

Disco 1.6.0

We are happy to announce the immediate release of Disco 1.6.0, the latest update to our complete process mining solution.
This update was initially planned as a sort of christmas present for all of you. But we still wanted to add just another great feature. Then, we wanted 1.6.0 to ring in the new year with a bang. That didn’t work out as well, since we still kept adding even more new features.
Well, here it is, finally. And we have a feeling that some of you will be very happy about some of the new features in 1.6.0. Most of our updates are in response to your great feedback and feature requests, and this release addresses a lot of them.
We have added a lot of new functionality which makes analyzing your processes even more efficient and meaningful, without compromising on Disco’s ease of use. This update also brings a whole new slew of features, which allow you to thoroughly optimize your system, so that you can get the best performance possible for large and complex data sets, and cut down further on waiting times. We have also continued to make Disco’s user interface even more polished and streamlined – so that you can get from your analysis questions to reliable answers now even faster, and with a smile on your face.
As always, Disco 1.6.0 is a free update for all of our customers. Disco will automatically update to 1.6.0 over the internet the next time you start it up. If you are using Disco on Windows, you should install this update using the installer package from our website, to make sure you can take full advantage of all new features. You can download the new installer packages from the Disco website at www.fluxicon.com/disco.
We have recorded a quick screencast to walk you through the most important changes in Disco 1.6.0. You can also keep reading to get an overview about what is new in this update. We hope that you like Disco 1.6.0, and please don’t hesitate to let us know your comments and feedback below!
Median Performance Metrics
When you are analyzing the performance of your process in Disco, one very typical use case is to get a feeling for the typical duration of each activity and path in the process. That means, in contrast to the total duration, which allows you to quickly identify hotspots in the process, or the maximum duration, which highlights problematic outliers, you are rather interested in where a typical case is expected to spend most of its processing or waiting time.
Since our first release, Disco has included the mean duration for activities and paths to identify typical performance patterns. The mean (or average) duration is usually a pretty good approximation for typical runtime in processes which have an even distribution of durations around a dominant, typical mainstream value. However, when your log’s performance is skewed and contains extreme outliers, the mean duration also becomes skewed towards these outliers.
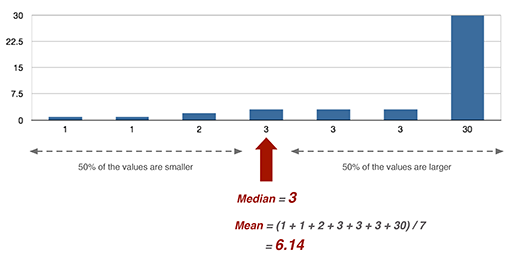
In Disco 1.6.0, we introduce the median duration performance metrics, which is a much better approximation of a typical value, also for skewed distributions. The median is defined as the value in the middle of the lower 50% and the higher 50% of measurements, and is thus much less susceptible to be influenced by extreme outliers. For example, in the illustration above, where there is one outlier with value 30 among other much smaller values, the median is 3 while the mean is 6.14 (i.e., more than twice as high).

The image above shows an excerpt of the activity statistics in Disco 1.6.0, with the mean and median durations side by side. Since the data has extreme outliers that take much longer than most others, the mean value is severely skewed upwards. The median duration highlights the fact, that the 6th activity in this table typically takes about six times as long to execute, and thus better allows you to focus on the points where an improvement has the most impact for the general case.
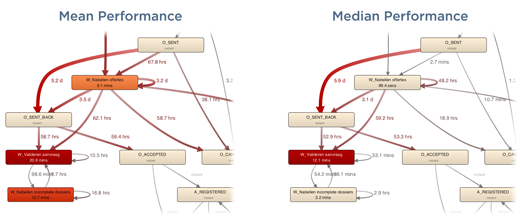
We have also integrated median durations as a new performance perspective in process maps. Here, the benefit of the median over the mean in skewed distributions becomes even more apparent, as shown in the example below. From the mean durations visualized on the left, you can get the impression that basically the whole area on the left of the process is problematic in terms of performance. The median performance view, shown on the right, makes it clear that the bulk of the problems actually lies with one activity on the lower left.
Many of our users have asked us to include the median performance metric for quite some time, and we are very happy that we can now deliver. For most use cases, the median is truly the superior metric when compared to the mean, and we generally recommend everyone to use it to make decisions about performance analysis and improvement.
