
- Handling Various Data Types: Loss functions are designed to accommodate various data types, including continuous values for regression problems and discrete categories for classification tasks. The appropriate choice of loss function ensures that the model’s predictions align with the nature of the target variable.
Check out our blog on data science tutorial to learn more about it.
Types of Loss Functions
Here are some common types of loss functions, categorized into three main groups: regression loss functions, binary classification loss functions, and multi-class classification loss functions.
Regression Loss Function
A regression loss function is a mathematical function used to quantify the error or discrepancy between the predicted values generated by a regression model and the actual observed values (or target values) in a dataset. The primary purpose of a regression loss function is to measure how well the model’s predictions align with the true data points. This function is also divided into further parts:
Mean Squared Error (MSE)
Mean Squared Error (MSE) is one of the most commonly used loss functions in regression analysis and machine learning. It is used to measure the average squared difference between the estimated values generated by a regression model and the actual observed values (target values) in a dataset.
The formula for Mean Squared Error (MSE) is as follows:
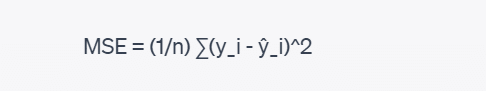
Where:
- n is the total number of data points in the dataset.
- y_i represents the actual target value for the ith data point.
- ŷ_i represents the predicted value for the ith data point generated by the regression model.
Benefits
- Differentiability
- Mathematical Simplicity
- Emphasis on Large Errors
Drawbacks
- Sensitivity to Outliers
- Scale Dependency
- Loss of Interpretability
Mean Absolute Error (MAE)
Mean Absolute Error (MAE) is a frequently used loss function in regression analysis and machine learning. It is used to measure the average absolute difference between the predicted values generated by a regression model and the actual observed values (target values) in a dataset.
The formula for Mean Absolute Error (MAE) is as follows:
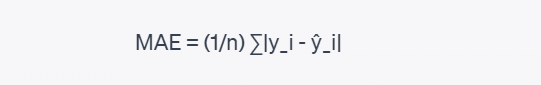
Where:
- n is the total number of data points in the dataset.
- y_i represents the actual target value for the ith data point.
- ŷ_i represents the predicted value for the ith data point generated by the regression model.
Benefits
- Robustness to Outliers
- Balanced Error Metric
- No Need for Assumptions
Drawbacks
- Lack of Sensitivity to Small Errors
- Impact on Model Complexity
- Equal Treatment of All Errors
Huber Loss
Huber loss combines MSE for small errors and MAE for large errors. It introduces a hyperparameter δ that defines the point at which the loss function transitions between being quadratic and linear, making it more robust to outliers.
The formula for Huber Loss is as follows:
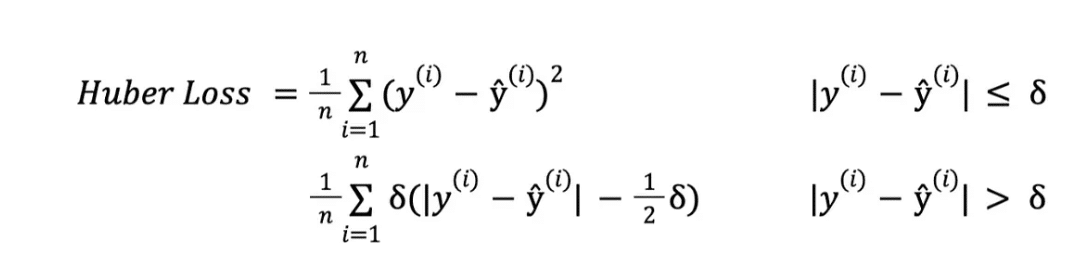
Where:
- n represents the quantity of data points within the dataset.
- y signifies the factual or true value associated with each data point.
- ŷ denotes the anticipated or model-generated value for each data point.
- δ determines the threshold at which the Huber loss function shifts from being quadratic to linear.
Benefits
- Smooth Transition
- Tunable Hyperparameter
- Balanced Error Treatment
Drawbacks
- Complexity of Implementation
- Hyperparameter Dependency
- Less intuitive to interpret
Quantile Loss
Quantile loss finds its application in quantile regression, a technique employed when the goal is to estimate a particular quantile, such as the median, from the distribution of the target variable. This method enables the modeling of diverse quantiles within the dataset.
