Site reliability engineering
Blog: Capgemini CTO Blog
Problem statement – Due to the current state of how we monitor, alert, and log our digital ecosystem, it takes more time to detect, diagnose, and fix production incidents. Communication and status updates on production incidents are not reliable or timely. Business continuity and disaster recovery capabilities are even more important today as we are betting more on digital experiences.
SRE is causing disruption in quality engineering. In the past, the focus of quality engineering was on shift-left testing, especially requirements review, functional, and non-functional testing. With SRE, the focus is shifting towards shift-right, or production testing.
DevOps vs SRE
One obvious question concerns the crossover between SRE and DevOps, and rightly so. There is a significant overlap between them as they both tend to address the silos between “dev” and “ops.” Also, in terms of practices followed, there are numerous parallels. However, the approach and objectives are quite different in both cases.
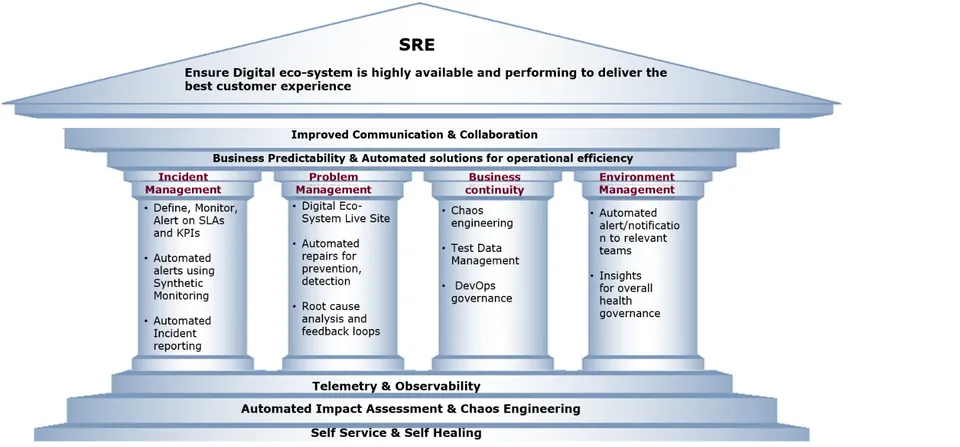
SRE pillars
SRE is focused on four delivery pillars:

Incident management: The main goal of this pillar is to reduce mean time to detect (MTTD) and mean time to resolve (MTTR) to desired numbers. Setting up a single pane of glass of telemetry and observability makes investigating and diagnosing problems easier. Defining the SLOs and SLIs at each service layer and customer experience web site level are the key milestones. Availability, latency, and system throughput are the KPI needs to be tracked.
Problem management: This pillar deals with root cause analysis and prevention and self-healing mechanisms in the digital ecosystem. SRE dashboards and data-driven insights provide information about the overall service health, which helps us to identify the service availability for given amount of time during production monitoring
Environment management: Business continuity and disaster recovery are the core areas of focus for this pillar. Security, compliance, data management, and DevOps governance will also be part of by this pillar. Chaos engineering is a disciplined approach to identify vulnerabilities in systems in the production environment. It is implemented to check the system’s reliability, stability, and ability to survive in unstable and unexpected conditions.
Outage communications: Curated communication of production incidents, software releases, scheduled and unscheduled maintenance. The goal of this pillar is to use all channels to clearly communicate on system health and incident resolution
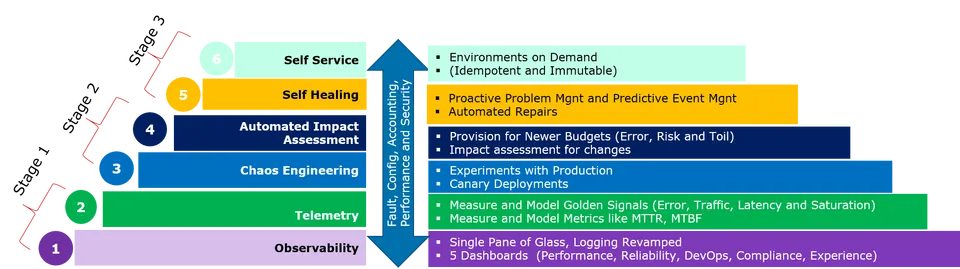
SRE stages
SRE can be implemented in a phased manner. The below diagram depicts the three stage approach:
SRE Jumpstart
SRE Jumpstart consists of aspects such as:
- Defining SLOs and SLIs
- Define monitoring and assess monitoring tools for service observability
- Define ways of working and appropriate DevOps model
- Define DevOps tool chain
- Define SRE runbook tailored for a client context.
For more information on site reliability engineering, please contact Genesis Robinson @ [email protected]