Computing the median is much more complicated and resource-intensive, when compared to the mean, which is why we had not included it initially. However, I am glad to report that, after much research and tinkering, we have succeeded in implementing the median in a manner that minimizes the runtime and resource allocation impact of Disco significantly, so that it now has negligible overhead over mean calculations. When developing Disco, we take great care to make sure that any new features do not impact the experience of using Disco negatively, and we only add new features if they do not make using Disco worse or slower than before, especially for people that do not need these new features. With the median, I think we have thoroughly succeeded, which is why this metric is now included application-wide, for existing and newly added data sets.
Adding median duration does of course not mean that the mean now has become superfluous, as anyone familiar with statistics among you will agree. For many data sets, there is even no difference between the two. However, if you have data with outliers where the difference is pronounced, we are convinced that this new feature will allow you to make better decisions about your process improvement efforts, and spend your time more effectively.
Mean and Median Case Duration
Another long-standing request from some of our users has been to show the mean case duration. It has always been possible to export the list of cases in the statistics view to, e.g., Excel, and compute the average duration there. However, the average case duration is indeed an important metric to evaluate the performance of your process at a glance, so this workaround should really not be necessary.
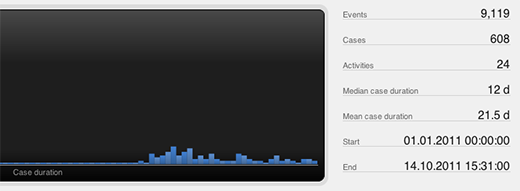
In Disco 1.6.0, the mean case duration is now shown in the Overview of the Statistics view, on the right of the process charts, so that you have immediate access to it. And, since case durations can be equally skewed as activity and path durations for many processes, we of course also added the median case duration right above. Now, you can quickly get a sensible overview about the baseline performance of your process, before you dive deeper and filter down on the problematic subsets.
Checking SLAs
Speaking of performance, Disco has always allowed you to view process performance both on the case level (in the statistics view), and on the granular activity and paths level (both in the process map and in the statistics view). However, filtering a process by performance has thus far only been possible on the case level, e.g. you could filter your data set down to the slowest 20% of cases.
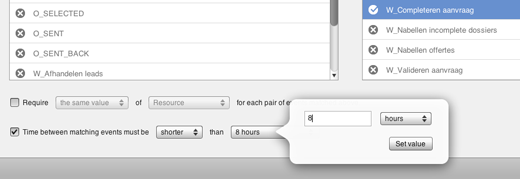
With Disco 1.6.0, we added the option to filter for waiting time between two activities. You can find this new option added to the bottom of the Follower filter, as shown above. Now, if you quickly want to check how often the time between to activities is either shorter or longer than a certain baseline duration, you can simply add a follower filter between these two activities, and set the minimum or maximum duration for that pattern.
This option makes it easy and fast to check for a violation of service level agreements (SLAs), or to find problematic patterns or cases where only a specific part of your process is actually performance-critical. And, since you can quickly add a new follower filter by simply clicking on any path in the process map, checking for SLAs and granular performance now becomes so intuitive and fast that we are convinced you will find yourself using this new feature all the time.
Redesigned Popover Dialogs
When you click on an activity or path in the process map, Disco shows you a popup dialog with more information about the highlighted element, along with the option to add a filter to your data set. We are using these popover dialogs in Disco, since they allow you to view more details, yet without leaving the context you are currently working in, making it a very lightweight form of interaction.
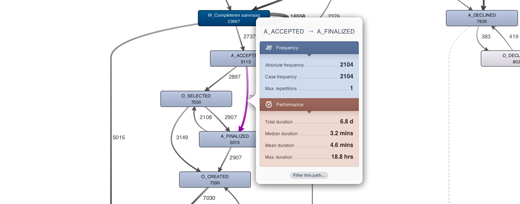
However, over time we had the feeling that the popovers have a too “heavy” feel for our taste. With their heavy, black borders, they were in stark contrast to the light and minimal look featured all over Disco. Above, you can see a screenshot of our redesigned popover dialogs in Disco 1.6.0. Eschewing their pre-1.6 heavy borders, and instead relying on a subtle drop shadow to discern them from the background, we think they blend in much more nicely with the rest of Disco. With the map popovers, you will also find that we have dialed back on the explicit UI, and put the actual information it relays more front and center, allowing you to focus more quickly on what is actually relevant.