The formula for Quantile Loss is as follows:

Where:
- α is the quantile level of interest. It’s a value between 0 and 1, where α = 0.5 corresponds to estimating the median, α 0.5 corresponds to estimating upper quantiles.
- y_i represents the actual target value (observed value) for the ith data point.
- ŷ_i represents the predicted value generated by the quantile regression model for the ith data point.
- |y_i – ŷ_i| represents the absolute difference between the actual and predicted values.
- I(y_i – ŷ_i < 0) is an indicator function that equals 1 if y_i – ŷ_i is less than 0 (indicating an underestimation) and 0 otherwise.
Benefits
- Flexibility in Quantile Estimation
- Tail Behavior Analysis
- Statistical Inference
Drawbacks
- Non-Convex Optimization
- Larger Data Requirement
- Increased Model Complexity
Log-Cosh Loss
Log-Cosh loss is less sensitive to outliers than MSE. It is a smooth approximation of the Huber loss and can be useful when you want a balance between the robustness of Huber and the differentiability of MSE.
The formula for Log-Cosh Loss is as follows:
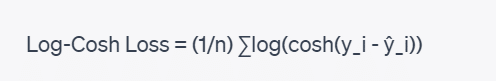
Where:
- n is the total number of data points in the dataset.
- y_i represents the actual target value for the ith data point.
- ŷ_i represents the predicted value for the ith data point generated by the regression model.
- cosh(x) is the hyperbolic cosine function, defined as (e^x + e^(-x))/2.
- log(x) is the natural logarithm function.
Benefits
- Smoothness and Differentiability
- Sensitive to the magnitude of errors
- Approximation to Huber Loss
Drawbacks
- Less Interpretability
- Computational Cost
- Less sensitive
Binary Classification Loss Functions
Binary classification is a type of supervised learning problem where the goal is to categorize data into one of two classes or categories, typically denoted as 0 (negative or “no”) and 1 (positive or “yes”). In binary classification, various loss functions can be used to measure the difference between the predicted class probabilities and the actual class labels. Let us explore each of them in detail:
Binary Cross-Entropy Loss (Log Loss)
The Binary Cross-Entropy Loss, also known as the Log Loss, is a common loss function used in binary classification tasks. It measures the dissimilarity between predicted probabilities and actual binary labels.
The formula for Binary Cross-Entropy Loss is as follows:
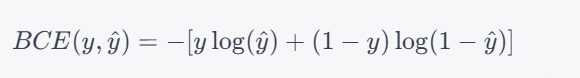
Where:
- y is the actual binary label, which can be either 0 or 1.
- ŷ is the predicted probability that the given data point belongs to the positive class (class 1).
Benefits
- Optimal for Maximum Likelihood Estimation
- Continuous and Smooth
- Sensitivity to Probabilities
Drawbacks
- Non-Convex Nature
- Imbalanced Classes
- Hard Thresholds
Hinge Loss (SVM Loss)
Hinge Loss, also known as SVM (Support Vector Machine) Loss, is a loss function commonly used in support vector machines and related classification algorithms. It is particularly suitable for linear classifiers and aims to maximize the margin of separation between classes.
The formula for Hinge Loss (SVM Loss) is as follows:
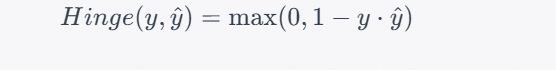
Where:
- Hinge(y, ŷ ) represents the Hinge Loss.
- y is the actual binary label, which can be either -1 (negative class) or 1 (positive class).
- ŷ is the raw decision value or score assigned by the classifier for a data point. It is not a probability.
- The formula calculates the loss for each data point and returns the maximum of 0 and 1 – y . ŷ
Benefits
- Effective for Linear Separability
- Margin Emphasis
- Sparsity of Support Vectors
Drawbacks
- Requirement of Linear Separability
- Noisy Data Sensitivity
- Non-Differentiability at the Margin
Zero-One Loss (Classification Error)
Zero-one loss counts the number of misclassified examples and assigns a value of 0 for correct classifications and 1 for incorrect classifications.
