
Classification in Data Mining – Simplified and Explained
Classification is a widely used technique in data mining that involves categorizing data points into distinct classes. It enables the organization of various types of datasets, ranging from simple and small to complex and large. In this blog series, we will dig into simplifying and demystifying one of the essential components of data mining: classification.
Table of Contents
- What is Classification in Data Mining?
- Types of Data in Classification
- Classification Algorithms in Data Mining
- Evaluation Metrics for Classification
- Overfitting and Underfitting in Classification
- Feature Importance in Classification
- Case Studies and Real-World Examples
- Conclusion
If you are a Beginner, then do watch this Data Science Course to have in-depth knowledge about the specialization
{
“@context”: “https://schema.org”,
“@type”: “VideoObject”,
“name”: “Data Science Course | Data Science Full Course | Data Scientist For Beginners | Intellipaat”,
“description”: “Classification in Data Mining – Simplified and Explained”,
“thumbnailUrl”: “https://img.youtube.com/vi/a5KmkeQ714k/hqdefault.jpg”,
“uploadDate”: “2023-07-21T08:00:00+08:00”,
“publisher”: {
“@type”: “Organization”,
“name”: “Intellipaat Software Solutions Pvt Ltd”,
“logo”: {
“@type”: “ImageObject”,
“url”: “https://intellipaat.com/blog/wp-content/themes/intellipaat-blog-new/images/logo.png”,
“width”: 124,
“height”: 43
}
},
“embedUrl”: “https://www.youtube.com/embed/a5KmkeQ714k”
}
What is Classification in Data Mining?
Classification is a fundamental concept in the field of data mining. It refers to the process of categorizing or grouping data instances into predefined classes or categories based on their characteristics or attributes.
Imagine you have a collection of fruits, including apples, oranges, and bananas. If someone gives you a new fruit and asks you to identify it, you would look at its properties, such as color, shape, and size, and then assign it to the appropriate category, whether it’s an apple, orange, or banana. This categorization process is similar to classification in data mining.
In the context of data mining, classification means analyzing a dataset that contains numerous instances or examples, each of which is defined by a collection of properties or features. The objective is to create a model or algorithm that can automatically classify fresh, unseen cases based on their feature values.
A dataset containing information about bank clients, such as their age, income, and loan history. The job may be to determine whether or not a customer is likely to default on a loan. A classification algorithm can learn to generate predictions based on the given information by analyzing the patterns and relationships in the data.
To learn more check out Intellipaat’s Data Science course.
Types of Data in Classification
In classification, data refers to the information or attributes associated with each instance or example in a dataset. The type of data plays a crucial role in determining the appropriate classification algorithm and preprocessing techniques to be used. Let’s explore the different types of data commonly encountered in classification:
Categorical Data
Categorical data represents discrete, qualitative information that can be divided into specific categories or classes. It does not have any inherent numerical meaning. Examples of categorical data include gender (e.g., male or female), color (e.g., red, blue, or green), and occupation (e.g., doctor, engineer, or teacher). Categorical data is typically represented using labels or symbols, and specific techniques like one-hot encoding or label encoding are often used to transform categorical data into a suitable numerical format for classification algorithms.
Numerical Data
Numerical data represents continuous or discrete numerical values. It can be further categorized into two subtypes:
- Continuous Numerical Data: Continuous numerical data represent measurements or observations that can take any value within a specific range. Examples include age, height, temperature, and salary. Continuous numerical data can have infinite possible values within a range and is typically represented using real numbers. Classification algorithms can handle continuous numerical data directly without any special preprocessing.
- Discrete Numerical Data: Discrete numerical data represents countable or finite numerical values. It consists of distinct, separate values rather than a continuous range. Examples include the number of siblings, the number of customer visits, or the number of items purchased. Discrete numerical data can be directly used in classification algorithms without any specific preprocessing.