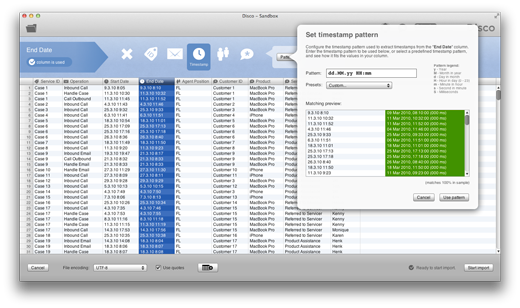
Since we are convinced that popovers are a superior mode of interaction, when compared with modal dialogs, we have looked all over Disco to find other places that could benefit from using them. Above, you can see that configuring timestamp patterns when importing CSV or Excel data now also uses this mode of interaction. You can still see most of your data and configuration while setting your timestamp pattern, which is a plus in our book.
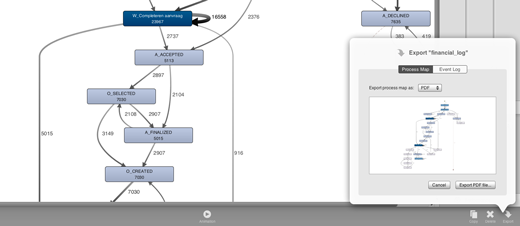
In the workspace and analysis views, copying and deleting a data set has used popover dialogs before, while exporting a data set used to bring up a disruptive, full-screen dialog view. Starting from 1.6.0, the export dialog is now also shown in a popover, so that you no longer lose context only for quickly bouncing a PDF of your process map to disk. And, if you clicked that button by accident, as with all popover dialogs, you can simply click anywhere outside it to quickly dismiss it and get back to work.
These are just some examples of where we have added popovers, and if you browse around Disco, you can discover more. We hope that you like this direction of less intrusive UI design, and that it will help you move faster and get things done even better than before. Also, is it just me or don’t they look just dandy?
Start and End Path Popovers in Process Maps
There is another popover we have added in 1.6.0. Previously, when you clicked on a start or end path in the process map (the dashed lines connecting activities to the global start or end node), you got… nothing. To be honest, we used to think that this made no sense, since you could just click on the activity on the other end to find out more. However, a lot of feedback from our users got us thinking whether we had missed something, and indeed we did.
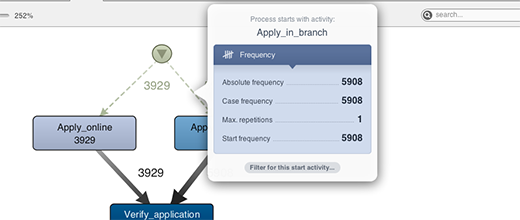
Now, when you click on a start or end path in Disco 1.6.0 and later, you get a popover dialog with more information about the start or end activity it is connected to. And, even more importantly, from this popover you can now quickly set a new endpoint filter on your data set, which focuses your analysis on just the cases entering, or exiting, the process through that path. A much more intuitive way to do that, and with no downside that I can think of. What’s not to like?
Sortable Tables
One point of feedback we have gotten since the first release of Disco was, why it was not possible to sort table views by simply clicking on the column headers. You are probably well aware of this feature from tons of other applications, and I guess the Disco table headers just looked too clickable for that not to work, so many of our users were confused as to why we did not implement that.
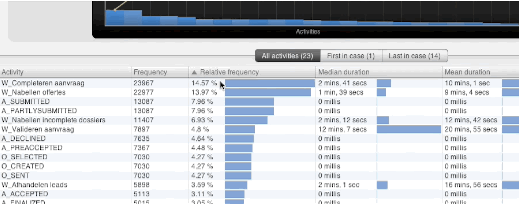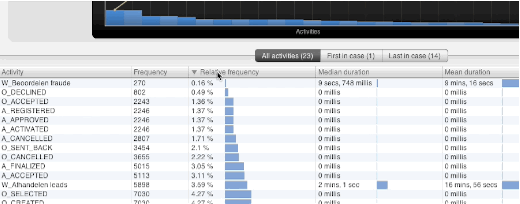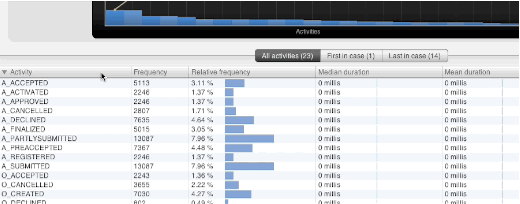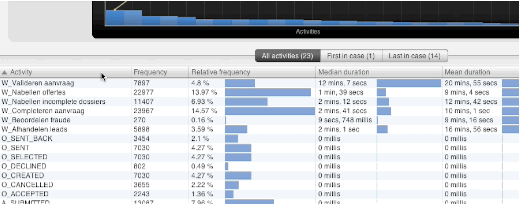
Like with the median above, implementing a rather simple feature like this can have serious implications when implementing it, which are not immediately obvious from a user perspective. For small tables, it is obviously no issue. However, when you think about a table containing detailed information about millions of cases in a data set, you might understand that sorting this table can take a long time, and may not even be feasible within the hardware constraints on some machines.
