

Process Mining in Healthcare — Case Study No. 1

In a previous post, I had written about the challenges of applying process mining in the healthcare domain. And I had promised to follow-up with a summary of existing case studies in this area. Here is the first one.
The study was performed by Ronny Mans and his fellow researchers in a large academic hospital in the Netherlands. You can read the full details here in this paper.
Process and data
As discussed earlier, healthcare processes are
-
complex,
-
flexible, and
-
many disciplines need to work together,
-
often based on independently developed IT systems.
As a result, there is little insight into what happens in a healthcare process for a group of patients with the same diagnosis. But process insight is needed to deliver high quality care while at the same time reducing costs.
Process mining can be used to extract process knowledge from event logs. The goal of the study was to obtain meaningful information about so-called careflows (typical paths followed by particular groups of patients).
The subject of study was a gynecological oncology process. The raw data contained information about a representative group of 627 gynecological oncology patients treated in 2005 and 2006, for which all diagnostic and treatment activities had been recorded in a billing system for financial purposes. Different departments are involved in this process, including gynecology, radiology, and several labs.
Challenges
One of the challenges the researchers faced was that for each activity it was only known on which day the service had been delivered. So, there was no information about the time of the start and completion of activities, and therefore events which happened on the same day could not be ordered properly.
Furthermore, the log contained 376 different event names for activities. This shows that they were dealing with a non-trivial careflow process. This high number of different, low-level activities was reduced by a pre-processing step in which:
-
The log was filtered by removing all the detailed lab activities and only keeping the initial lab event, where the samples were offered to the lab, as a representative.
