Taking R from Prototype to Production
Blog: Capgemini CTO Blog
The Problem: anticipating bugs
R is a wildly popular language in the Data Science community. The language’s success has come from the provision of a deep and broad statistical tool kit in a free, open-source language with a large community behind it. Some indexes of programming language popularity even place the R language as high as fifth, below C++, Python, Java and C[1].
Getting data cleaned, into a model, and producing results can be achieved quickly in R. It is one of the language’s greatest assets, but this comes at a cost; making an R program that works every time is an arduous task. This is a critical feature of a code base that is to be put into production.
Say I wanted to forecast a time series which I have in an Excel (.csv) format, all I would need to do is this:
library(forecast)
test.data <- ts(read.csv("time_series.csv"), frequency = findfrequency(test.data))
forecast.result <- forecast(auto.arima(test.data))
plot(forecast.result)
In just four lines of code I have created a simple program that can forecast a time series with no parameter specification. As a reward for my short labour I get a fancy plot with an accurate forecast:
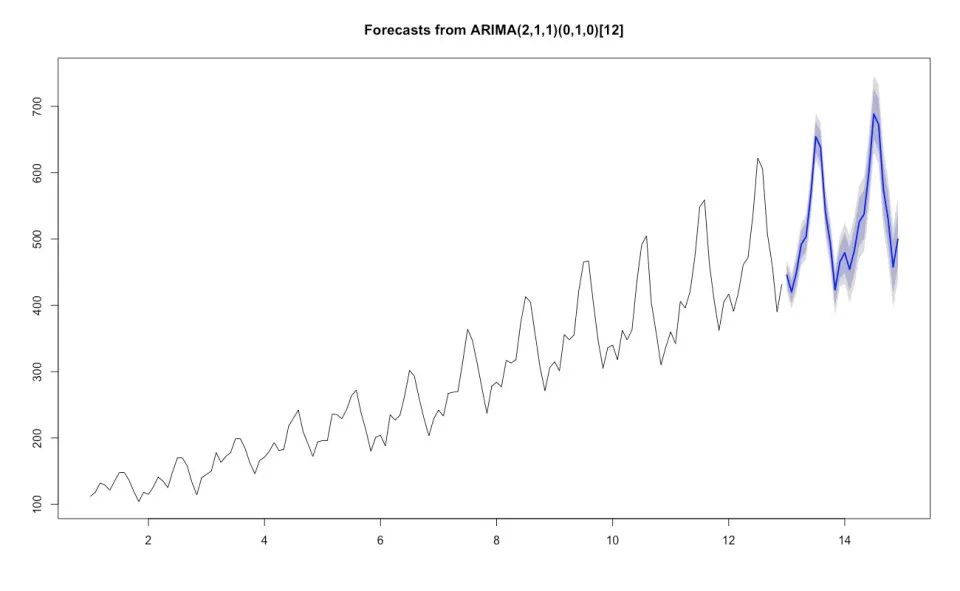
Say this code gets put into production, with a new data set provided each day. What would happen to the program should a value go missing and the data provided contains the word “missing” for the first value in the data with all other values remaining the same? This is enough to break our program, as the following result is produced:
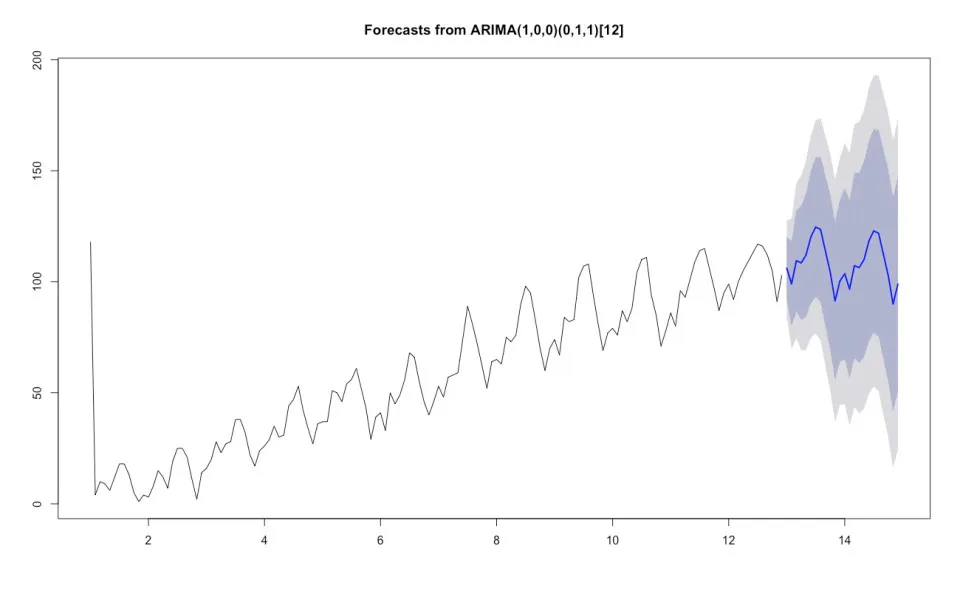
Not only is the forecast completely wrong, the values of the time series values are totally incorrect. Worse still, the program hasn’t given an error message or even a warning, it has simply assumed all is well and provided a totally invalid result.
