The Open Business Data Lake Standard, Part VIII
Blog: Capgemini CTO Blog
In my previous blog posts (part I, part II, and part III) about the Open Business Data Lake Conceptual Framework (O-BDL), I introduced its background, concept, characteristics, and platform capabilities. In part IV, part V, and part VI I compared a data lake with other data processing platforms, described how an O-BDL should work and defined possible business scenarios that can make use of an O-BDL. In part VII, I elaborated on the O-BDL data and data ingestion concept. In this part, I’ll describe the O-BDL in more detail with regards to the O-BDL data processing concept.
In part V I introduced the following process diagram (applying The ArchiMate® Enterprise Architecture Modeling Language) to describe how an O-BDL should work.
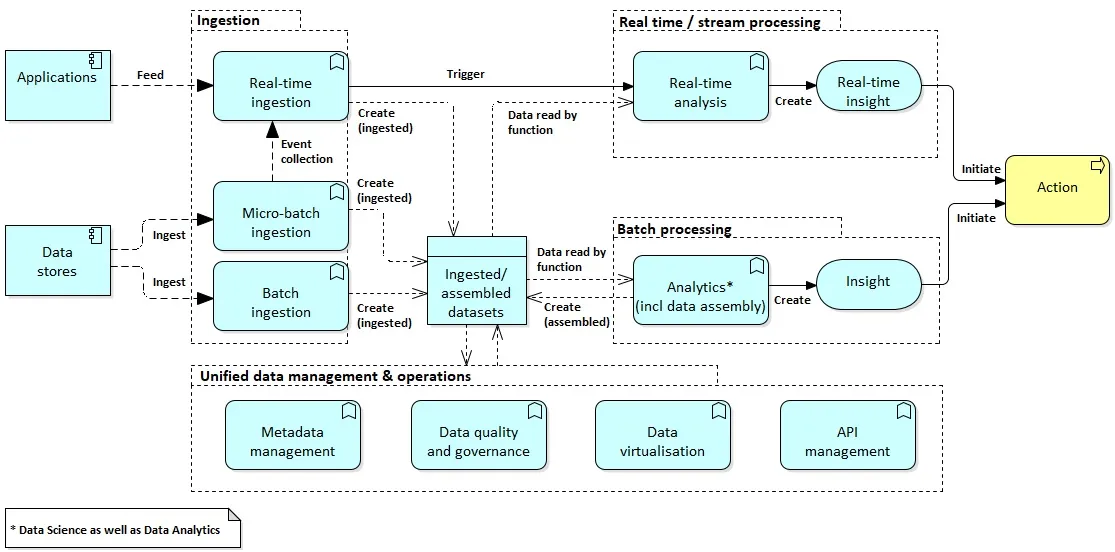
Based on this process, the O-BDL data processing concept is described in more detail.
The data processing concept
The data processing concept is shown using the lambda architecture diagram:
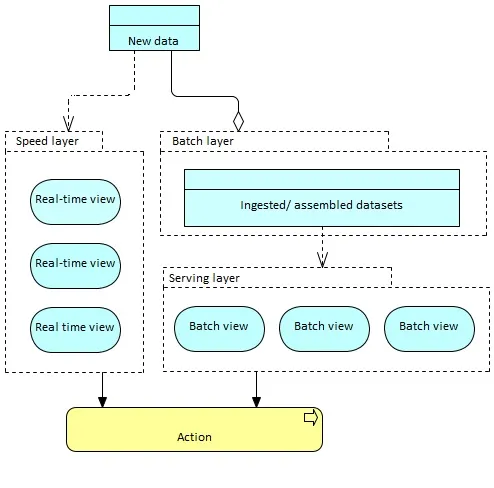
The lambda architecture associates two specialized processing capabilities (“engines”) in two dedicated layers:
- The batch processing layer for “regular” (batch) analytics and data transformation
- The speed (i.e., real-time) processing layer for real-time (complex or not) event and stream processing.
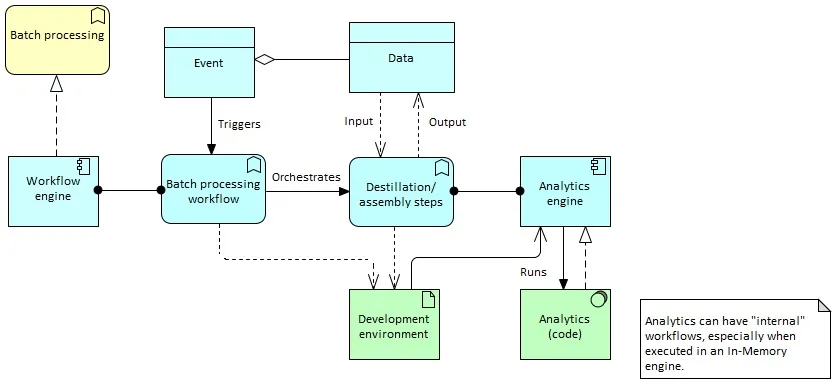
A batch processing workflow orchestrates multiple distillation/data assembly steps. Every assembly step takes data sets as input and produces other data (and/or metadata) sets as output, by executing one or more analytics with the suitable analytics engine. The (or one of the) O-BDL workflow manager(s) takes care of executing batch processing workflows (and attached distillation steps).
