
AWS Glue Tutorial
Amazon Glue has increased in popularity as more firms began to use managed data integration services. Glue is mostly used by data engineers and ETL developers to construct, run, and monitor ETL workflows.
We’ll go through these topics in this AWS Glue Tutorial:
- What is AWS Glue?
- Benefits of using AWS Glue
- AWS Glue Use cases
- AWS Data Pipeline vs AWS Glue
- AWS Glue Components
- AWS Glue Architecture
- AWS Glue Advantages
- AWS Glue Pricing
- Conclusion
To get started, Watch this informative AWS Glue Tutorial YouTube Video:
What is AWS Glue?
AWS Glue is a precisely and expertly addressed ETL (extract, transform, and load) tool for automating data analysis. It has drastically decreased the time required to prepare data for analysis. It automatically detects and lists the data using AWS Glue Data Catalog. It recommends, selects, and creates Python or Scala code for data transmission from the source, loads and transforms the Job depending on timed events, offers configurable schedules, and develops an Apache Spark environment that is scalable for targeted data loading.
The AWS Glue service alters, balances, secures and monitors Complex data streams. It provides a serverless solution by simplifying the complicated activities involved in application development.
AWS Glue also offers speedy integration procedures for combining several legitimate data sets and quickly breaking down and approving the data.
Learn in-depth about AWS through our AWS tutorial.
Benefits of using AWS Glue
Faster data integration
AWS Glue allows different groups in your business to collaborate on data integration tasks such as extraction, cleaning, normalizing, combining, loading, and performing scalable ETL workflows. This reduces the time it takes to examine and use your data from months to minutes.
Automate data integration
AWS Glue automates most of the work involved in data integration. it scans your data sources, recognizes data formats, and recommends schemas for data storage.
It generates the code required to conduct your data transformations and loading operations automatically. It simplifies the execution and management of hundreds of ETL procedures, as well as the mixing and duplicating of data across several data stores using SQL.
No servers
AWS Glue operates in a serverless mode. There is no infrastructure to manage, and allocates, configures, and scales the resources needed to conduct your data integration operations. You only pay for the resources that your jobs consume while running.
AWS Glue Use cases
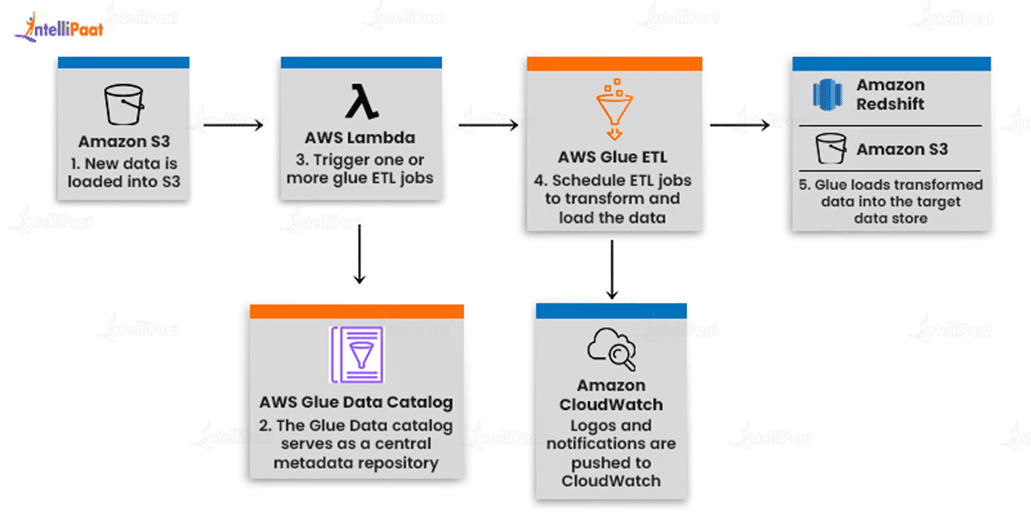
Build event-driven ETL Pipelines
AWS Glue can perform your ETL processes as new data arrives. You can, for example, utilize an AWS Lambda function to have your ETL operations executed as soon as new data is available in Amazon S3. You can also include this new dataset in your ETL operations by registering it in the AWS Glue Data Catalog.
