
Current and Future Trends for Cloud Architectures
Blog: Capgemini CTO Blog
Near the end of 2017 the Capgemini Academy organized a webinar where several experts discussed the Current and Future State of the Cloud. During that webinar I covered some important developments for Cloud architectures. This post is a short write-up of that content.
The evolution of cloud architectures
Cloud architectures started out by sticking close to familiar concepts from on-premises architectures. This resulted in many IaaS based solutions, where the servers were just moved into the cloud as virtual machines, but were still running the same solutions and therefore using the same architecture.
Although there’s nothing really wrong about this lift-and-shift approach, this type of architecture has an important downside: only a small part of the benefits of cloud computing are being used, because you’re not building for the cloud, but adapting to the cloud.
All cloud providers luckily also offer some common solution components as native cloud components, and it is now very common to integrate at least a few of those components as part of any cloud architecture.
You can think of solution components like a cloud identity service, or a cloud web service that hosts your applications so you don’t have to maintain a web server yourself.
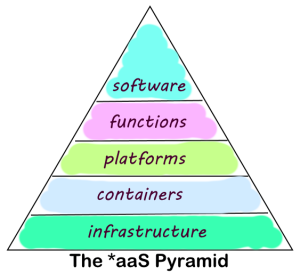
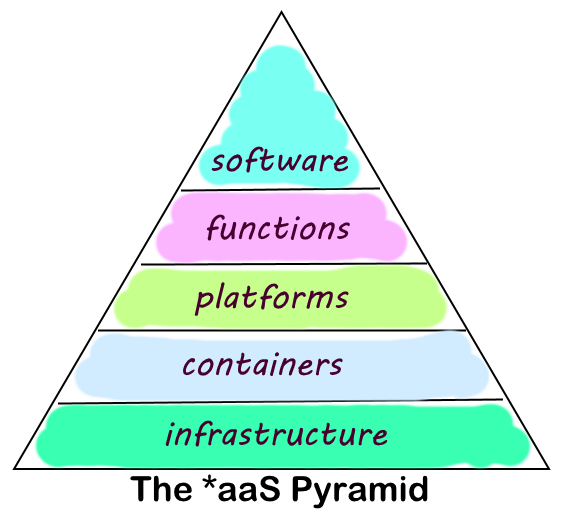
In that way, the cloud started to become more of a platform offering a toolbox full of services and components that you can use as part of your applications, which is why they call this Platform as a Service or PaaS for short.
There is more and more flexibility around the ways in which you can combine different types of services in the cloud to create your overall architecture. Such services could be storing some data, performing a calculation, or streaming a video. All these different chunks of functionality are being offered as native cloud components by the providers, and are the building blocks for your solution architectures.
If there is one major trend in cloud architecture at the moment, it’s that all large cloud providers now also let you create your own building blocks, with exactly the amount of functionality that you want. Those building blocks come in very different sizes, and there are two important trends to notice here:
Creating a single function as a building block
The first trend is that you break down a solution to the smallest possible building blocks, where you create a single function as a standalone component that you can call from anywhere, reuse, and scale.
This is what is often called Function as a Service (FaaS) or Serverless computing. But keep in mind, these are still services offered as part of the platform, so it is in fact the next evolution of PaaS, or PaaS on steroids if you will.
All major cloud providers offer something like this, Microsoft calls it Azure Functions, Amazon calls it Lambda and Google calls it Cloud Functions.
Note that the concept of an architecture based on multiple services each performing a part of the functionality is not new – this is already well known from Service Oriented Architectures (SOA) that we were already using on-premises, even before there was such a thing as cloud computing.
What’s happening now though is that SOA is taken to the next level, by splitting up functionality into a set of microservices that operate independently. This too is a general concept that is not necessarily cloud specific – microservices architectures (MSA) are also being created on-premises – but the cloud is ideally suited to support such microservices architectures.
Creating entire applications or configurations as a building block
Getting back to the building blocks that you can create yourself, I’ve now talked about creating the smallest possible building block, by using a Function as a service.
The other end of the spectrum is when you have a set of components that are difficult to separate – for example an application that is very dependent on certain software in the environment it runs in, like a specific Operating System, with a specific Service Pack installed and some specific libraries.
