
Using Alternative Data in Credit Risk Modelling
Blog: Enterprise Decision Management Blog

“Whenever I bring up the topic of alternative data, the first question our board asks is, ‘Are we using Facebook data?’ “
This comment from a participant in our recent EMEA Risk Leadership Forum caused a lot of chuckles and nodding heads. When it comes to evaluating credit risk, everyone wants to know if, when and how lenders will start probing their Facebook account.
For reasons that will be obvious to lenders, that tantalizing possibility doesn’t actually top the list of data sources to mine. In fact, at the forum we explored a few sources of data that can add to the picture of a consumer’s creditworthiness.
Multiple Types of Alternative Data
What is alternative data? In credit granting, it generally refers to any data that is not directly related to a consumer’s credit behavior. Traditional data usually means data from a credit bureau, a credit application or a lender’s own files on an existing customer. Alternative data is everything else.
Alternative data is a hot topic, in part because of the data explosion of the last few years, and in part because of the drive for financial inclusion. There are an estimated 3 billion adults worldwide who don’t have credit and so don’t have credit records. Opening up that market is a priority for lenders. And while many of these people are in developing markets with nascent credit infrastructures, there are so-called “credit invisibles” in the most mature credit markets, people who have no credit and are unknown to the credit bureaus.
With this in mind, let’s look at a few sources of alternative data, and how useful they are for credit decisions.
- Transaction Data. This is typically data on how customers use their credit or debit cards. It may not seem “alternative” — most lenders have this data already, often manipulated into monthly summaries — but it’s not often mined to extract the maximum predictive value. It can be used to generate a wide range of predictive characteristics such as Ratios of Cash to Total Spend in last X week(s) or Ratios of Spend in last X week(s) to last Y week(s) and even characteristics based on the number, frequency and value of transactions at different retailer types. Processing it can be time-consuming, but the data itself is generally clean.
- Telecom / Utility / Rental Data. This data is basically credit history data, but it’s alternative because it doesn’t actually appear in most credit reports. FICO has mined this data for the FICO® Score XD in the United States.
- Social Profile Data. Mining Facebook, LinkedIn, Twitter, Instagram, Snapchat or other social media sites is possible, but few lenders would want to brave the regulatory hurdles of being the first mover. Although it would be possible to derive the value not from what people say in these channels but from metadata – for example, the number of posts and their frequency or the size of their social graph — this would still likely raise privacy issues. In addition, despite what some enterprising fintechs might say, the value of this data would be far lower than the value of data with a stronger credit connection. It is also possible for a consumer to manipulate this data.
- Clickstream Data. How a customer moves through your website, where they click and how long they take on a page can be predictive.
- Audio and Text Data. This data takes the form of information found on credit applications, in recorded customer service or collections calls. It can complement “thin files” and is already proving its worth in collections.
- Social Network Analysis. New technology enables us to map a consumer’s network in two important ways. First, this technology can be used to identify all the files and accounts for a single customer, even if the files have slightly different names or different addresses. This gives you a better understanding of the consumer and their risk. Second, we can identify the individual’s connections with other people, such as people in their household. When evaluating a new credit applicant with no or little credit history, the credit ratings of the applicant’s network can provide useful information. However, this is not going to meet the regulatory tests in all markets.
- Survey / Questionnaire Data. An innovative new way of rating the credit risk of someone with little or no credit history is through psychometrics. The leader in this field, EFL, bases their scores on 10 years of research at Harvard. FICO has partnered with EFL to make more people scorable in markets across the globe.
How Much Value?
FICO research has shown that these data sources do add predictive value on margin to credit risk models based on traditional data. The amount of predictive value outlined in the table below should be viewed as relative indicators, not absolute values, as the additional value of the data source is based on many parameters such as predictive power of existing models, strength of the customer relationship with the lender, etc.