The formula for Zero-One Loss is as follows:
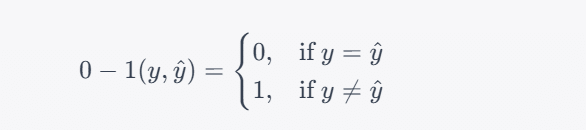
Where:
- 0 – 1 (y, ŷ) represents the Zero-One Loss.
- y is the actual binary label (0 or 1) for a data point.
- ŷ is the predicted binary label (0 or 1) for the same data point.
Benefits
- Simplicity
- Threshold-Free
- Interpretability
Drawbacks
- Insensitive to Probability Estimates
- Not Sensitive to the Magnitude of Errors
- Not Suitable for Optimization
Multi-class Classification Loss Functions
Multi-class classification involves classifying data into one of several distinct classes or categories. Unlike binary classification, where there are only two classes, multi-class classification has more than two possible outcomes. Various loss functions are used in multi-class classification to measure the difference between predicted class probabilities and the actual class labels. This function can be further subdivided or broken down into various components:
Categorical Cross-Entropy
Categorical Cross-Entropy, often simply referred to as Cross-entropy, is a widely used loss function in multi-class classification tasks. It measures the dissimilarity between estimated class probabilities and the true class labels in a categorical setting, where each data point belongs to one of multiple classes.
The formula for Categorical Cross-Entropy Loss is as follows:
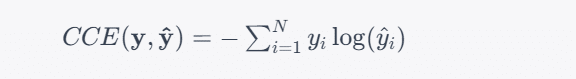
Where:
- CCE(y, ŷ ) represents the Categorical Cross-Entropy Loss.
- y is a one-hot encoded vector representing the true class labels. Each element of y is 0 except for the element corresponding to the true class, which is 1.
- ŷ is a vector representing the predicted class probabilities for a data point.
Benefits
- Focus on Misclassifications
- Differentiability
- Probabilistic Interpretation
Drawbacks
- Requires Well-Calibrated Probabilities
- Not Suitable for Imbalanced Data
- Sensitive to extreme predicted probabilities
Kullback-Leibler Divergence (KL Divergence) Loss
Kullback-Leibler Divergence (KL Divergence) Loss, also known as KL Loss, is a mathematical measure used in machine learning and statistics to quantify the difference between two probability distributions. In the context of loss functions, KL divergence loss is often utilized in tasks where you want to compare or match two probability distributions, such as generative modeling or variational autoencoders.
The formula for Kullback-Leibler Divergence (KL Divergence) Loss is as follows:
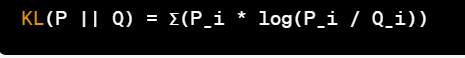
Where:
- KL(P || Q): This represents the KL divergence from distribution P to distribution Q. It measures how distribution Q differs from the reference distribution P.
- Σ: This symbol denotes a summation, typically taken over all possible events or outcomes.
- P_i and Q_i: These are the probabilities of event i occurring in the distributions P and Q, respectively.
- log(P_i / Q_i): This term computes the logarithm of the ratio of the probabilities of event i occurring in the two distributions. It quantifies how much more or less likely event i is in distribution P compared to distribution Q.
Benefits
- Information Measure
- Regularization
- Interpretable
Drawbacks
- Non-Symmetric
- Not a True Distance Metric
- Expensive Computational Cost
Sparse Multiclass Cross-Entropy Loss
Sparse Multiclass Cross-Entropy Loss, often referred to as Sparse Categorical Cross-Entropy Loss, is a loss function commonly used in multi-class classification problems where the class labels are integers rather than one-hot encoded vectors. This loss function is suitable when each data point belongs to one and only one class.
The Sparse Multiclass Cross-Entropy Loss formula for a single data point is:

Where:
- Loss: This is the value of the loss function for the given data point.
- ŷ_y: This represents the predicted probability for the true class y.
Benefits
- Effective for Single-Label Classification
- Ease of Use
- Compatibility with Softmax Activation
Drawbacks
- Lack of Flexibility
- Not Suitable for Anomaly Detection
- Sensitivity to Outliers
Prepare for interviews with this guide to data science interview questions!
Career Transition





How to Implement Loss Function in Deep Learning?