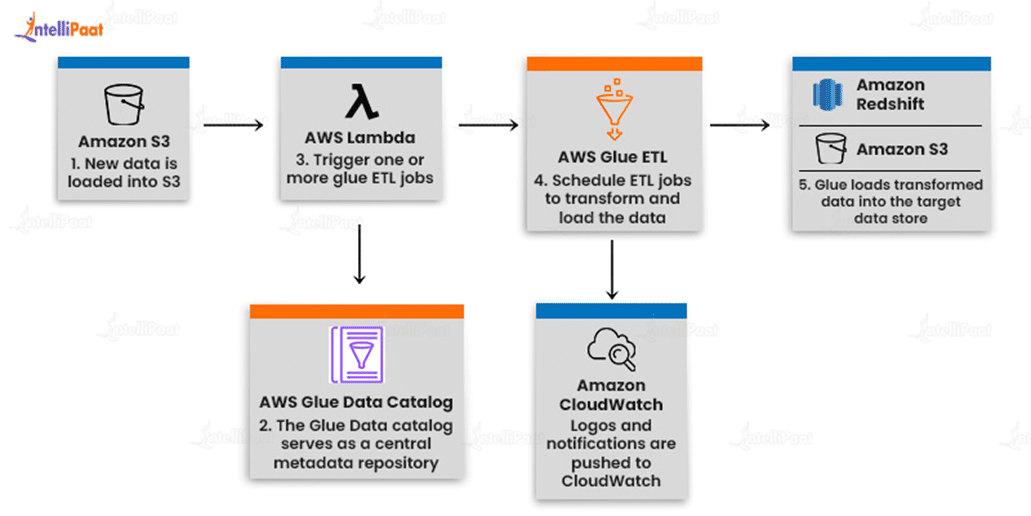
Create a unified catalog
The AWS Glue Data Catalog allows you to discover and search across numerous AWS data sets without having to move the data. Once the data has been cataloged, it is immediately available for search and query utilizing Amazon Athena, Amazon EMR, and Amazon Redshift Spectrum.
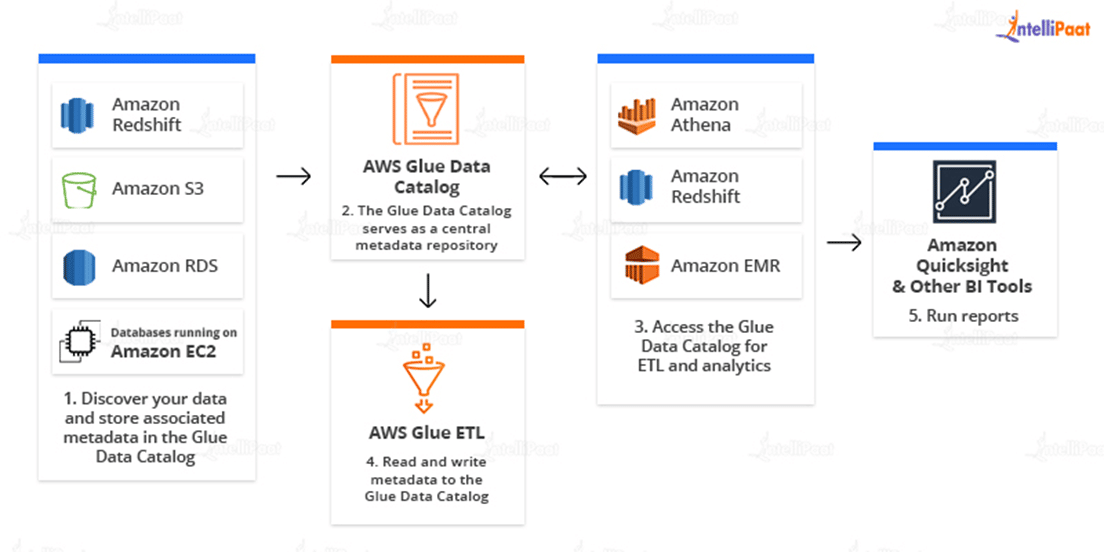
Create, run, and monitor ETL Jobs
AWS Glue Studio makes it simple to graphically develop, run, and monitor AWS Glue ETL operations. It automatically creates code for ETL tasks that transport and convert data.
You can then utilize the AWS Glue Studio job run dashboard to monitor ETL execution and confirm that your jobs are working properly.
