The Open Business Data Lake Standard, Part III
Blog: Capgemini CTO Blog
In my first and second blog about the ‘Open Business Data Lake Conceptual Framework (O-BDL) I introduced its background, concept and characteristics. In this third part I want to discuss the capabilities of an O-BDL.
The O-BDL is a platform which provides a set of common capabilities that are required or useful to create new insights from data, regardless of its purpose (descriptive, diagnostic, predictive, prescriptive, see diagram below).
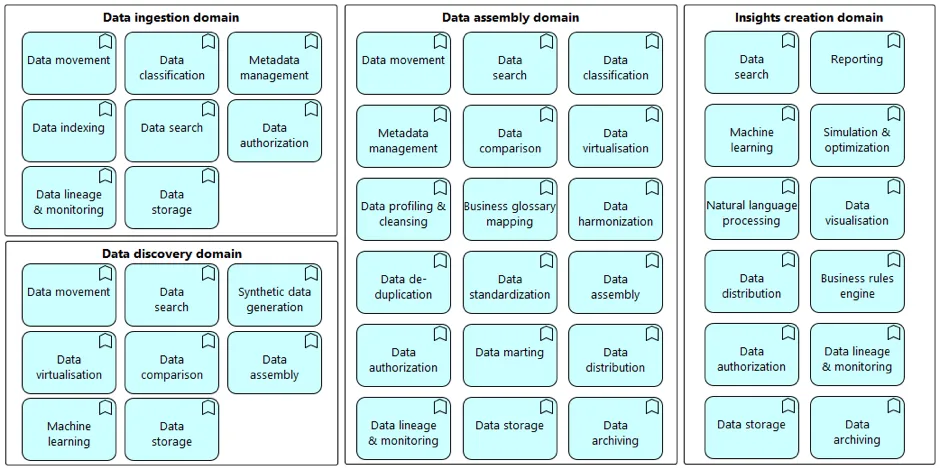
 To create these insights the O-BDL is divided into the following four domains:
To create these insights the O-BDL is divided into the following four domains:
- Data ingestion domain
- Discovery domain
- Data assembly domain
- Insights creation domain
Data ingestion domain
The goal of this domain is to ingest data/events loaded from different sources and store it ‘as-is’ (i.e. ‘schema on read’) and make it searchable. To achieve this, metadata is extracted, classified and indexed.
Data discovery domain
The goal of this domain is to discover possible and relevant data patterns. To achieve this, ingested data sets are searched, compared and assembled and stored into new data sets. If needed, synthetic data is generated and added to the assembled data set or data sets residing outside of the Data Lake are added by virtualising them. New data sets are used to define and test machine learning algorithms. The assembled data sets are stored in a format depending on the proposed usage (i.e. ‘schema on write’).
Data assembly domain
The goal of this domain is to prepare data sets to be used for creating insights. To achieve this, ingested data sets are searched, compared and assembled and stored into new data sets. If needed, synthetic data might be generated and added to the assembled data set. It might also be relevant to connect to data sets residing outside of the O-BDL by virtualising them. The quality of the data is assessed and improved (cleansing, standardisation, harmonisation, etc.), after which the data set is stored in a format depending on the proposed usage (i.e. ‘schema on write’), which can be an Enterprise Data Warehouse/Data Mart, or a SQL, key-value database, document, graph or column database. Finally the metadata is extracted, classified and indexed and the assembled data set is made available for distribution.
Insights creation domain
The goal of this domain is to create any type of insights (i.e. descriptive, diagnostic, predictive, prescriptive). To achieve this, assembled data sets are searched for and consumed within reports, algorithms and/or simulations. When data is used coming directly from user input, natural processing capabilities are required. The output can be visualised, distributed or embedded into a business process (i.e. rules engine) and will be stored in a format depending on the proposed usage (i.e. ‘schema on write’).
To keep track of changes made in the data between ingestion and actual use (by whom), data lineage and monitoring, as well as data authorization capabilities are part of the O-BDL. Finally, data archiving capabilities should be applied when data isn’t used anymore or when to comply to legislation rules.
In the fourth blog in this series I’ll position the O-BDL domains within the CRISP-DM (Cross Industry Standard Process for Data Mining) and compare the O-BDL with other data processing platforms.