Why has this happened? The character value “missing” means that R has read the entire data set as a text values rather than numeric values. By default, R converts text to a data type known as factor, which assigns a number to each unique data point. The model has used this index, not the actual time series, for the forecast.
This shows how a prototype in R can fail when brought into production. While these are not problems unique to R, they are problems that are harder to solve in R.
Problems such as these are hard to avoid and fix in R due the nature of the language. There is no static typing outside of the S4, most CRAN packages lack unit testing, the unit tests CRAN packages must pass have significant problems[2], parallel implementations only work on some platforms and the S3 and S4 object orientated functionality is clunky. Purdue’s study of the language said it best:
“For robust code, one would like to have less ambiguity and would probably be willing to pay for that by more verbose specifications, perhaps going as far as full-fledged type declarations. So, R is not the ideal language for developing robust packages.”[3]
Serious questions follow form that statement. Can R provide business value in the long run? What are the best use cases of R? Why is R so popular? Should you even use R?
To the last question, I would say yes, emphatically. A language where you can get a result quickly is highly valuable. I’ll address how you can future proof that result below.
The Solution: adopt best practices early
The previous section talked about some of the weaknesses of the R language, showing the ease at which you can build prototypes which are feature rich but break easily in production. Here, I’ll show how by using good practices from the beginning solves the problems that R presents and make it an invaluable tool when bringing a product to market.
In my experience, it is possible to take R beyond the prototyping stage by using good practices from the beginning. These are practices that are found across all computing languages but are all too often left behind in R code.
- Adopting a coding standard early
Follow a common syntax, the google R style guide is a good starting point. If the project likely to be large implement it as a package sooner rather than later. Avoid using packages with similar functionality, for instance avoid using both data.table and dplyr, use one or the other. This is particularly important when working in teams. - Unit tests
The loosely typed structure of R code lends itself to packages breaking easily when altering code. Unit tests provide good protection against this, and can easily be implemented when your code is structured as a package. - Recognizing good packages from bad
Getting a package onto CRAN merely requires that your code passes check, which is a pretty low benchmark. Reading through the package code and understanding how each package works under the hood is good practice. - Breaking apart components for later development in other languages
Breaking apart your code into functions, even when only scripting, makes the code modular and more manageable as the project scales. It also means that more computationally intensive components can be handed over to other languages with RCPP or rJava. - Using R as a wrapper for other languages
If you know C++ or Java, then it may be more effective to write larger ecosystems in those languages. This way R can act as an effective wrapper for others to quickly implement your code on other systems. This has been done very effectively by some R packages written by Google and Facebook (see BOOM and prophet respectively).
References
[1] http://spectrum.ieee.org/computing/software/the-2016-top-programming-languages
[2] http://stackoverflow.com/questions/9439256/how-can-i-handle-r-cmd-check-no-visible-binding-for-global-variable-notes-when
[3] Morandat, Floréal, et al. “Evaluating the design of the R language.” European Conference on Object-Oriented Programming. Springer, Berlin, Heidelberg, 2012.