Explore data
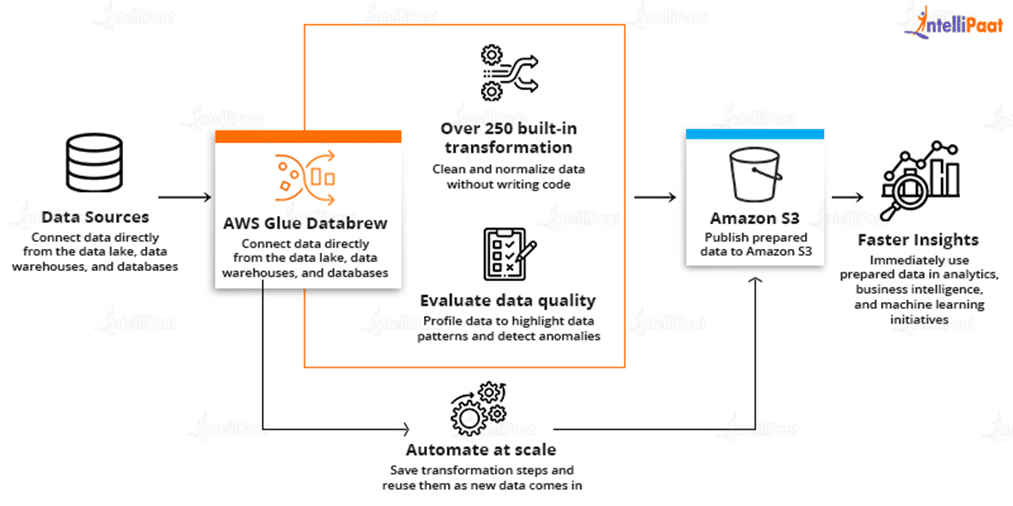
AWS Glue DataBrew allows you to explore and experiment with data straight from your data lake, data warehouses, and databases, such as Amazon S3, Amazon Redshift, AWS Lake Formation, Amazon Aurora, and Amazon RDS, and you can choose from over 250 prebuilt transformations to simplify data preparation chores like filtering anomalies, standardizing formats, and rectifying inaccurate values.
After the data has been prepared, it can be used immediately for analytics and machine learning.
Are you preparing for a job interview? Visit our AWS Interview Questions blog for more information.
AWS Data Pipeline vs AWS Glue
| Parameters | AWS Data Pipeline | AWS Glue |
| Specialization | Data Transfer | ETL, Data Catalog |
| Pricing | Pricing is determined on frequency of use and whether you utilize AWS or an on-premise arrangement. | AWS Data Catalog charges for storage on a monthly basis, whereas AWS Glue ETL charges on an hourly basis. |
| Data Replication | Full table; incremental replication through timestamp Field | Full table; incremental using AWS Database Migration Service (DMS)Change Data Capture (CDC). |
| Connector availability | AWS Data Pipeline only supports four data sources: DynamoDB, SQL, Redshift, and S3. | It uses JDBC to connect to Amazon platforms like Redshift, S3, RDS, DynamoDB, AWS destinations, and other databases. |
AWS Glue Components
AWS Glue depends on the interaction of various components to develop and maintain your ETL operation. The essential components of the Glue architecture are as follows:
- AWS Glue Data Catalog: Permanent metadata is saved in the Glue Data Catalog. It delivers table, task, and other control data to help you maintain your Glue environment. AWS provides one Glue Data Catalog per account and region.
- Classifier: A classifier is the data structure determined by the classifier. It includes classifiers for popular relational database management systems and file formats such as CSV, JSON, AVRO, and XML.
- Connection: The AWS Glue Connection Data Catalog object contains the properties required to connect to a certain data storage.
- Crawler: It is a component that explores many data repositories in a single encounter. It builds metadata tables in the Glue Data Catalog after determining the schema for your data using a prioritized set of classifiers.
- Database: A database is a logically organized collection of Data Catalog table definitions that are linked together.
- Data Store: A data storage facility is a site where you can keep your data for an extended period of time. Examples include relational databases and Amazon S3 buckets.
- Data Source: A data source is a group of data used as input to a process or transformation.
- Transform: The logic in the code used to change your data’s format is known as transform.
- Development Endpoint: You may construct and test your AWS Glue ETL scripts using the development endpoint environment.