-
The log was aggregated by summarizing events that happened within one department, so for example ‘echo abdomen’, ‘thorax’ and ‘CT brain’ were just represented as ‘radiology’.
The result was an event log with less than 60 different activities across multiple departments, which was then used for the process mining study. No previous knowledge about the care process was used. This means that no existing process model was used to guide the discovery, and no workshops or interviews were performed. Just the preprocessed data from the billing system of the hospital were used for the analysis.
Process mining results
First, a process model was discovered using the Heuristic miner, because it is able to focus on the main process flow. Because of the complexity of healthcare processes it would be difficult to show every detail of the behavior appearing in the process log.
The figure below shows the discovered process model, which is still fairly complex.
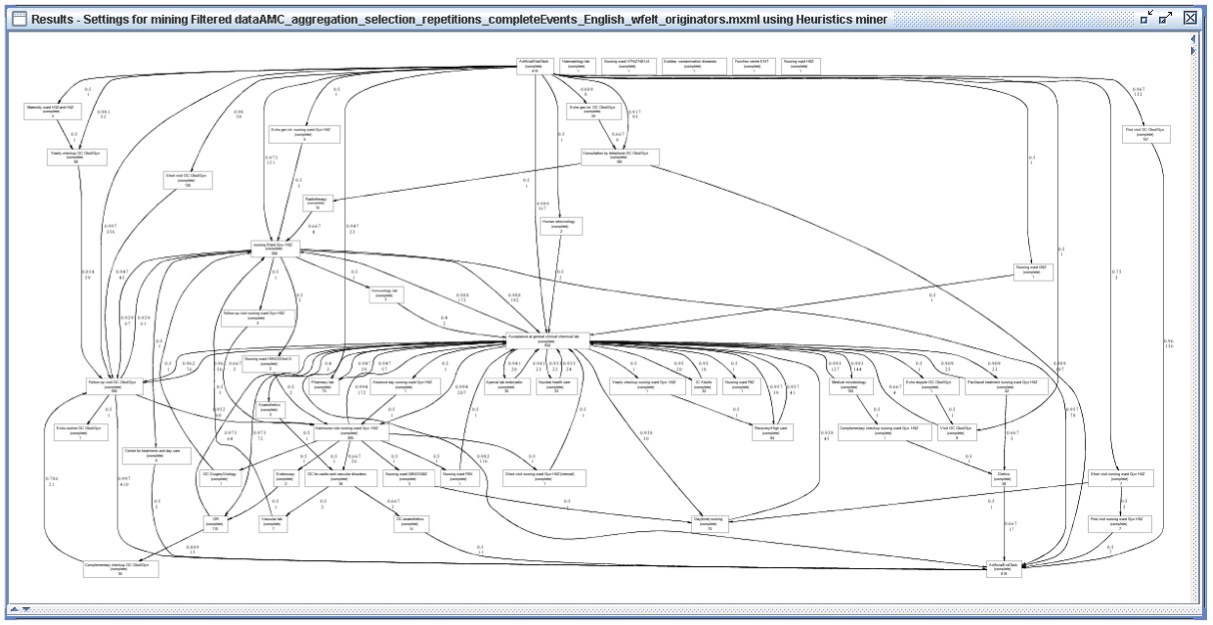
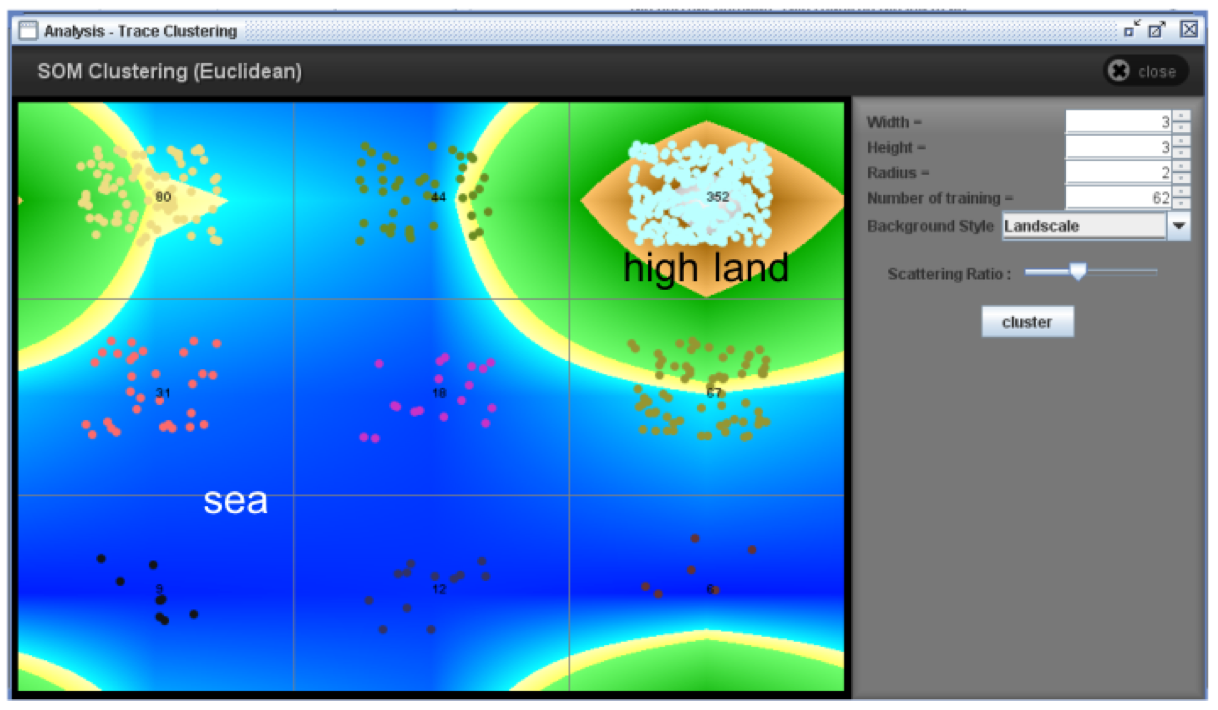
To reduce the complexity, trace clustering techniques were used. Trace clustering breaks up the log of all 627 patients into several, more homogeneous sub groups. So, those patient flows that followed a similar path were grouped together.
The picture below shows a visualization of the used SOM (Self Organizing Map) clustering algorithm. The nine cells represent the nine clusters obtained from the log. Each dot represents one instance (one patient), and all instances in the same cell belong to the same cluster. The figure also shows a contour map based on the number of instances in each cell: Clusters with many similarities are visualized as high land, and there are clusters with exceptional cases (sea).
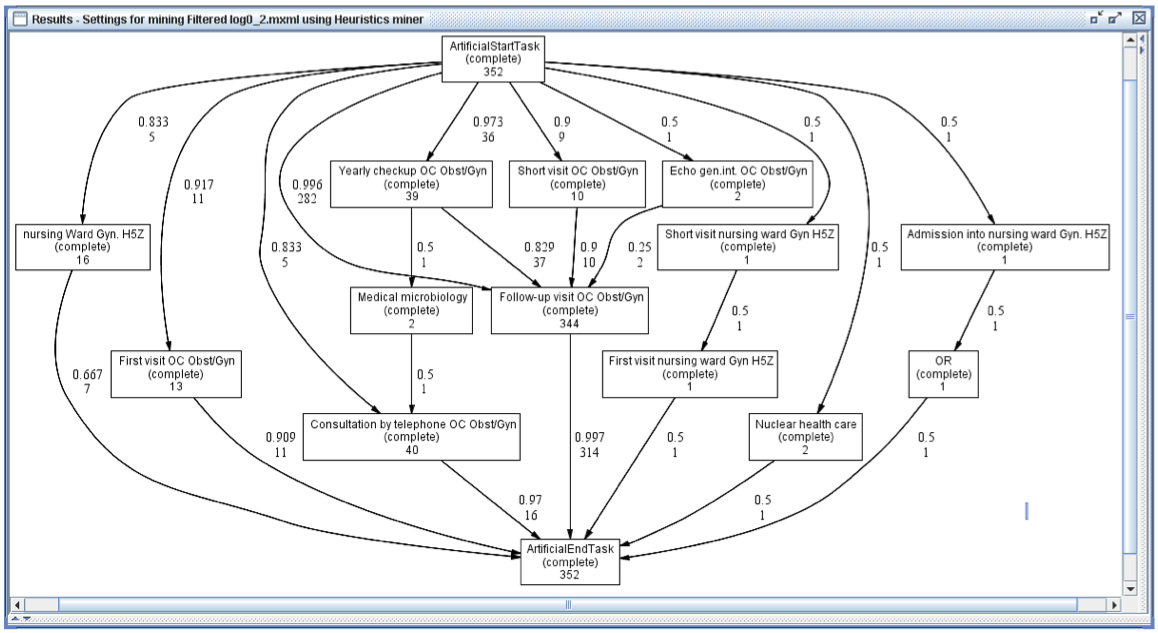
The process model below shows the process flow for all patients in the biggest cluster (with 352 cases). The result is much simpler than the model above. A closer inspection of this main cluster by domain experts confirmed that this is indeed the main stream followed by most gynecological oncology patients.