Textual Data
Textual data, also known as unstructured data, refers to information presented in the form of text or documents. It can include textual descriptions, customer reviews, emails, social media posts, or any other written content. Textual data presents unique challenges for classification because it requires specialized techniques for feature extraction and representation. Techniques such as text preprocessing, tokenization, stop-word removal, and vectorization (e.g., using methods like bag-of-words or TF-IDF) are employed to convert textual data into a numerical format suitable for classification algorithms.
Check out our blog on Data Science tutorial to learn more about it.
Classification Algorithms in Data Mining
Decision Trees
Decision trees are simple and straightforward categorization models. They depict a tree-like structure, with each internal node representing a test on an attribute, each branch representing a test result, and each leaf node representing a class label. The tree is constructed by splitting the data recursively depending on the attribute that best separates the classes. C4.5 and CART are two examples of decision tree algorithms.
Assume you have a dataset of emails that have been labeled as “spam” or “not spam” based on their content. The model can build rules for identifying new emails as spam or not by analyzing factors such as the presence of certain keywords, email length, and sender information using a decision tree method.
Random Forest
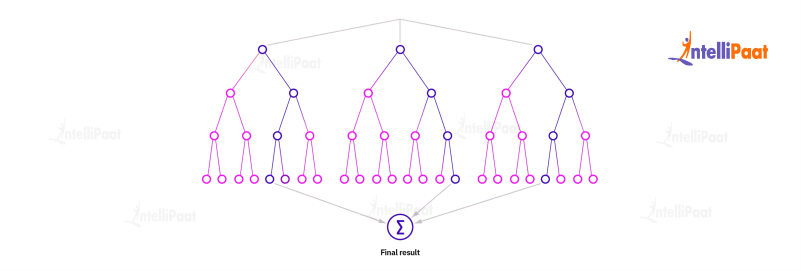
It is an ensemble learning approach that combines multiple decision trees to make predictions. It is recognized for its ability to mitigate overfitting and handle high-dimensional data effectively.
For instance, in the healthcare domain, a Random Forest algorithm can be applied to predict the likelihood of a patient developing a specific illness. This prediction is based on various patient attributes, including age, family medical history, lifestyle factors, and results from blood tests. By leveraging the ensemble of decision trees within the Random Forest model, more precise and reliable predictions can be achieved. The aggregation of multiple decision trees allows the model to capture diverse patterns and make well-informed predictions regarding an individual’s health condition.
Naive Bayes
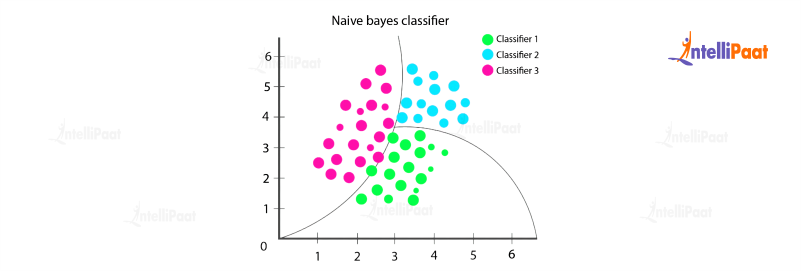
Naive Bayes is a probabilistic classification algorithm based on Bayes’ theorem. It assumes that all features are conditionally independent of each other, given the class label. Naive Bayes is particularly effective in situations where the assumption of independence holds reasonably well. It is widely used for text classification and spam filtering.
Example: In sentiment analysis, Naive Bayes can be used to classify movie reviews as positive or negative based on the words and phrases used in the reviews. By learning the conditional probabilities of different words given the sentiment class, the Naive Bayes algorithm can make accurate predictions about the sentiment of new reviews.