- Dynamic Frame: A DynamicFrame is similar to a DataFrame, with the exception that each element is self-descriptive. Consequently, a schema is not required at first. Furthermore, Dynamic Frame has a suite of advanced data cleansing and ETL techniques.
- Job: AWS Glue Job is a type of business logic required for ETL tasks. A job’s components include a transformation script, data sources, and data targets.
- Trigger: Trigger initiates the ETL process. Triggers can be configured to occur at a predetermined time or in response to an event.
- Notebook Server: It’s a web-based environment where you can perform PySpark commands. A notebook on a development endpoint enables active authoring and testing of ETL scripts.
- Script: A script is a piece of code that gathers information from sources, modifies it, and loads it into destinations. AWS Glue is used to create PySpark or Scala scripts. Amazon Glue provides notebooks as well as Apache Zeppelin notebook servers.
- Table: A table in data storage is the metadata description that describes the data. A table stores column names, data type definitions, partition information, and other metadata about a base dataset.
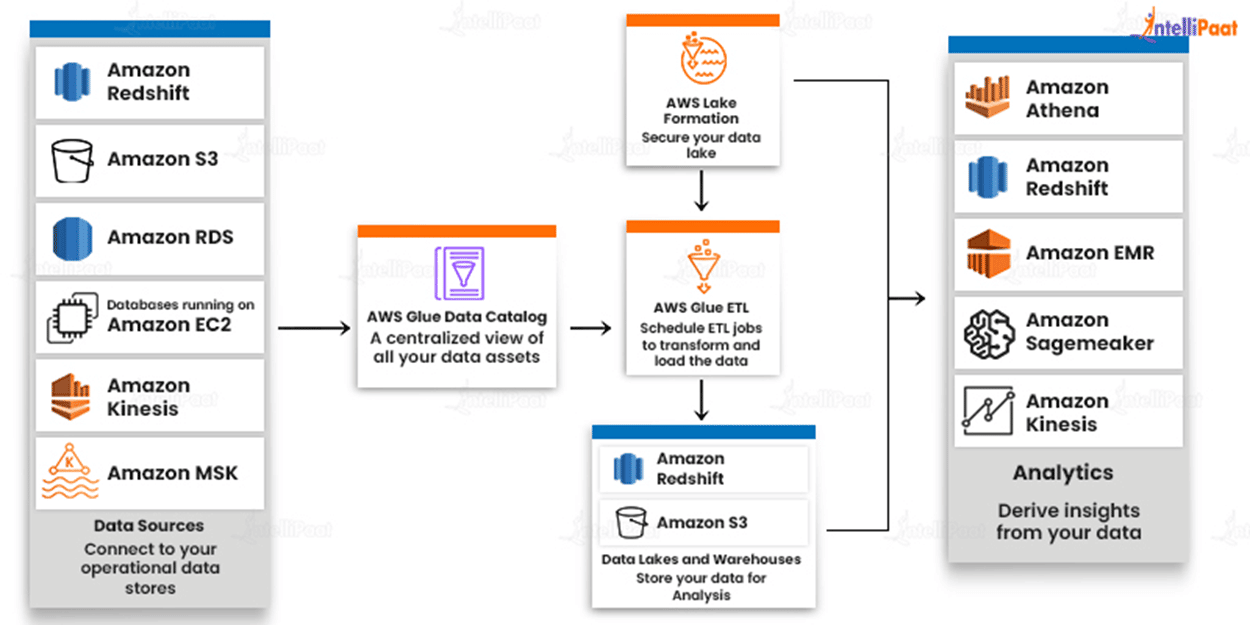
AWS Glue Architecture
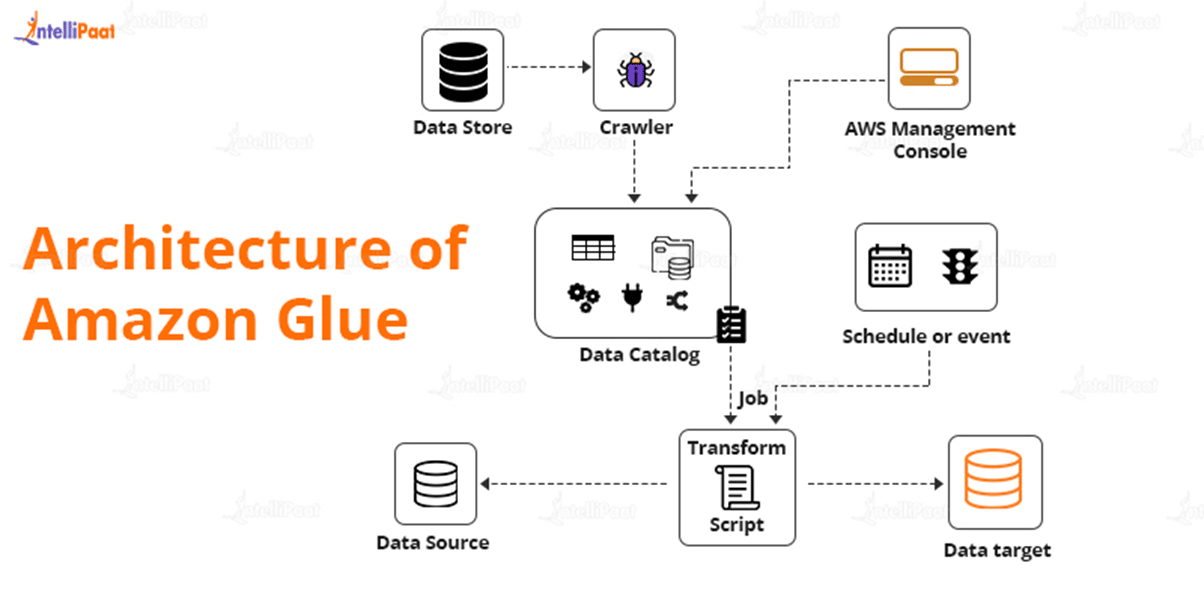
AWS Glue tasks are used to extract, transform, and load (ETL) data from a data source to a data destination. The steps are as follows:
- First, you must pick which data source you will use.
- If you’re utilizing a data storage source, you’ll need to create a crawler to send metadata table definitions to the AWS Glue Data Catalog.
- When you point your crawler at a data store, it adds metadata to the Data Catalog.
- If you’re using streaming sources, you’ll need to explicitly establish in Data Catalog tables and data stream characteristics.
- Once the Data Catalog has been categorized, the data is instantly searchable, queryable, and ETL-ready.
- After creating the script, you can execute it on-demand or schedule it to start when a specific event occurs. The trigger can be a timed schedule or an event.
- While the task is executing, the script will extract data from the data source, transform it, and load it to the data target, as illustrated in the diagram above. As a result, the ETL (Extract, Transform, Load) process in AWS Glue is successful.