However, once again, we have finally found a way to make this work reliably for most tables in Disco starting from 1.6.0. For tables in very large and complex data sets, you may have to wait a little to see the result, but rest assured that Disco is working as hard and smart as it can while you get your coffee. So, click away on those table headers!
Control Center
We believe that a powerful tool for experts does not need hundreds of configuration options, where you have to twiddle with every possible setting. These kind of “expert” user interfaces are, in our opinion, usually a sign of laziness or inexperience on the part of the developer. When designing the Disco user experience, we see it as our job to make all the choices that we sensibly can, so that our users don’t have to. We designed Disco to automatically configure and discover many settings and parameters under the hood. When we, or our software, can truly make a decision, we do, so that you can concentrate on the really important stuff.
In some situations, though, it makes sense to take a look under the hood. This is why, with Disco 1.6.0, we are introducing the Control Center. The control center is a place to inspect the Disco system internals, and to optimize them.
You can enter the control center by clicking on the “Disco” logotype, on the upper right of the Disco toolbar.
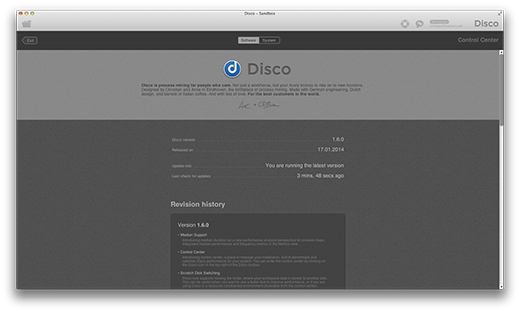
When you enter the control center, you are presented with our Software overview. Here, you can see the version of Disco you are currently running, when you have installed it, and check whether there is an update available online.
We have also included a detailed revision history, as a way for you to review the changes we have made to Disco over time. That way, even if you don’t have time to read the release notes after installing an update, you can still come back here to check whether you may have missed a useful new feature or bug fix.
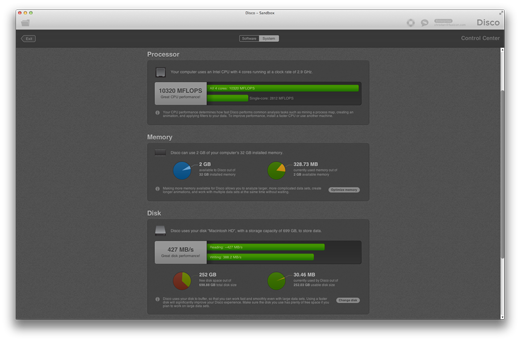
On the top of the control center view, you can switch to the System overview, which gives you a lot of useful information about the software and hardware platform that Disco relies on. The power users among you may appreciate that we even included a benchmark for important hardware components, which gives you a quick overview about the performance of your system, and about where it makes the most sense to improve your setup for maximum performance.
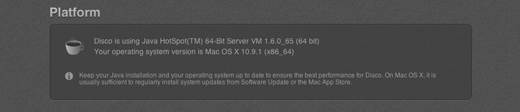
Since Disco uses the Java Virtual Machine installed on your system, we give you a quick overview about the version used, so that you can install updates or manage your configuration where necessary.
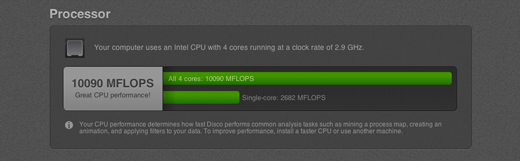
Many analysis tasks in Disco rely on the performance of your processor, and the number of processing cores it has available. Wherever possible, we have made Disco aggressively multi-threaded and parallelized, so that we can harness the performance of your CPU as much as possible, and reduce waiting times for you. The processor overview and benchmark in the control center gives you a quick estimation of your processor’s single- and multi-core performance.