Support Vector Machines (SVM)
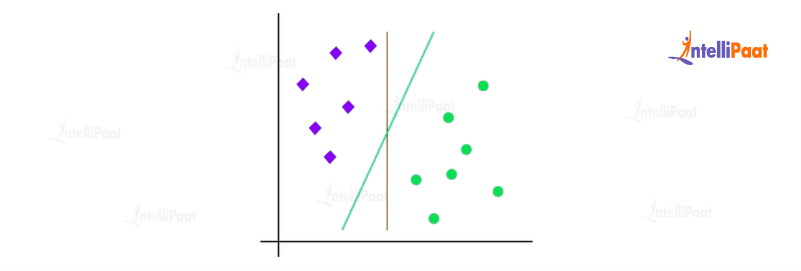
It is a robust classification technique widely recognized for its ability to identify an optimal hyperplane in a high-dimensional space for class separation. It achieves this by transforming the data into a higher-dimensional feature space and determining the decision boundary that maximizes the margin between the classes. SVM is versatile and can handle both linear and nonlinear classification problems efficiently.
For example, SVM finds extensive use in image recognition tasks. By utilizing SVM, it becomes possible to classify images into various categories like cats, dogs, or cars. The algorithm learns to identify distinctive features within the images that effectively differentiate between different classes. By leveraging these discriminative features, SVM can accurately classify new images based on their content. This makes SVM a valuable tool in tasks where precise image categorization is required, such as in computer vision applications or object recognition systems.
K-Nearest Neighbors (KNN)
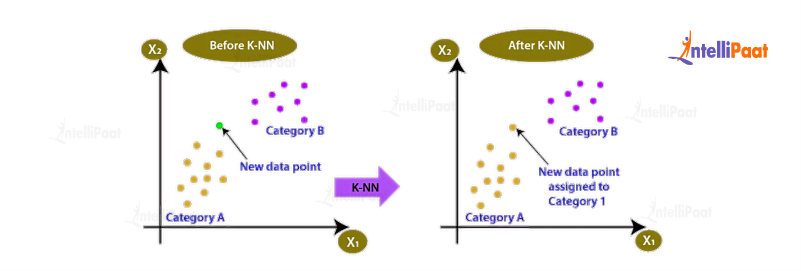
KNN is a simple yet effective classification algorithm. It assigns a new instance to a class based on the majority vote of its nearest neighbors. The “K” in KNN represents the number of nearest neighbors to consider. KNN is a non-parametric method, meaning it does not make any assumptions about the underlying data distribution.
Example: Suppose you have a dataset of customer attributes such as age, income, and purchase history. By applying KNN, you can predict whether a new customer is likely to make a purchase based on the attributes of their nearest neighbors, i.e., customers with similar characteristics.
Logistic Regression
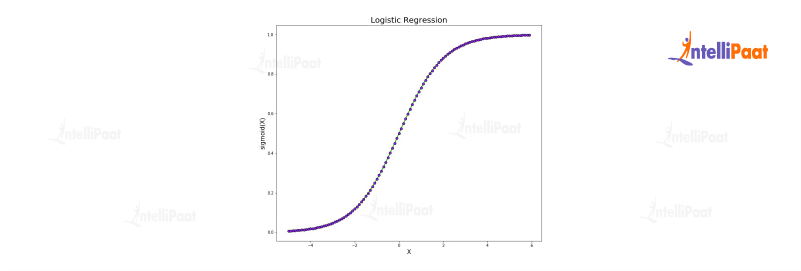
It is a statistical classification algorithm that establishes a relationship between attributes and the probability of belonging to a specific class. It utilizes a logistic function to model these probabilities and is capable of handling both binary and multiclass classification problems. Logistic Regression is known for its interpretability and performs well when the decision boundary is linear.
For instance, in credit scoring applications, logistic regression can be applied to predict the likelihood of loan default for a given applicant. By considering attributes such as credit score, income, and employment history, the logistic regression model analyzes their relationship with the probability of default.
This enables the model to provide a risk assessment for new loan applicants, aiding in the decision-making process of granting or denying loans. The interpretable nature of logistic regression allows lenders to understand the impact of different attributes on the predicted default probabilities, facilitating informed lending practices.
Get your master’s degree in Data Science right now. Enroll in the Master of Science in Data Science by the University of Essex.
