

How To Deal With Incomplete Cases in Process Mining

This article previously appeared in the Process Mining News. Sign up now to receive regular articles about the practical application of process mining.
Before you start with your process mining analysis, you need to assess whether your data is suitable for process mining and check your data for data quality problems (see also our Data Quality series here). Afterwards, one of the next steps is to understand how you can differentiate between complete and incomplete cases in your process.
An incomplete case is a case where either the start or the end of the process is missing. There can be different reasons for why a case is incomplete, such as:
-
Your data extraction method has retrieved only events in a certain timeframe. For example, let’s say that you have extracted all the process steps that were performed in a particular year. Some cases may have actually started in the previous year (before January). Furthermore, some cases may have started in the year that you are looking at but continued until the next year (after December). In this situation, you will only see the part of these cases that took place in the year that you are analyzing.
-
Some cases have not finished yet. Even if you have extracted all the data there is, some of the cases may not have finished yet. This means that, if you are extracting your process mining data today, some of the cases may have started recently and did not yet progress until the end of the process. They are still somewhere in the middle. If you would wait for a few weeks with your data extraction, then these cases would probably be finished, but then there might be new ones that have just recently started!
-
Some cases might never finish. You may have a clear picture of how your process should go. But a customer might not get back to you as you expected, a supplier might never send you the data that was needed to sign them up, or a colleague might close a case in an unexpected phase, because there was an error, a duplicate or another problem with it detected. These cases do not end at any of the expected end points, but they will never be finished even if you waited for ages. The same can be true for the start points.
Looking for incomplete cases is a standard step that you should always take before you dive into your actual process mining analysis. In this four-part series, we will give you clear guidelines for how to deal with incomplete cases.
The following topics will be covered:
-
Why incomplete cases can be problematic (this article)
Let’s get started!
Why Incomplete Cases Can Be Problematic
At first, it might not be obvious why incomplete cases are a problem in the first place. This is what the data shows, so my process mining analysis should show what actually happened, right?
Wrong. At least as far as incomplete cases are concerned: If your data has incomplete cases because of Reason No. 1 or Reason No. 2 (see above), then these missing start or end points are not reflecting the actual process, but they occur due to the way that the data was collected.
Take a look at the customer refund process picture below: The dashed lines leading to the endpoint (the square symbol at the bottom of the process map) indicate which activities happened as the very last step in the process. For example, for 333 cases Order completed was the very last step that was recorded – See (1) in Figure 1. This seems to be a plausible end point for the process. However, there were also 20 cases for which the activity Invoice modified was the very last step that was observed – See (2) in Figure 1. This does not seem like an actual end point of the process, does it?
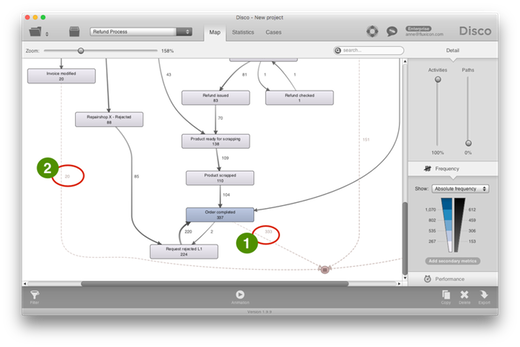
Figure 1: Cases ending with Order completed (1) seem to be finished, but cases where Invoice modified was the last step that happened (2) might still be ongoing?
If we look up an example case that ends with Invoice modified (see Figure 2), then we can see that the Invoice modified step indeed happened just before the end of the data set. It occurred on 20 January 2012 and the data set ends on 23 January 2012. What if we had data until June 2012? Would there have been any steps after Invoice modified then?
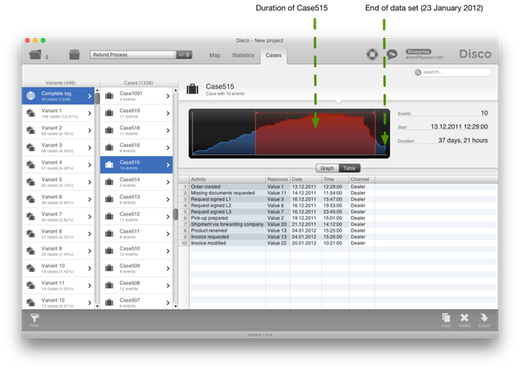
Figure 2: If an incomplete case stops at a particular point, it could just mean that we have not yet observed the next step.
So, we can see that not all end points in the data necessarily need to be meaningful endpoints in the process. Some cases can be incomplete, just because we are missing the end or the beginning of what actually happened, either because of how the data was extracted or because we don’t know yet what is going to happen with cases that are still ongoing. When you look at your process map, or the variants, for a data set that includes incomplete cases then the map and the variants do not show you the actual start and end points in your process but the start and end points in your data.
Another problem with incomplete cases is that their case duration can be misleading. The process mining tool does not know which cases are finished and which are incomplete. Therefore, it always calculates the case duration as the time between the very first and the very last event in the case.
As a result, the case durations of incomplete cases appear shorter in the process mining tool than the throughput time of the cases they represent has actually been. Let’s take a look at another example case in the process to understand what this means (see Figure 3). The shown Case72 seems to be very fast. There were just two steps in the process so far (Order created and Missing documents requested) and it took just 3 minutes.
However, when you consider that Missing documents requested is not the actual end point of this process (we are just in an intermediate state, waiting for the customer to send us some additional information) and we look at the timeline of where this case sits, then we can see that this case has been open for more than 1 month. So, the true throughput time of this case (so far) should be at least 1 month and 3 minutes!
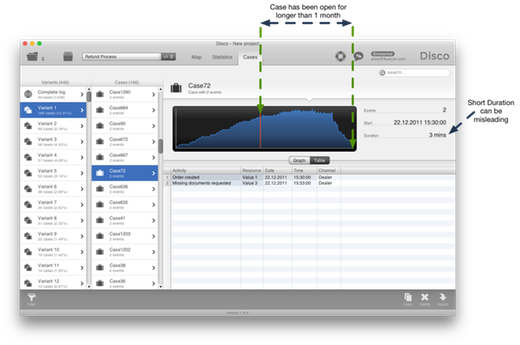
Figure 3: Incomplete cases can appear much faster than they really are.
If you simply leave incomplete cases in your data set, then calculations like the average or median case duration in the statistics view of your process are influenced by these shorter durations. So, not only the process map and the variants are influenced by incomplete cases but also your performance measurements are impacted.
Therefore, you need to investigate incomplete cases in your data before you start with your actual analysis. You want to understand what kind of incomplete cases you have and how many there are. Then, you want to remove them from your data set before you analyze your process in more detail. You can do all this right in Disco and in the remainder of this series we will show you how to do it.
Finally, some data sets may be extracted in such a way that there are no incomplete cases in it. For example, you may have received a data set from your IT department that only contains closed orders. So, any orders that are still open do not show up in your data.
In this situation, you don’t need to remove incomplete cases anymore. However, you should realize that you do not have visibility into how representative your data set is with respect to the whole population of orders. Understanding how many cases remain after removing your incomplete cases is an important step. Be aware of this limitation and consider requesting the set of open cases from the same period in addition to your current data set to be able to check them and to make sure you get the full picture.
Leave a Comment
You must be logged in to post a comment.