Implementing a custom loss function in deep learning involves several steps, regardless of whether you’re using TensorFlow, PyTorch, or any other deep learning framework. Here’s a step-by-step guide with code examples using TensorFlow and PyTorch:
Step 1: Choose a Suitable Loss Function:
- Determine the type of problem you’re working on (e.g., regression, binary classification, multiclass classification) and choose a loss function appropriate for that problem. You can also design a custom loss function tailored to your specific needs.
Step 2: Define the Loss Function Class (PyTorch) or Function (TensorFlow):
- In PyTorch, define a custom loss function class by subclassing nn.Module. In TensorFlow, define a custom loss function as a Python function using TensorFlow operations.
Step 3: Implement the Loss Calculation:
- Implement the mathematical expression of your loss function using tensors or arrays, depending on the framework. Ensure that your implementation correctly computes the loss based on predicted values and ground truth labels.
Step 4: Calculate the Loss Value:
- Use the implemented loss function to calculate the loss value between the model’s predictions and the ground truth labels for a batch of data during training or evaluation.
Step 5: Integrate the Loss Function into Model Training:
- In your training loop, incorporate the custom loss function when computing the loss for each batch of data.
- For PyTorch, use the custom loss function as a criterion when defining the loss in the optimization step.
- For TensorFlow, set the loss function as the loss argument when compiling the model using model.compile().
Step 6: Train Your Model:
- Train your deep learning model as usual, using the custom loss function as part of the training process.
Code for TensorFlow:
TensorFlow (Using TensorFlow 2.x):
import tensorflow as tf
# Step 2: Define the custom loss function
def custom_loss(y_true, y_pred):
# Step 3: Implement the loss calculation
loss = ... # Implement your custom loss calculation here return loss #Step 4
# Step 5: Integrate the custom loss into model training
model = tf.keras.Sequential([...]) # Define your model architecture model.compile(optimizer='adam', loss=custom_loss) # Compile the model with the custom loss
# Step 6: Train the model
model.fit(x_train, y_train, epochs=num_epochs, batch_size=batch_size)
Code for PyTorch:
import torch import torch.nn as nn
# Step 2: Define the custom loss function class
class CustomLoss(nn.Module):
def __init__(self):
super(CustomLoss, self).__init__()
def forward(self, y_true, y_pred):
# Step 3: Implement the loss calculation
loss = ... # Implement your custom loss calculation here
return loss #Step 4
# Step 5: Integrate the custom loss into model training
model = CustomModel(input_dim, output_dim) # Define your model
loss_fn = CustomLoss() # Create an instance of your custom loss
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) # Define the optimizer
# Step 6: Train the model
for epoch in range(num_epochs):
optimizer.zero_grad()
predictions = model(x_train)
loss = loss_fn(predictions, y_train)
loss.backward()
optimizer.step()
In both examples, replace … with your specific loss calculation. These code templates demonstrate the essential steps for implementing a custom loss function in deep learning using TensorFlow and PyTorch.
Benefits of Loss Functions
Loss functions play a crucial role in the training of machine learning and deep learning models. They offer several benefits that are essential for model optimization and performance evaluation:
- Optimization: Loss functions are used by optimization algorithms (e.g., gradient descent) to update model parameters. Gradients of the loss function with respect to model parameters are computed, allowing the optimizer to adjust the parameters in a direction that reduces the loss, effectively optimizing the model.
- Flexibility: Different machine learning tasks require different loss functions. Loss functions are designed to be flexible and adaptable to various problem types, such as regression, binary classification, multiclass classification, and more. Custom loss functions can also be created to address specific objectives.
- Regularization: Some loss functions incorporate regularization terms (e.g., L1 or L2 regularization) that penalize large model weights. Regularization helps prevent overfitting by encouraging models to be simpler and generalize better to unseen data.
- Evaluation Metrics: Loss functions can also serve as the basis for the calculation of evaluation metrics such as accuracy, precision, recall, F1-score, and others. These metrics provide additional insights into model performance beyond just the loss value.
Conclusion
Loss functions are fundamental pillars of deep learning and machine learning, serving as a guiding force in training models and evaluating their performance. Their role in model optimization, evaluation, and fine-tuning will continue to shape the future of artificial intelligence, driving innovation across various domains and fostering new frontiers in machine learning research and development.
To discuss more, visit our data science community!
The post Loss Functions in Deep Learning appeared first on Intellipaat Blog.
Blog: Intellipaat - Blog
Leave a Comment
You must be logged in to post a comment.