Career Transition





AWS Glue Advantages
- Glue is a serverless data integration solution that does not involve the construction or management of infrastructure.
- It provides simple tools for creating and tracking work activities triggered by schedules, events, or on-demand.
- It is a low-cost solution. You only need to pay for the resources you use during the job execution process.
- Based on your data sources and destinations, Glue will create ETL pipeline code in Scala or Python.
- Several organizations inside the corporation can use AWS Glue to collaborate on various data integration initiatives. This reduces the amount of time required to analyze the data.
If you have any questions or concerns about this technology, please post them on the AWS Community.
AWS Glue Pricing
The initial price for Amazon Glue is $0.44. The four available plans are as follows:
- Development endpoints and ETL jobs are offered for $0.44.
- Crawlers and DataBrew interactive sessions are offered for $0.44 each session.
- At DataBrew, starting salaries are $0.48.
- The Data Catalog’s requests and monthly storage cost are $1.00.
AWS does not offer a free plan for the Glue service. It will cost roughly $0.44 per DPU every hour. Therefore, you will need to spend $21 every day on average. However, pricing may differ by region.
Courses you may like
Conclusion
AWS Glue stands out from other competitors as a cost-efficient serverless service provider. Amazon Glue provides simple tools for categorizing, sorting, validating, enhancing, and moving data stored in warehouses and data lakes.
Working with semi-structured or clustered data is possible using AWS Glue. This service is compatible with other Amazon services and provides centralized storage by merging data from numerous sources and preparing for various phases such as reporting and data analysis.
With its seamless interaction with various platforms for quick and fast data analysis at a low cost, the AWS Glue service achieves excellent efficiency and performance.
Check out Intellipaat’s best AWS training to get ahead in your career!
The post AWS Glue Tutorial appeared first on Intellipaat Blog.
Blog: Intellipaat - Blog
Leave a Comment
You must be logged in to post a comment.