In that case you can still create a building block by combining all of these components that depend on each other, and storing them inside a Container. So now it’s these containers that become the standalone building blocks in your architecture. They can be moved around, duplicated and so on.
If you work in IT, you will be familiar with the phenomenon “it worked on my machine”. Well, containerization is how you prevent this.
The need for this type of building block is again something all cloud providers have acknowledged, they all have a service for containerization (Azure Container Service, EC2 Container Service, Google Container Engine). You probably have also heard about things like Docker or Kubernetes, which are also all technologies related to Containers.
The impact of cloud native building blocks
The fact that there are now so many cloud native building blocks to choose from, has created new possibilities but also new challenges. There are two important developments I want to mention:
- First, the fact that so many building blocks are now available – and the number is running up very fast – and the fact that you can combine so many different types of these services in a single cloud architecture, means that these cloud architectures can get pretty complicated.
If you create a solution comprised of many different building blocks, with some of those possibly spread out across multiple cloud providers, you need really good management tools to stay in control. Just offering certain technical capabilities in cloud computing is not enough. You need enough tooling so that you as a customer can control your solutions – with your own IT staff.
Keep in mind: there is no server anymore that you can log on to, if you want to investigate the logs. You need to really consider if all parts in your cloud architecture are providing you with enough feedback, enough logging.
The good news here is that the cloud providers are investing heavily in keeping the management layer up to date with all of their new features. - Because many features are now available as standalone cloud building blocks, it has become a lot easier for the cloud providers to also offer these services in a hybrid scenario, not just in the public cloud.
As a result, the scenarios supported for Private Cloud and Hybrid Cloud are maturing. This is sometimes called the Private Cloud 2.0. It means that the capabilities of a private cloud are no longer just a small subset of the public cloud. If you look at Microsoft Azure Stack for example (their Private Cloud offering), it’s actually very similar to their public cloud version.
The (very near) future for Cloud Architectures
In the next few years the amount of cloud building blocks will keep increasing at a high pace. These are the areas where you can expect most important new features appearing:
- Machine Learning and Artificial Intelligence
Don’t think of standalone robots (just yet), but more like services or API’s that you can use from your applications. All large cloud vendors have already started offering cognitive services that offer things like facial recognition for example (Amazon Rekognition, Microsoft Cognitive Services Face API, Google Vision API). - Internet of Things (IoT)
Another reason why AI is going to be so important is related to evolution of Internet of Things (IoT) devices and platforms. The amount of data these devices produce means that the total amount of ‘knowledge’ stored in the entire world will soon be doubling every 12 hours. We will need really clever AI solutions to still make sense of all that information. - Data storage
Luckily, we don’t need to store all of that IoT data on a regular file system or in a traditional relational database. Several other ways of storing data are available in the cloud: NoSQL data storage or Object Storage (think of the latter as the cloud version of a file system). Relational databases are hardly the standard anymore in the cloud era. They are really only suited for structured, highly uniform data sets. But if you look at the trends in cloud computing (AI, IoT), those are going to produce very large quantities of a very different type of data.
Especially the NoSQL storage (Cosmos DB from Microsoft, or DynamoDB from Amazon, Cloud Datastore from Google) seems particularly suited for IoT data storage, which is why I expect lots of new services to easily connect your AI / IoT solutions to a NoSQL solution.All that data can be stored (and available) globally if you want, but also very local: the next few years will see a lot more maturity around meeting local regulations. The large cloud providers are producing new local data centers at high speed (even the data centers themselves are created with physical “cloud building blocks”), allowing customers to place isolate data or functionality in very specific zones within a region. - GDPR
Talking about regulations and architecture, I have to also mention GDPR, the new EU data protection policy (mandatory from the end of May 2018). Any customer will have the right to request the data an organization is storing about him, and the big one: they have the right to be forgotten.
This means your current and future cloud architectures need to have mechanisms in place to access and delete that data upon request, without this resulting in an unstable system or inconsistent data set. In other words: GDPR compliancy needs to be in there by design.
You will especially need to take a close look at how you store your data, and which microservices you have available to quickly comply to customer requests.
Watch the full webinar
You can still catch the full webinar if you like – the recording is available here. It’s a quick way (around 35 minutes total) to get up to speed on cloud computing trends for security, cloud native development and architecture.
Leave a Comment
You must be logged in to post a comment.






