Generative language models and the future of AI
Blog: Capgemini CTO Blog
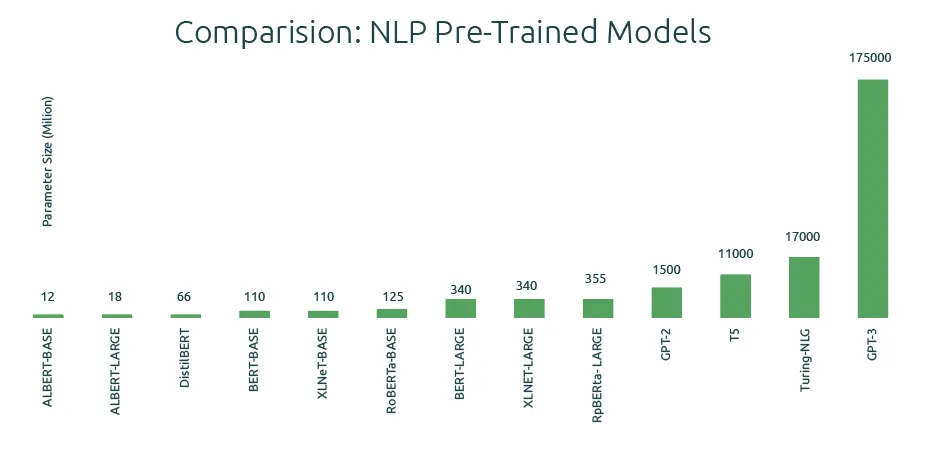
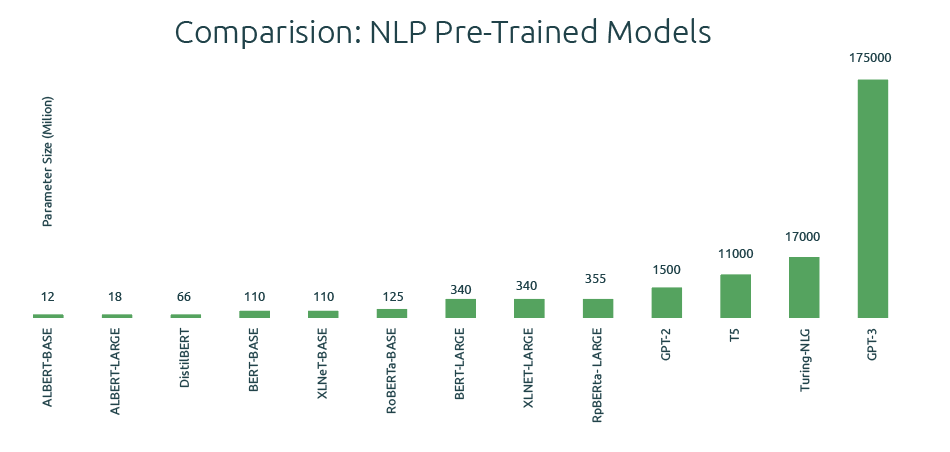
From building custom architectures using neural networks to using ‘transformers’, NLP has come a long way in just a few years. To clarify: A language model is a probability distribution over sequences of words. Language models using neural networks were first proposed in 2001. Since then, meta-learning, word2vec (word embedding), sequence-to-sequence models, and pre-trained language models have made significant progress in the field – enabling tasks such as text summarization, translation, and generation. However, large language models (such as T5 – 11B parameters, Turing-NLG – 17B parameters, and GPT-3 – 175B parameters) are complex and require expensive, high-end computing resources to train.
Prompting
With the advent of deep neural networks (deep learning) and hardware improvements (GPU, TPU, and others), you can train more prominent networks. The figure (source: OpenAI) shows the spectacular size evolution.
Now, the race is for trillion parameter models. They will require tens of millions of dollars in computing costs alone to train them. This means only a few leading companies will be able to afford evolving language models. Other companies will leverage these trained language models via APIs for their specific NLP purposes. It’s often just a matter of supplying ‘text in’ and getting ‘text out’ as a result. Creating precisely the right ‘text in’ is known as ‘prompt engineering’: A new skill that aims to articulate exactly the right text prompt to get exactly the intended language result generated.