Career Transition





Evaluation Metrics for Classification
Evaluation metrics in classification are used to assess the performance and accuracy of a classification model. These metrics provide valuable insights into how well the model is classifying instances and can guide further improvements or comparisons between different models. Let’s explore some commonly used evaluation metrics in classification:
Accuracy
Accuracy measures the overall correctness of the classification model by calculating the ratio of correctly classified instances to the total number of instances. It is a straightforward metric but may not be suitable for imbalanced datasets where the class distribution is uneven.
Precision
Precision is the fraction of accurately anticipated positive cases out of all positive instances forecasted. It is beneficial when the goal is to reduce false positives. Precision is measured by dividing the number of true positives by the total number of true positives and false positives.
Sensitivity (or True Positive Rate)
The proportion of accurately anticipated positive events out of all actual positive instances is measured by a recall. It is beneficial when the objective is to reduce false negatives. The ratio of true positives to the sum of true positives and false negatives is used to determine recall.
F1 Score
The F1 score is the harmonic mean of precision and recall. It provides a balanced measure of the model’s performance by considering both precision and recall. The F1 score is useful when there is an uneven class distribution or when both false positives and false negatives need to be minimized.
Specificity (True Negative Rate)
Specificity measures the proportion of correctly predicted negative instances out of all actual negative instances. It is the complement of the false positive rate. Specificity is calculated as the ratio of true negatives to the sum of true negatives and false positives.
Receiver Operating Characteristic (ROC) Curve
The ROC curve is a graphical representation of the performance of a classification model. It plots the true positive rate (sensitivity) against the false positive rate (1 – specificity) at various classification thresholds. The area under the ROC curve (AUC-ROC) is a commonly used metric to compare the performance of different models. A higher AUC-ROC value indicates a better-performing model.
The confusion matrix is an extensive evaluation tool that provides a thorough examination of a classification model’s performance. It displays the frequencies for correctly predicted positives, incorrectly predicted positives, and incorrectly predicted negatives. Examining these statistics can provide valuable insights into the model’s accuracy in classifying instances and detecting classification mistakes.
Overfitting and Underfitting in Classification
Overfitting and underfitting are two common issues that can occur in classification models. Let’s explore these concepts in more detail:
Overfitting
Overfitting happens when a classification model learns to fit the training data too closely, capturing noise or random fluctuations that are specific to the training set. As a result, the model becomes overly complex and fails to generalize well to unseen data. It memorizes the training examples instead of learning the underlying patterns, leading to poor performance on new data.
In an overfit model, the decision boundary becomes excessively intricate, effectively “over-adapting” to the training data. This can cause high accuracy on the training set but low accuracy on the validation or test sets. Overfitting can occur when a model is too flexible or when the training data is limited or noisy.
To address overfitting, techniques such as regularization, feature selection, and increasing the amount of training data can be applied. Regularization helps control the model’s complexity, preventing it from excessively fitting the noise in the training data. Feature selection aims to identify the most relevant features, reducing the risk of overfitting by eliminating irrelevant or redundant ones. Additionally, obtaining more diverse and representative training data can help the model learn generalized patterns instead of memorizing specific instances.
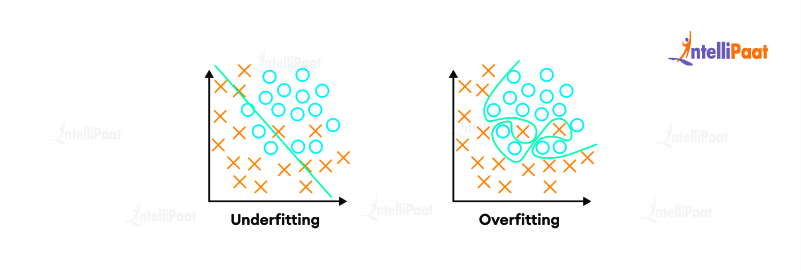
Underfitting
Underfitting occurs when a classification model is too simplistic and fails to capture the underlying patterns in the data. It results in a high-bias and low-variance model that performs poorly on both the training and validation/test sets. An underfit model oversimplifies the relationships between features and class labels, leading to high errors and low accuracy.
