Site Reliability Engineering: Demystifying SLIs, SLOs and error budgets
Blog: Capgemini CTO Blog
SLIs, SLOs, and SLAs are unique to SRE and set it apart from already-existing IT operations paradigms such as DevOps and ITIL. To see why, let us begin by re-examining the definitions as laid out in the Google SRE book.
SLI is a service-level indicator: a carefully defined quantitative measure of some aspect of the level of service that is provided. For example, request latency – how long it takes to respond to a request.
Service-level objective: a target value or range of values for a service level that is measured by an SLI. A natural structure for SLOs is thus SLI ≤ target, or lower bound ≤ SLI ≤ upper bound. For example: The SLO that our average search request latency should be less than 100 milliseconds.
SLAs are service-level agreements: an explicit or implicit contract with your users that includes consequences of meeting (or missing) the SLOs they contain. The consequences are most easily recognized when they are financial – a rebate or a penalty – but they can take other forms.
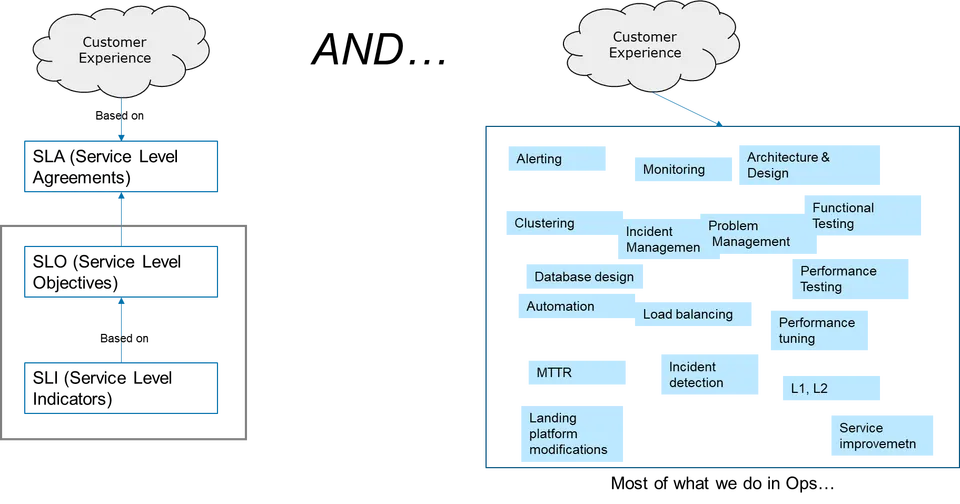
Additionally, we know that SLAs are a direct or indirect measure of customer experience (given that it is to begin with such an abstract concept to measure).
So pictorially it can be represented as below:
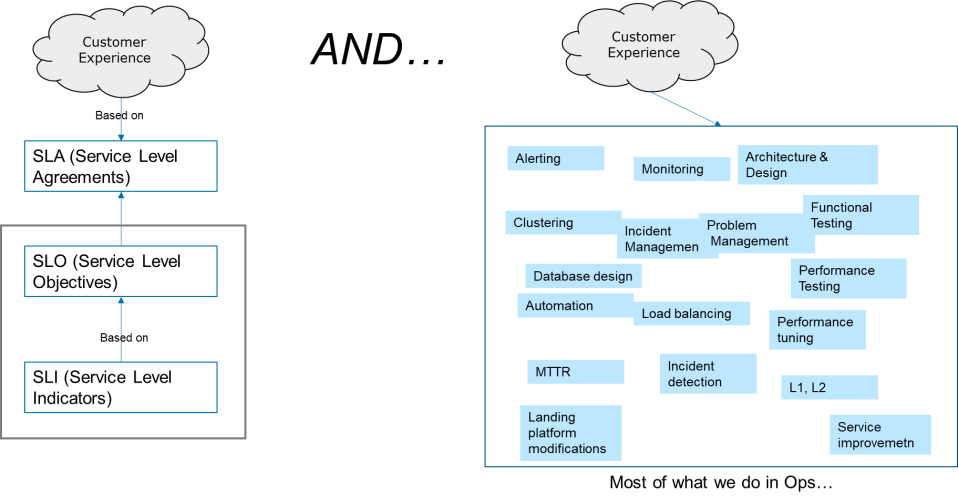 And therefore…
And therefore…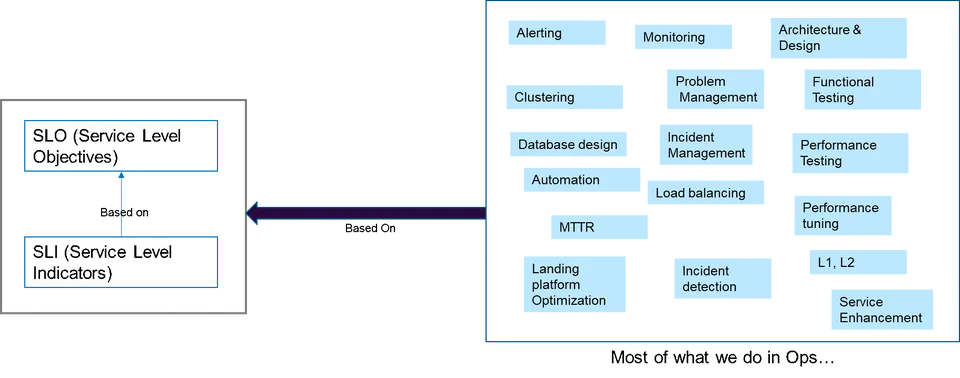
So what are those SLIs, then?