Old & new ways
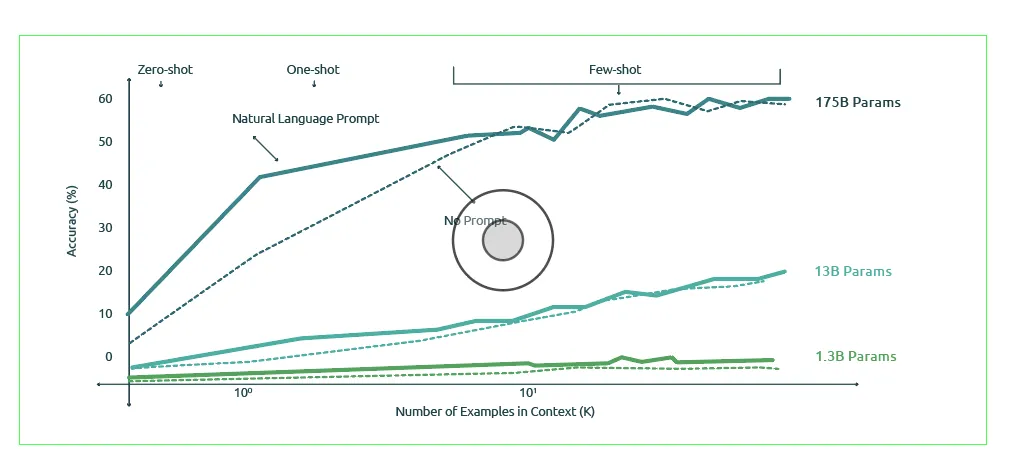
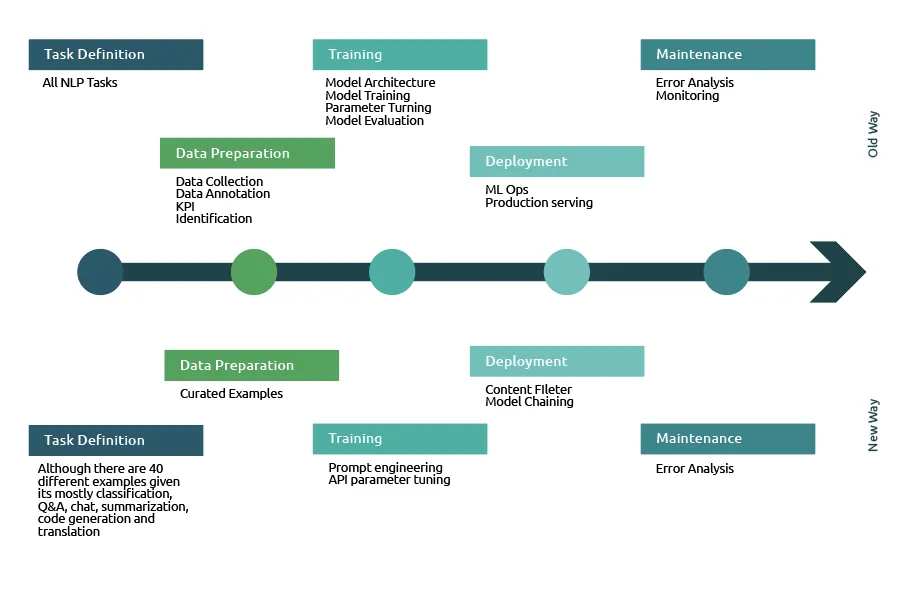
Once we are clear on the language task, we collect a small set of curated samples. In more traditional machine learning, we need a large dataset and then annotation. Language models however have a limited input and output window – the OpenAI API to GPT-3 allows up to 2048 tokens (roughly 1500 words). Within this constraint, we have to very effectively state what we want from the model (the ‘prompt’), driven by the new craft of ‘prompt engineering.’ This only involves a minimal set of examples, clearly unlike traditional machine learning – where data preparation alone takes anywhere between 60-80% of the total time spent. For instance, the following diagram (taken from OpenAI) shows the improvement in model performance as we increase the number of samples to the model.
Concerning the training phase, the only effort is to engineer the prompts in such a way as to maximize the quality of output and tune the API parameters. In traditional machine learning, we spend time identifying the exemplary architecture, selecting the library (such as Tensorflow or Pytorch), writing code to train the model, evaluating the model performance – iterating this process until we are happy with the model performance.
Simple prompt engineering and API parameter tuning replace the entire cycle. Also, in the classical deployment phase, we have to take care of all sorts of infrastructural considerations (e.g., container use). This is all replaced by just content-filtering the output of GPT-3.
No semantics
GPT-3 API identifies the best pattern that fits our intentions. It applies ‘fuzzy matching’ to an enormous model in the abstract sense. It will find the closest match, and specific parameters can control its ways. It does not have any semantic understanding of language, though. For example, when asked, “I have a heart attack. What medicine should I take?” GPT-3 has been reported to confidently respond, “Aspirin.” Hence, content engineers need to carefully filter GPT-3’s responses before taking them to production to mitigate any obvious risks of reputation loss or even legal issues. GPT-3 by itself does not have an “I don’t know” answer.
It just ingests the prompt and provides the best pattern match. Further, it requires human oversight and engineering to create the best results. Once deployed, however, there is no concept of monitoring since the model is not trained anymore and its performance is constant.
Best practices
Some best practices for getting results with language models such as GPT-3:
- Look for initial use cases which are not yet customer-facing since developing appropriate content filters will be more complex and take more time.
- For customer-facing applications, keep the text internal and carefully controlled. The GPT-3 API provides probabilities for the words, giving insight into the content analysis and weightage insights for those developing and overseeing the content.
- Create a multi-disciplinary team of “prompt engineers” that understand the areas of bias (on gender, race, etc.), fairness, legal, and various other ethical considerations – combined, of course, with excellent language skills.
- Use automated tools for content filtering: technologies to ensure responsible and fair AI are increasingly available.
Innovation
- Large language models such as GPT-3 provide state-of-the-art capabilities for a variety of Natural Language Processing tasks.
- Most companies will need to access these models through pre-defined APIs rather than developing and training these models themselves – a start difference with more ‘classic’ machine learning.
- Carefully expressing the correct textual input for the API (a ‘prompt’) is key to getting the correct text output – and thus value – from the language model.
- The new AI skill of ‘prompt engineering’ is not so much technical skill – it requires deep language and subject matter understanding, plus a solid mastering of ethical considerations and model understanding.
Author –

Rajeswaran Viswanathan, Head of AI CoE, India
Email: [email protected]
LinkedIn: https://www.linkedin.com/in/rajeswaran-v-6a9974140/