In an underfit model, the decision boundary is too rigid and fails to capture the complexity of the data. It may result from using an overly simple algorithm or inadequate model capacity to capture the intricacies of the data. Underfitting often arises when the model is not given sufficient training time or when the complexity of the problem is underestimated.
To address underfitting, one can try increasing the model’s complexity, using more powerful algorithms, or incorporating additional features that better represent the underlying relationships in the data. Fine-tuning hyperparameters, such as adjusting the learning rate or increasing the number of iterations, can also help the model learn more complex patterns.
Go through these Data Science Interview Questions and Answers to excel in your interview.
Courses you may like
Feature Importance in Classification
Feature importance in classification refers to the process of determining the relevance or contribution of different features or variables in predicting the class labels of instances. It helps identify the most influential features that have the greatest impact on the classification outcome. Understanding feature importance provides valuable insights into the underlying relationships between the input variables and the target variable in a classification problem.
There are various methods to assess the importance of features in classification models. Let’s explore a few commonly used techniques:
Case Studies and Real-World Examples
Case studies and real-world examples are valuable resources that demonstrate the practical applications and benefits of classification in various domains. They provide concrete illustrations of how classification techniques can be employed to solve specific problems and deliver meaningful insights. Let’s explore a few case studies and real-world examples to understand the significance of classification in different contexts:
Spam Email Classification
Classification algorithms are widely used to separate spam emails from legitimate ones. By training a classification model on a labeled dataset of spam and non-spam emails, it becomes possible to accurately classify incoming emails, redirect spam messages to a separate folder, or mark them as spam. This helps users save time by focusing on relevant emails and reduces the risk of falling victim to phishing attacks or scams.
Disease Diagnosis
Classification techniques play a crucial role in medical diagnosis. By analyzing patient data, including symptoms, medical history, and test results, classification models can assist in identifying specific diseases or conditions. For example, in the case of breast cancer diagnosis, a classification model can analyze features extracted from mammograms and predict whether a detected abnormality is benign or malignant, aiding in early detection and timely treatment.
Credit Risk Assessment
Classification is extensively employed in credit risk assessment for loan applications. By considering various attributes of loan applicants, such as credit score, income, employment history, and debt-to-income ratio, classification models can predict the likelihood of default. Lenders can utilize these predictions to make informed decisions about approving or denying loan applications, thereby minimizing the risk of financial losses.
Image Classification
Classification algorithms find widespread use in image classification tasks. For instance, in autonomous driving, object detection and classification are crucial for identifying pedestrians, vehicles, and traffic signs. Classification models can analyze image features and accurately classify objects, facilitating safer and more efficient autonomous vehicle systems.
Sentiment Analysis
Classification techniques are employed in sentiment analysis to determine the sentiment or opinion expressed in text data. By training a model on labeled text data, such as customer reviews or social media posts, classification models can automatically classify text as positive, negative, or neutral. This enables businesses to gain insights into customer sentiment and make data-driven decisions about improving products or services.
Conclusion
Classification in data mining is a powerful and versatile technique that enables the categorization and prediction of class labels for various applications. By utilizing a range of classification algorithms, such as Random Forest, Support Vector Machines, and Logistic Regression, data scientists can tackle complex classification tasks and extract meaningful patterns from data.
Additionally, evaluation metrics, feature importance analysis, and consideration of overfitting and underfitting help ensure the effectiveness and generalization of classification models. With its wide range of applications, classification proves to be a fundamental tool for enhancing accuracy, improving efficiency, and driving innovation across diverse domains.
If you have any queries related to this domain, then you can reach out to us at Intellipaat’s Data Science Community!
The post Classification in Data Mining – Simplified and Explained appeared first on Intellipaat Blog.
Blog: Intellipaat - Blog
Leave a Comment
You must be logged in to post a comment.