Since SLIs need to cover the entire landscape of an engineering platform, they can be broadly classified into:
- User-interfacing SLIs: All services or applications that the user interacts with in a requests-response e.g.: All REST APIs serving web applications, web applications, mobile apps, desktop applications
- Data-processing SLIs: All services or processes that crunch data on implicit or explicit customer requests e.g.: Data streaming services, batch applications, ETL tools, event-sourcing services, etc.
Data storage-related SLIs such as durability have been left out for now.
User interfacing SLIs
- Availability: The proportion of valid requests served successfully. For example, X% of the http GET request to a hypothetical/end-point should return a 200-status code.
- Latency: For synchronous services; the proportion of valid requests served faster than a threshold. For asynchronous services; the proportion of work-queue tasks completed faster than a threshold. An example of the former, the 90th percentile of all http GET requests to a hypothetical/end-point should be < X seconds.
- Quality: The proportion of valid requests served without degrading quality. The definition of quality varies from context to context, one example being the quality of response measured in terms of a proportion of requests returned with a confirmation ID.
Data processing SLIs
- Throughput: The proportion of time where the event processing rate is faster than a threshold. For example: Transactions/sec of a hypothetical/service should be greater than X, 99% of the time.
- Data freshness: The proportion of valid data updated more recently than a threshold. For example: 99 % of a hypothetical/service should be updated more recently than X minutes.
- Data correctness: The proportion of valid data producing correct output. For example: 99% of room inventory searches should produce correct output.
- Coverage: The proportion of valid data processed successfully. For example, 99.99% of the hypothetical/service updates should be processed successfully.
But, wait a minute…
“Customer experience is highly dependent on factors such as usability and feature richness. How are those addressed by the SLIs?”
They are not. But neither are these customer experience factors influenced by IT operations. SRE is focused on processes impacting IT operations and thus, the aforementioned SLIs deal only with those. Are the defined SLIs by themselves complete? No. One can define specific SLIs as per their need. However, a helpful guideline is to ensure that the defined SLI has a direct bearing on the customer experience. For example, infrastructure availability could be defined as an SLI. In fact, it has been given “SLI status” for the longest time. However, what impacts customer experience more, whether a VM is available 99 % of the time or whether 99% of the requests to the web application hosted by the VM are successfully served. Which is why from an SRE perspective, in this case, infra availability is not considered as an SLI but as a metric influencing an SLI.
Another aspect to bear in mind is that SLIs and their SLOs are defined and determined respectively to be actionable by the IT operations team. For instance, one can define a SLI measuring web traffic throughput i.e. web request per second to a hotel room booking website. This metric is of extreme importance from a business operations sense. But is it an SLI? What action can be performed by the IT operations team to increase web traffic in the past few months of the pandemic? Can there be a post-mortem conducted based on the lack of web traffic and services improved? It is difficult to see that happen. The action that can be taken are more in terms of giving guests assurance on how safe a visit to the hotel will be. Probably actions in terms of offering discounts or campaigns reassuring hospitality guests could be taken, which are marketing and sales driven, out of IT’s circle of influence. Hence, tracking the traffic metric offers great insight business operations insights but it is not an SLI from an IT operations sense.
But what does this mean practically?
Before we address that, let’s look at some common scenarios that IT operations struggle with. If we were a fly in the wall listening to voices in IT ops meetings, this is what we will hear most frequently:

Let us see how SLIs and SLOs help address the above challenges by simulating a scenario.
Service: Client facing REST API called hypothetical/end-point
SLI: Availability specified as: X% of the http GET request to a hypothetical/end-point should return a HTTP response code less than 500.
SLO: 99.9 %
Based on historical data, let us presume we know that the service hypothetical/end-point is likely to receive 1 million GET requests in the month of September. This means that for an SLO of 99.9 for the availability SLI, the number of responses with HTTP code greater than 500 should not be greater than, 0.001 * 1,000,000 = 1,000.
In other words, 1,000 September’s error budget for the service. Therefore, if in the first two weeks of September, there have been already 900 requests with an HTTP response greater than 500, the operations team knows that this service is in danger of breaching the monthly SLO. It puts them in a proactive position by intimating the engineering team that any more releases would introduce further volatility in the system. This is one way to get ahead of the curve.
It also forces the engineering teams to analyze ad-hoc releases more carefully. With widespread usage of automated CI/CD pipelines, there is the temptation for the engineering teams and business to rollout as many deployments as possible. With impact on the SLI being quantitatively certain, it builds in more rigor and provides motivations for teams to follow DevOps governance tenets around testing coverage and completion, thus discouraging ad-hoc releases.
Now, let’s take a scenario where the engineering team goes ahead with a release, despite having erased its error budget for the month. This is a practical scenario, since SLOs can be occasionally compromised for functional releases which are more important for the business. But this also means, each transgression gets recorded and can be historically analyzed. If there are services that are constantly being forced to compromise availability due to new releases, it gives the operations team the opportunity during post-mortems to highlight the true reasons for the SLO not being met. It would then be a business decision to operate at a lower SLO for a brief while or to scale back on functional releases to ensure SLO compliance.
And lastly, due to the inflexibility accrued by legacy systems over time, it becomes difficult for them to deliver on stringent SLOs. With SLO monitoring, it becomes easier to quantify this inability despite the operational and engineering overheads spent to get these applications to comply to the SLO. A trend line of an unsatisfactorily performing SLO with comparative efforts spent on upkeep gives enough quantitative context for legacy modernization and phasing out older systems.
Conclusion
SLIs, SLOs and error budgets provide a quantitative framework to align IT operations with customer experience and thus setting common ground across engineering, operations and business team to arrive at decisions fully aware of their consequences. Capgemini’s SRE offer contextualizes this quantitative framework for a specific IT landscape accelerating the customer roadmap for SRE adoption.
To know more about Capgemini’s SRE offer please reach out to Aliasgar Muchhala or Sanathkumar Pasupathy.