Also the organizational perspective was explored to gain insight into how the departments interact with each other in this process. Below, a social network is shown, in which each bubble represents one department. The more activity that took place in the department for the 627 patients, the larger is the bubble.
An arc indicates that patients have frequently moved from one department to the other in subsequent activities. Only the most frequent transfers between the departments shown to highlight the most dominant interactions.
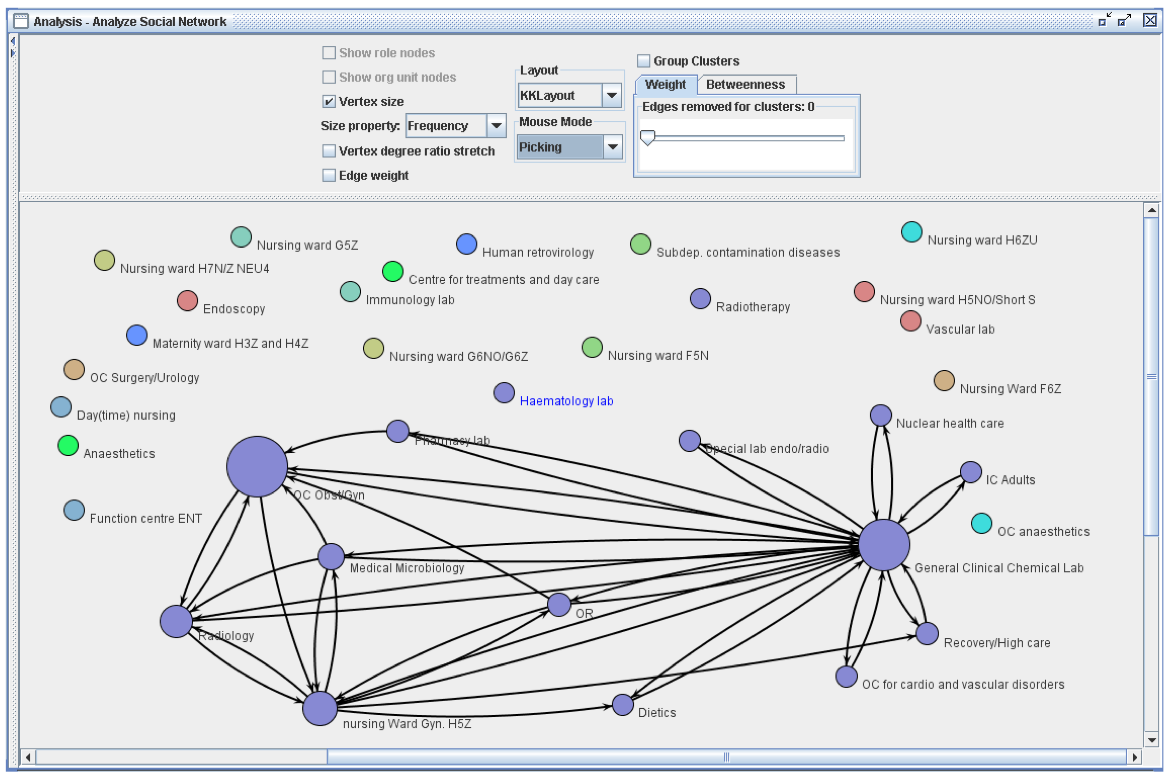
The picture reveals that the general clinical chemical lab is highly involved in the process and interacts with many departments.
When the results were presented to the people in the hospital, they were surprised about the strong collaboration with the dietics department. In fact, patients who undergo several chemotherapy sessions often need to visit the dietician. However, this was not immediately clear to everyone and illustrates the value of creating transparency using process mining.
Lessons learned
-
The unstructured and complex nature of healthcare processes poses a challenge for process mining techniques. Additional methods such as filtering or clustering need to be used in a pre-processing step.
-
The study shows that it is possible to derive understandable models for large groups of patients. This was also confirmed by people of the hospital.
-
In the hospital, a manually created flowchart for the diagnostic trajectory of the gynecological oncology healthcare process was available. The process mining results results were comparable to this flowchart, but despite the preprocessing a lot less effort was needed to obtain them.
Some of you are currently analyzing the BPI challenge log, which is also a healthcare process. Have you seen similarities, and were you able to apply similar methods? Let us know in the comments.
Leave a Comment
You must be logged in to post a comment.






