
OpenText Analyst Summit 2020 day 2: content services
Blog: Column 2 - Sandy Kemsley
Fred Sass, Marc Diefenbruch and Michael Cybala presented a breakout session on the content services portfolio. OpenText has two main content services platforms: their original Content Suite and the 2016 acquisition of Documentum, both of which appear to be under active development. They also list Extended ECM as a “content services platform”, although my understanding is that it’s a layer that abstracts and links Content Suite (and to a lesser extent, Documentum) to exist within other business workplaces. I’m definitely not the best source of information on OpenText content services platform architecture.
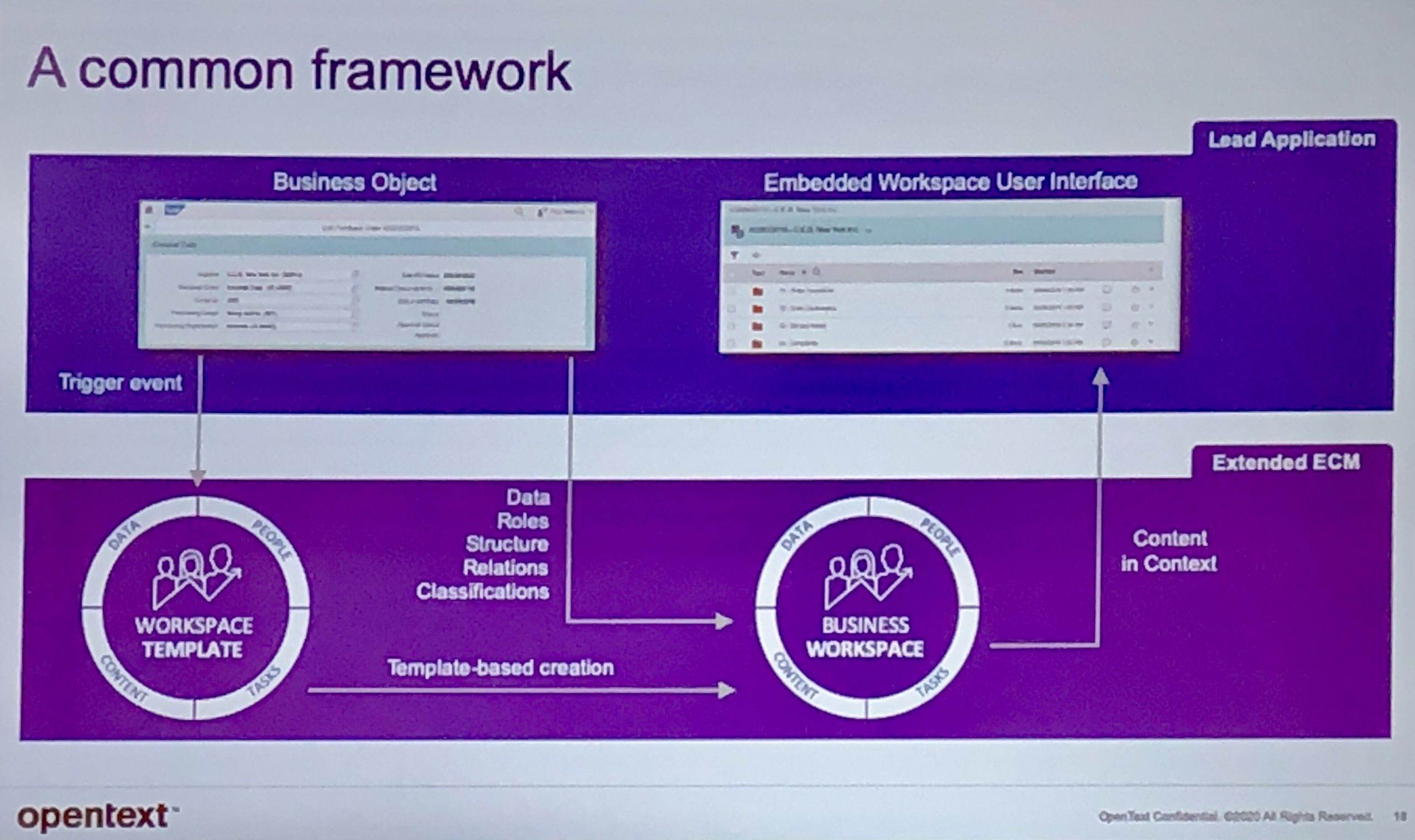
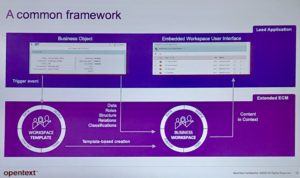
In many cases, their Content Suite is not accessed via an OpenText UI, but is served up as part of some other digital workplace — e.g., SAP, Salesforce or Microsoft Teams — with deep integration into that environment rather than just a simple link to a piece of content. This is done via their Extended ECM product line, which includes connectors for SAP, Microsoft and other environments. They are starting to build out Extended ECM Documentum to allow the same type of access via other business environments, but to Documentum D2 rather than Content Suite. They are integrating Core Share in the same way with Salesforce, allowing for secure sharing of content with external participants.