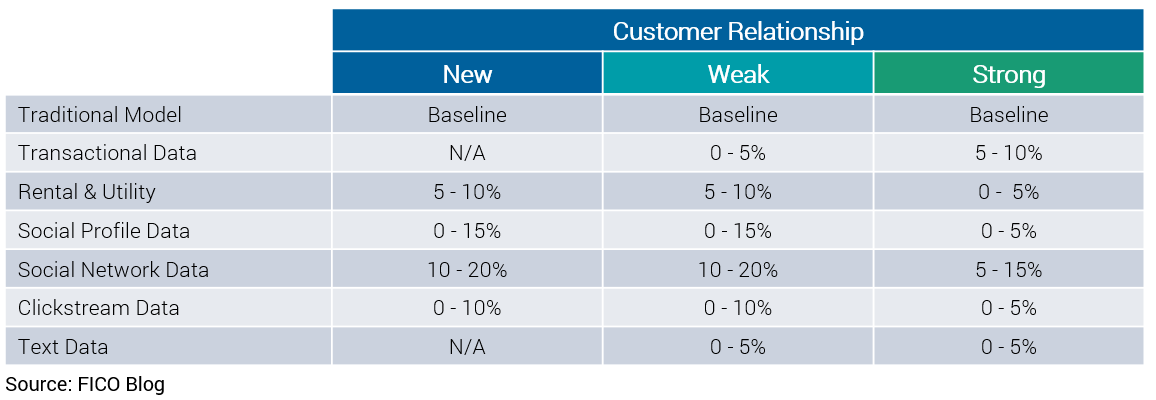
Please note that the Traditional Models used as the baseline were application models, not credit bureau score models (such as the FICO® Score).
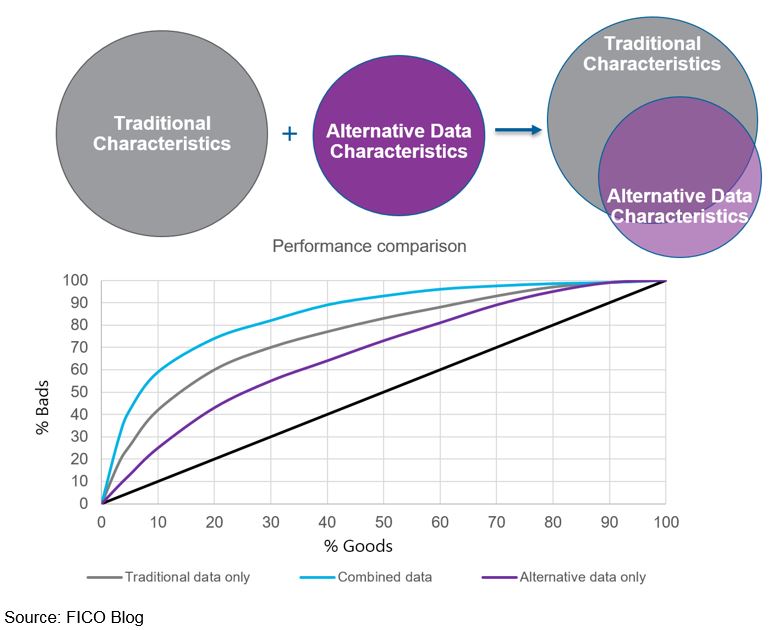
The chart below shows the result of one project FICO did for a personal loans origination portfolio. The traditional credit characteristics captured more value than the alternative data characteristics (with the alternative data capturing about 60% of the predictive power), and there was a high degree of overlap between the two. However, by combining the traditional and alternative data characteristics (and understanding the overlap so as not to over-weigh certain variables’ contribution), we were able to produce a more powerful model.
Machine Learning and Explainability
It’s impossible to talk about alternative data without talking about different analytic technologies and machine learning, such as neural networks, random forests and stochastic gradient boosting. With large, unstructured data sets, the smart use of these technologies can identify data patterns that relate to credit risk and make the model development process more manageable.
However, as is true with AI in general, data scientists play an important role. They need to check the accuracy of the output, make sure the model doesn’t overfit the data, make sure the model provides stable output, and ensure that the patterns discovered are strong, relevant and explainable.
Explainability is a challenge when dealing with AI and machine learning. Lenders need to explain how consumers are scored – certainly to regulators, and often to consumers themselves. FICO uses a technology we call Scorecardizer, which takes the patterns identified in AI, machine learning and other techniques and turns them into scorecards that are easy to understand and implement, and produce the similar uplifts in predictive power as machine learning models. For more information on these techniques, see the blog post by FICO Chief Analytics Officer Scott Zoldi on How to Build Credit Risk Models Using AI and Machine Learning.
FICO’s analytics team will be presenting some of these concepts at the 2017 Credit Scoring and Credit Control Conference in Edinburgh, August 30-September 1. We have six presentations on a wide range of topics – if analytics is your thing, stop by and see us.
Read more posts by FICO experts on alternative data.
The post Using Alternative Data in Credit Risk Modelling appeared first on FICO.
Leave a Comment
You must be logged in to post a comment.