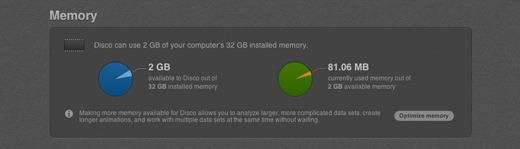
Like all applications, Disco uses your system memory (or RAM) to temporarily store data and analysis results, and access them in a fast manner. We have gone to great lengths to optimize the memory management of Disco so that, even when you have just one or two gigabytes of RAM installed, you can still analyze very big data sets. However, especially when you work with very large and complex data sets, or when you switch between data set views frequently, allowing Disco to use more system memory can significantly improve performance and reduce waiting times during analysis. The Memory section gives you information about the amount of available and currently used system memory. You also now have the option to optimize the amount of memory available to Disco (read more on that below).
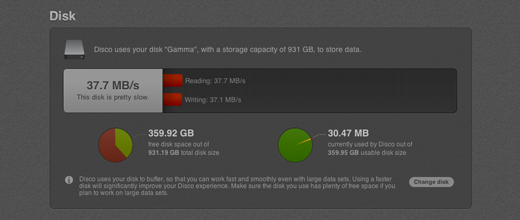
On most computers, your system memory is way too small to hold all the data required for analyzing a large data set. This is why Disco intelligently uses your hard disk to buffer event log data, and to store intermediate analysis results. The Disk section shows you on which hard disk Disco is currently storing your event log data, and gives you information about how much storage is still available, and about the performance of accessing that hard disk. If your main hard disk is very slow, or limited in space, Disco now gives you the option to change the disk it uses (read more on that below).
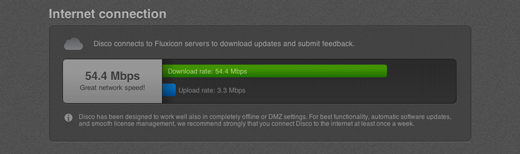
Disco uses your internet connection to download updates, and to deliver in-app feedback. For the sake of completeness, we have added a benchmark for your internet connection speed, so now you can also check whether you will receive our next update in seconds, or just milliseconds.
We would like to emphasize that, for the vast majority of Disco users, using the optimizations available from the control center should not be necessary. If you are not exactly sure about the impact of your optimizations, you should probably leave that decision to Disco and continue working with the default settings. However, if you are an advanced user, or you are constantly dealing with very large and complex data, these optimizations can greatly improve your performance.
If you need help optimizing your system, or you experience problems after changing your configuration, please contact us at support@fluxicon.com.
System Memory Configuration
For the vast majority of Disco users, the default amount of system memory available to Disco should be more than sufficient. However, when you are constantly dealing with very large or complex data sets, increasing the amount of memory for Disco can significantly improve performance. After you enter the control center, you can now optimize the memory allocation for Disco from the Memory section in the System view. After clicking the “Optimize memory” button, you will enter the following dialog.
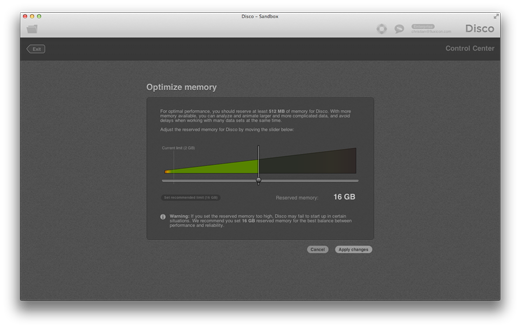
Using a simple slider, you can now seamlessly adjust the amount of system memory that Disco is allowed to use. When you set that limit too low (i.e., below 1 GB), Disco will not be able to analyze very large or complex data sets. On the other hand, setting that limit too high may result in a failure to start Disco up, when that memory cannot be made available. Disco will automatically suggest and set a memory limit that it thinks is optimal, and generally we recommend you to follow that suggestion.
Important: Note that, if you use Disco on Windows, you will have to re-install Disco from the installer packages available at the Disco website if you want to optimize system memory.
Scratch Disk Switching
Disco stores all your event log data, and temporary analysis results, on your hard disk. By using our optimized Octane storage layer, we can ensure that access to data on that “scratch disk” is still lightning fast, by leveraging an intelligent caching and buffering architecture. For most users, the default workspace location, which is on your system hard disk, should be the optimal choice.
