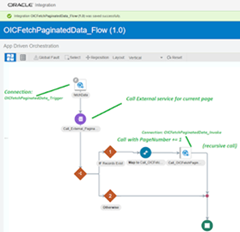

Recursive calls in Oracle Integration Flows (Scenario: Paginated API calls for large Data Sets) by Jang-Vijay Singh
Blog: PaaS Community

A number of use-cases can be implemented cleanly using a recursive approach. This post is not to debate the pros and cons of recursion versus looping but provides a simple approach to achieve this.
For scenarios such as the ones listed below, and possibly more, this approach is quite efficient, concise, maintainable, and most importantly, it is highly scalable. It also leaves a smaller runtime footprint with a smaller execution time per instance than a looping flow instance. This also makes error handling easier as I will describe later.
- Polling (continuously monitoring an FTP location, a database, or an API output)
- Paginated API’s (when the target system exposes an API with a paginated* interface such as the eBay findProducts operation)
- Retryable flows
Paginated Calls
Many software systems store large sets of data. For instance, a vendor might have hundreds of thousands of products and product-prices listed on EBay or an eCommerce store. They might have millions of transactions in their PayPal account.
There might occasionally be legitimate scenarios to fetch all of this data. The software system can provide various interfaces to export such data in bulk. Such a bulk data export interface could be raw data files, access to a database, but also a standard API like a Rest Service.
For reasons of performance and good practice, such Rest API’s (typically a GET operation) would limit the amount of data returned in any one call by using a pagination strategy. An eCommerce store could list hundreds of thousands of products for instance, and it wouldn’t be appropriate to return such a large data set in a single call. A pagination strategy would involve setting parameters like pageNumber and pageSize. Read the complete article here.
For regular information on Oracle PaaS become a member in the PaaS (Integration & Process) Partner Community please register here.
![]() Blog
Blog ![]() Twitter
Twitter ![]() LinkedIn
LinkedIn ![]() Facebook
Facebook ![]() Wiki
Wiki
Technorati Tags: SOA Community,Oracle SOA,Oracle BPM,OPN,Jürgen Kress
Leave a Comment
You must be logged in to post a comment.






