
The Achilles’ Heel of AI – Training Data
Blog: NASSCOM Official Blog
We have heard this saying a lot in the context of AI – Garbage in is Garbage out. The success of AI-powered algorithms relies on data, well-labelled training data that the model is built-on. As AI becomes pervasive, enterprises across the sectors are transforming their businesses relying heavily on AI-led decision-making. A recent NASSCOM-EY survey of 500+ CXOs across four key sectors to understand the challenges they face while implementing AI, and the top areas of concern comprised Technology and data, Trust, ethics & regulations, amongst others. Enterprises are struggling with the success of their AI deployment projects despite of having a perfect model.

Image Source: CloudCover
The dataset on which the model is trained on definitely has a big role to play. If the machine learning model is train with a poor data set (garbage in), there is no surprise that the model will produce poor prediction (garbage out). The issues of trust and ethics are eventually also a function of the model results, which is dependent heavily on the dataset and the algorithm. While most of the organizations figure out the algorithm piece, the data part is something that often struggle with. Inadequate training data was pointed out as a major challenge by 36% of the CXOs as per the NASSCOM-EY survey conducted between January to March 2020.
This challenge worsened amidst the COVID-19 pandemic as AI became a ‘must-have’ technology instead of a ‘good to have’ in the increasingly contactless society. There came an unprecedented need to solve a lot of problems via AI-led decision making and not only enterprises but government also realised the importance of as well as gaps in data assets and integrated systems that are fundamental for pandemic response and reopening the economy.
Importance of Data labelling/annotation
We know that data is a critical lever of success of AI models. It is for this reason that over 80% of the time spent during AI projects is on data preparation phase including data identification, cleaning, augmentation, cleansing and labelling phases. Moreover, as training data plays a critically essential role in the success of an AI model, 25% of the time is spent specifically on data labelling, creating relevant training data for the AI model.
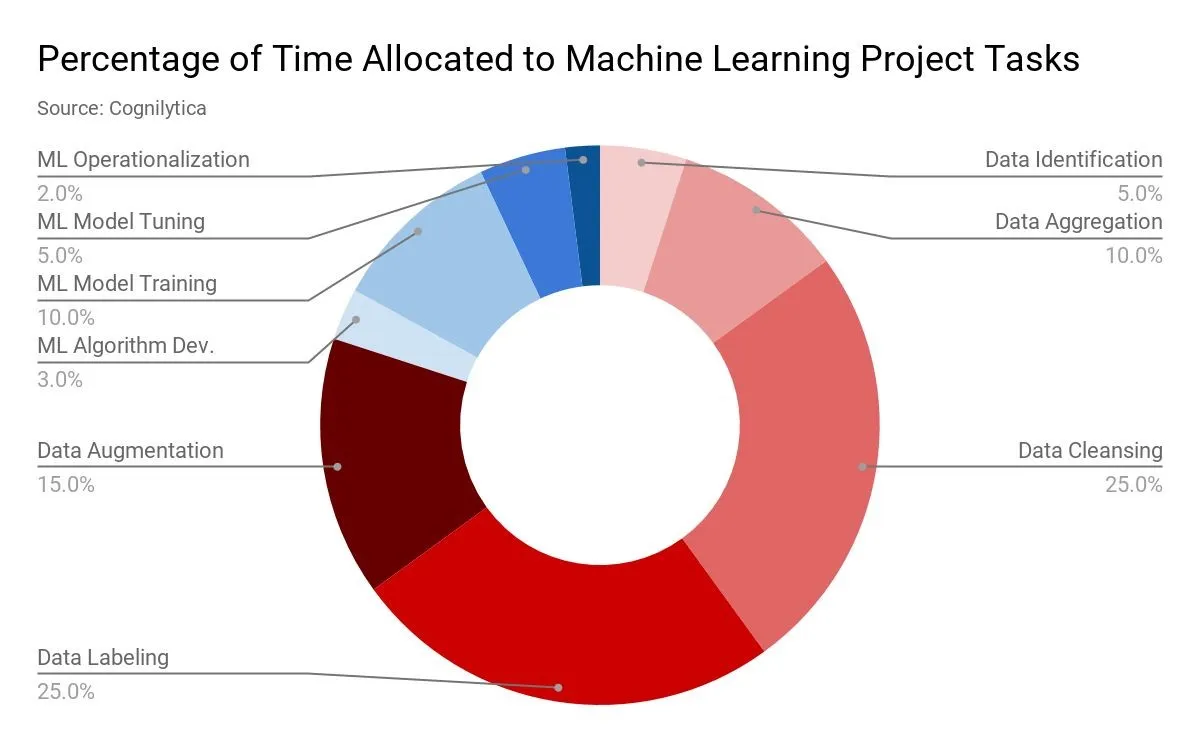
Image Source: Cognilytica
The data labelling and annotation tasks depend completely on the type of data to be labelled for the ML model and task at hand. Data annotation can be done for all data types including text, audio, image and video and across use cases from computer vision, natural language processing and content services. Some of the primary use cases comprise image classification/ tagging, speech and text labelling, sentiment analysis, conversational tagging, relevance and personalization labelling, amongst others.
As the problems that enterprises are trying to solve through AI vary, so do the data required by them – the need for training data is also contextual. The same image can be used to train an AI model to predict different things. For example, if we consider the below image and consider multiple annotation use cases.

Someone would just need to locate the number of pedestrians in the above image, while another use case might want to focus on the number plate for surveillance purpose or a third model might require to only identifying the number of non-yellow cars. Depending on the use case, the type of annotation also varies from a simple bounding box to a precise polygon annotation to even more complex types. The requirement varies hugely with different data types and the use cases.
Concluding Remarks
The demand for well-labelled training data is huge and with increasing advancements in AI across sectors specifically like Automotive, Retail, Healthcare and BFSI, the demand is going to increase exponentially at least over the next few years.
Watch out for my next article that delves deeper in the data annotation space.
References
[1] https://www.kdnuggets.com/2019/10/data-preparation-machine-learning-101.html
[2] https://cldcvr.com/news-and-media/blog/clean-data-the-foundation-of-effective-machine-learning/
[4] https://lionbridge.ai/articles/an-introduction-to-5-types-of-image-annotation/
[5] https://quantanite.com/data-labelling-the-power-behind-artificial-intelligence/
The post The Achilles’ Heel of AI – Training Data appeared first on NASSCOM Community |The Official Community of Indian IT Industry.