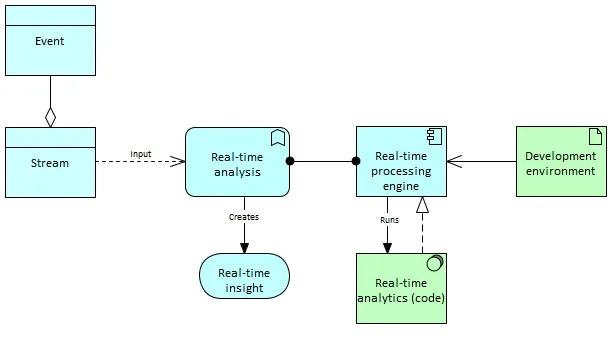
Real-time processing relies on dedicated processing engines and analytics (event processing) that leverage multiple optimizations to achieve fast-enough processing.
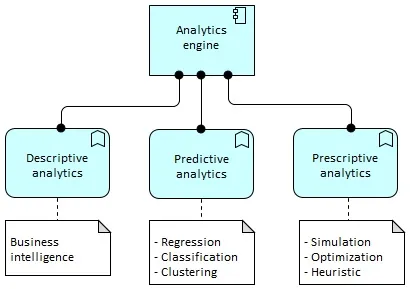
Analytics
Analytics are designed and created by the business use-case contributors. Three kinds of analytics are commonly used:
- Descriptive analytics focuses on understanding what is happening or why it is happening. Business Intelligence (BI) analytics falls in this category.
- Predictive analytics goes further by providing predictions about the probable outcome. Common prediction types are classification (identifying “clusters” of data) and regression.
- Prescriptive analytics provides insights about how to make something (e.g., a business goal) happen. More advanced techniques support this type of analytics, for instance simulation, optimization, and heuristics.
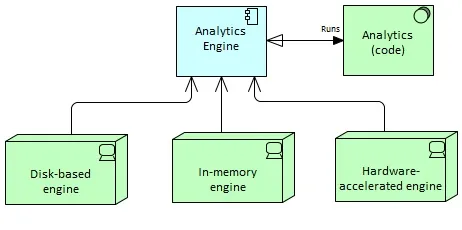
Analytics engines represent the computational frameworks that host analytics, separated into the following types:
- Disk-based engines are distributed engines that read data from disk (ideally locally on the same node but also from other nodes in the network) and write results to disk. Apache MapReduce is an example of a disk-based engine
- In-memory engines have the ability to keep data in RAM so that it’s possible to drastically speed up the processing when data sets fit in RAM (still on multiple nodes). Apache Spark is an example of an in-memory engine.
- Hardware-accelerated engines based on Graphical Processing Units (GPUs) or Many Integrated Cores (MICs) for specific analyses that can be massively distributed on thousands of small units. “Deep learning” analyses, which rely on training very large neural networks (with billions of connections) with very large data sets, can typically leverage these kind of solutions.
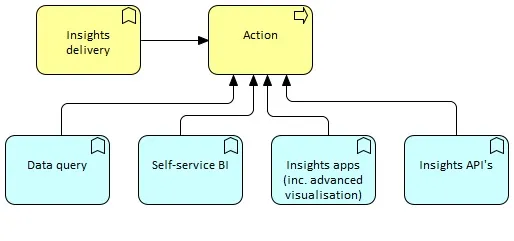
Actions
Actions can be delivered either to human end-users or to “automated” application endpoints. Common identified action types are:
- Querying data to assemble valuable pieces into consistent information. Search capabilities enter this category.
- Visualizing data queries into a self-service BI environment. These environments enable end-users to design their own “reports” that leverage simple visualization techniques (filters, charts, drill down, etc.).
- Using big data applications by an end user or application endpoint
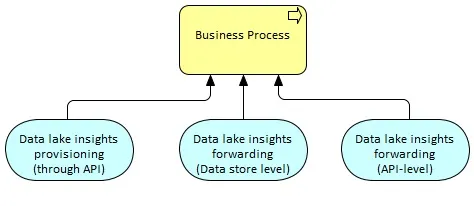
Insights delivery
Insights should be delivered outside an O-BDL in order to influence enterprise business processes, directly or indirectly (through people). Relevant ways to deliver insights at the point of action within the existing enterprise landscape include:
- Injecting insights into an external data store
- Sending messages to external applications using their native APIs
- Providing an API to extract the insight or involve an analytic to drive insight on-the-fly using data in an O-BDL
In the next (ninth and final) blog post I’ll elaborate on the O-BDL data management and operations concept.