However, some of our users work in resource-constrained environments, such as when your home directory is located on a remote file server, or when your system hard disk is very small or slow for other reasons. In these situations, it makes sense to switch the hard disk Disco uses to another, faster or more spacious disk. This can allow you to significantly improve analysis performance, or to analyze large data sets which do not fit on your system disk.
After you enter the control center, you can now change the hard disk used by Disco from the Disk section in the System view. After clicking the “Change disk” button, Disco will benchmark the performance of all your connected hard disks, and will then show you the following dialog.
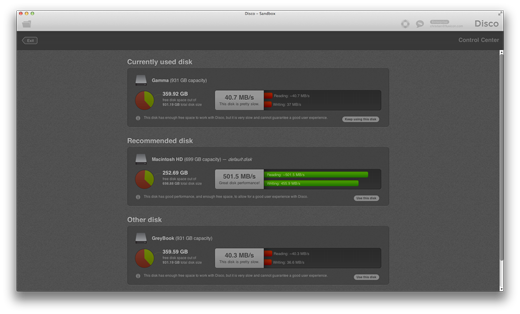
On top, Disco will show a summary of your currently used disk, and you can decide to keep using that disk by clicking the adjacent button. Below, you can see a list of disks that you can change to, with performance and usage overviews. At the bottom of every disk section, you can find a short summary telling you whether it is a good idea to use this disk for Disco. If you decide to use any of these disks instead of the currently used one, there is a button to do so. You can also exit this dialog at any time, by clicking the “Back” button on the upper left.
When you decide to change your used disk, Disco will first back up your current project to your desktop. Then, it will migrate all your project data to the newly chosen disk, after which you can continue working. For large workspaces, and depending on the performance of the disks involved, this migration may take some time. Afterwards, you can simply continue working where you left off.
Important: If you decide to change the disk used by Disco, you will need to make sure that this disk is available every time you use Disco.
Other Changes
The 1.6.0 update also includes a number of other features and bug fixes, which improve the functionality, reliability, and performance of Disco. Please find a list of the most important further changes below.
-
Improved variants frequency chart in the Overview of the Statistics View.
-
Improved handling of activities and resources composed of multiple attributes, now featuring more readable and usable names for these activities and resources.
-
Safeguard against overly large process maps, where the data set contains too many activities.
-
Improved support for long activity names in Process Map and Animation views.
-
Improved character encoding auto-detection and handling for CSV import.
-
Fixed an issue where parsing the CSV configuration sample could take longer than necessary.
-
Redesigned UI for error and interaction dialogs, which now blend in more smoothly without disrupting your workflow as much.
-
Attributes that have no value are now omitted in exported XES documents, improving compatibility with ProM 6.
-
Added median duration information to Process Map XML export.
-
Improved notification banner UIs and behavior.
-
Improved internet connectivity performance and reliability.
-
Fixed an issue on Windows where, upon returning from full-screen animation view, the interface could be drawn badly in specific situations.
-
Fixed an issue where activity names composed of multiple attributes could sometimes change slightly when filtering.
-
Fixed an issue where filtering activities or paths from the map view could sometimes fail for activities composed of multiple attributes.
Thank you!
Disco is used by thousands of people all over the world, so no matter what day of the week, or what time of day – you can be sure that someone, somewhere is analyzing and improving their processes with Disco right now.
Professionals from application domains as diverse as hospitals, the financial industry, telecommunications, automotive, aerospace, public administration, and many others rely on Disco to get a reliable picture of their operations and improve customer service. And through our Academic Initiative, more than 150 leading universities all over the globe use Disco for cutting-edge research, and for introducing thousands of students to process mining every year.
To us, this is nothing short of amazing. Together with you, all our customers and partners, we have come a long way in demonstrating the practical value of process mining, and in establishing it as an integral part of managing and improving business processes worldwide. We would like to thank you all for your continuing support of Disco!
We are constantly working to improve and extend Disco further. Of course it helps a lot that we have done our PhDs in process mining, and that we love building software that works reliably, runs fast, and that people actually like to use. But, much more importantly, we know exactly what you want, since we receive so much insightful and actionable feedback from all of you every week. For us, this is the most essential resource for running Fluxicon, and your continued feedback is what enables us to stay ahead.
We wish you a very successful and exciting year, and of course we hope you like our new update. And please, keep the comments and feedback coming – either via email, in-app feedback, or by leaving a comment below!
Leave a Comment
You must be logged in to post a comment.






