The Open Business Data Lake Standard, Part V
Blog: Capgemini CTO Blog
In my previous blog posts (Part I, Part II, and Part III) about the ‘Open Business Data Lake Conceptual Framework (O-BDL) I introduced its background, concept, characteristics and platform capabilities. In Part IV) I compared a Data Lake with other data processing platforms. In this fifth part I’ll discuss the key concepts of an O-BDL and describes how it should work.
To understand how an O-BDL should work, the following process diagram (applying The ArchiMate® Enterprise Architecture Modeling Language) is used.
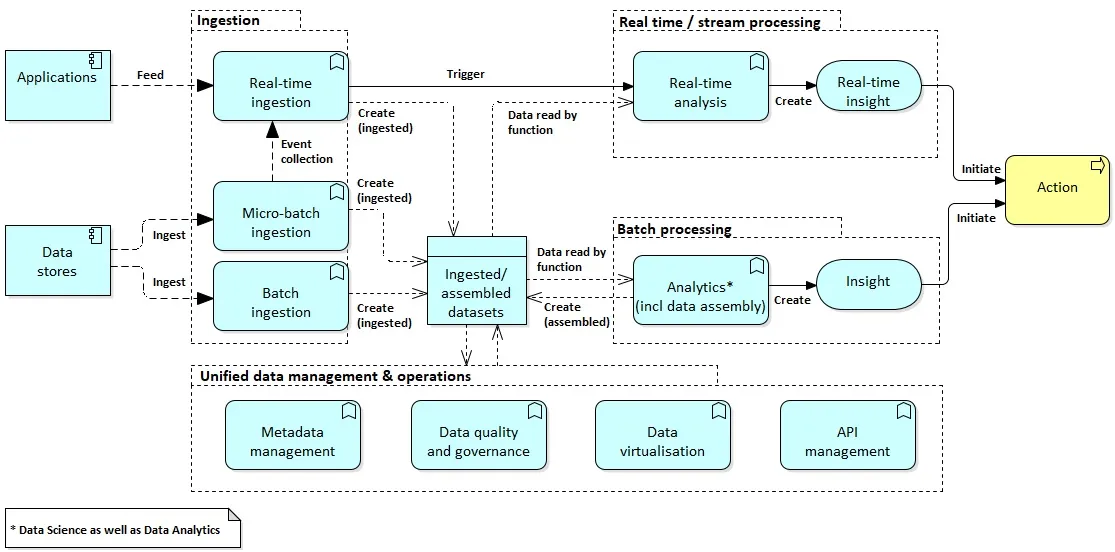
An O-BDL ingests data (batch, micro-batch as well as real-time) from other applications (through feeds) and data sources (through ingestion). Most data items (structured and semi- and unstructured) go straight into the main distributed – thus scalable – data store preserving the original structure. Some data items, however, are processed on arrival since the resulting insight is needed immediately. Data stored in an O-BDL is called data-at-rest and data that is processed without storing is called data-in-motion.
An O-BDL can generate insights from different assemblies of the ingested data. These insights can be translated into actions in multiple ways that make sense from a business point of view. A service layer takes care of delivering insights at different points of action into business processes, applications, etc.
To turn data into insights an O-BDL employs two types of data processing capabilities:
- A real-time processing capability that creates real-time insights as data is ingested
- Iteratively-designed distillation steps that progressively enrich, combine, or execute analytics with stored data to assemble new, “more valuable” datasets until it is considered a business-relevant insight
Different functions will manage the O-BDL and use of its content . The key roles involved in an O-BDL:
- The platform owner (and operator) provides (and operates) O-BDL platform services.
- The business use-case owners are responsible for the added business value of insights and actions.
- The data owners are responsible for defining and applying the proper data policy, through the unified data management services of an O-BDL.
- The business use-case contributors (e.g., “data scientists”) are responsible for discovering, experimenting with, and validating new processing capabilities (analytics) that are:
- Relevant for the business use-case
- Innovative, smart, efficient, like a positive “hack”
- Consistent with the mathematical and statistical state-of-the-art.
Now it’s clear how an O-BDL should work, it’s time to define possible business scenario’s which can make use of an O-BDL. This will be discussed in the sixth blog post.