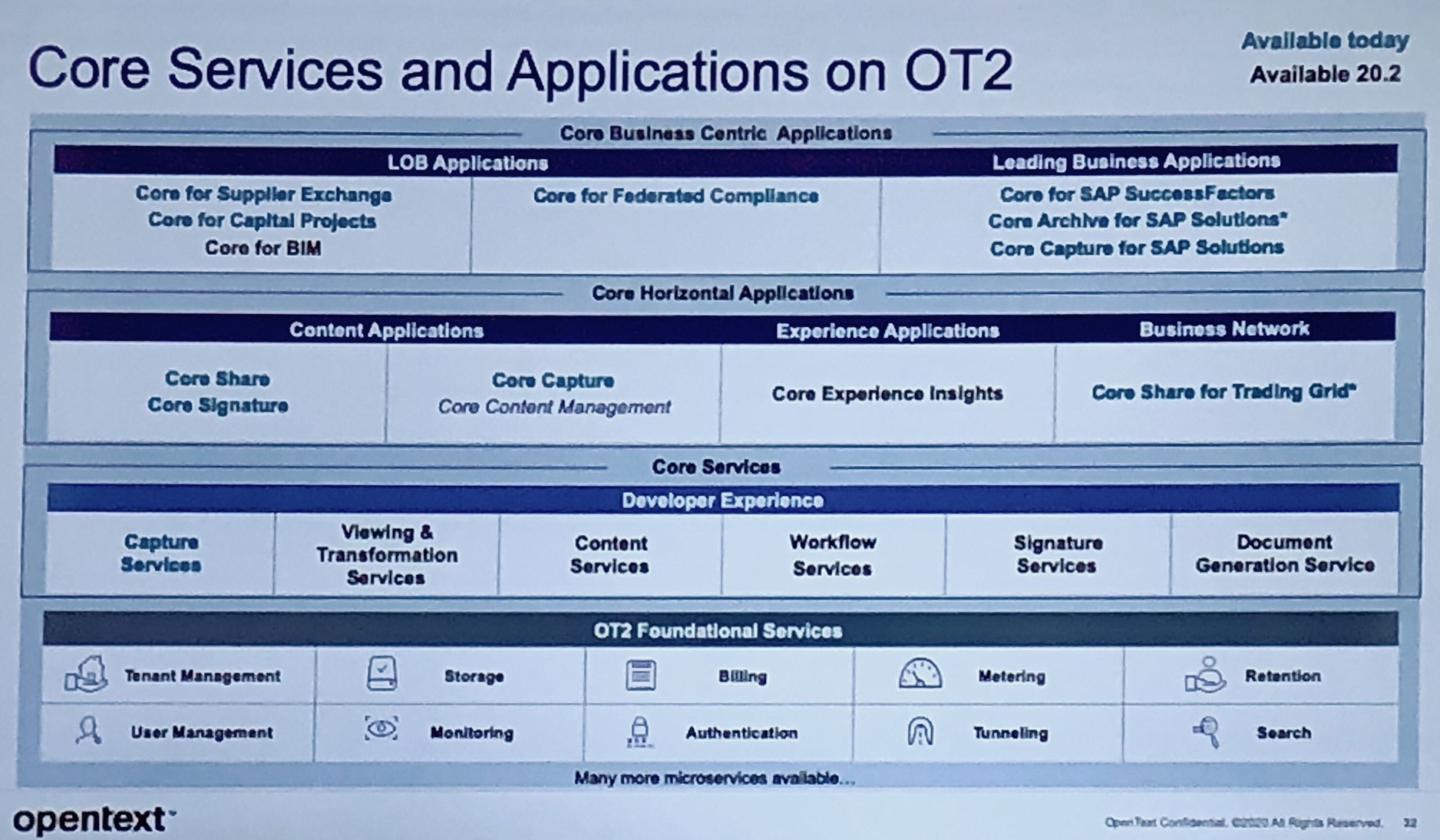
They discussed the various cloud options for OpenText content (off cloud, public cloud, managed services on OpenText private cloud, managed services on public cloud, SaaS cloud), as well as some general benefits of containerization. They use Docker containers on Kubernetes, which means that they can deploy on any cloud platform as well as an on-premise environment. They also have a number of content-related services available in the OT2 SaaS microservices environment, including Core Share and Core Capture applications and the underlying capture and content services. Core has been integrated with a number of different SaaS applications (e.g., SAP SuccessFactors) for document capture, storage and generation.
The third topic covered in the session was intelligent automation, including the type of AI-powered intelligent categorization and filing of documents with Magellan. We saw a demo of Core Capture with machine learning, where document classification and field recognition on the first pass of a document type were corrected manually, then the system performed correct recognition on a subsequent similar document. A second demo showed a government use case, where a captured document created a case management scenario on Extended ECM that is essentially a template-based document approval workflow with a few case management features including the ability to dynamically add steps and participants. As we get a bit deeper into the workflow, it’s revealed to be OpenText Process Suite, as part of AppWorks.
Lastly we looked at information governance, with a renewed interest due to privacy concerns and compliance-related legislation. They have a new solution, Core for Federated Compliance, that provides centralized records oversight and policy management over multiple platforms and repositories. It’s currently only linking to their own content repositories, but have some plans to extend this to other content sources such as file shares.
There’s another breakout plus a wrap-up Q&A with the executive leadership team, but this is the end of my coverage of the 2020 OpenText Analyst Summit. If something extraordinary happens in either of those sessions, I’ll tweet about it.
Leave a Comment
You must be logged in to post a comment.






