Demystifying Site Reliability Engineering
Blog: Capgemini CTO Blog
What is SRE?
Site Reliability Engineering (SRE) was introduced by Google in 2003 when there was no proper resilience testing available to test their large, distributed system on the cloud.
SRE brings the software engineering mindset into ongoing daily operations in production and equips them with necessary skills and quality engineering solutions to increase system availability and reliability. The goal is to bridge the gap between the development team that wants to ship things as fast as possible and the operations team that doesn’t want anything to blow up in production.
Why SRE?
Organizations incur huge losses due to system outages in production. System outages are increasing both due to the scale of change and the rate of change at which applications are getting deployed in different technology domains. Complex application architectures, ephemeral and dynamic in nature results in system outage in production. Also, unpredictable user behavior intersecting with unforeseeable events is not uncommon. Disaster recovery is expensive, custom, and fragile. It is implemented only if essential and is exercised infrequently. When it comes to preparing for failures in production, the SRE team comes into play with the right mix of skills to manage unpredictable system behavior efficiently.
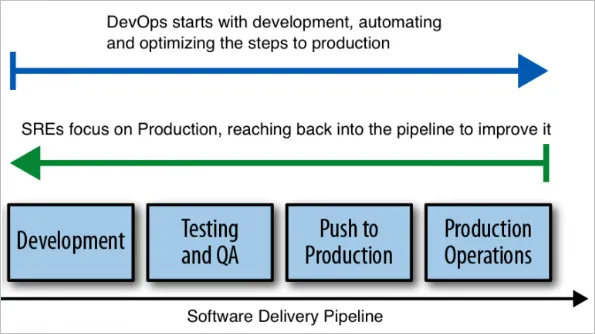
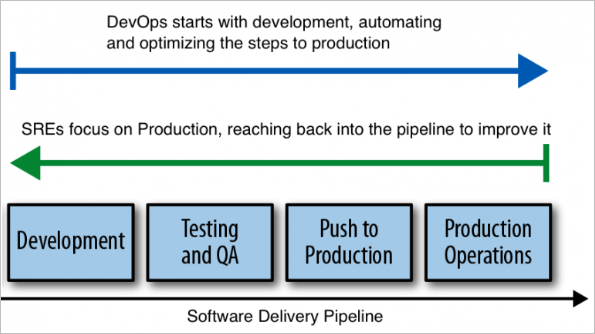
What is the difference between DevOps and SRE?
While DevOps and other practices address velocity and flexibility, SRE tackles systemic uncertainty in large, distributed systems by providing DevOps governance for deployment into production.
Market trends
Though SRE has been around for 15 years, it gained traction only in the last five years, mainly due to digital transformation and organizations migrating to the cloud, etc. With automation and observability becoming key factors for more efficient and rapid deployments, having a niche SRE skillset has become very desirable today.
What SRE means in the context of quality engineering?
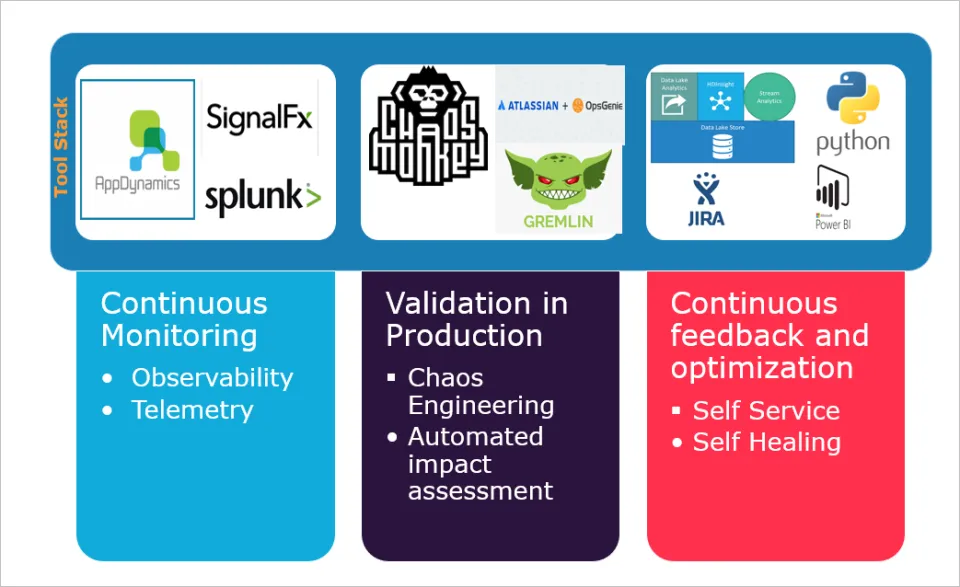
As a part of quality engineering transformation, the focus is already on the shift left of testing and integration of continuous testing into DevOps delivery pipeline. What is missing is a focus on the shift right of quality engineering by introducing continuous monitoring to enable observability and telemetry, validation engineering to support automated impact assessment, and chaos engineering and continuous feedback for supporting self-healing capabilities. These are some of the key aspects of SRE, where the team is expected to spend 50% effort on operations support and rest of 50% on automation and quality engineering solutions to make the system more resilient.
SRE can be introduced as part of quality engineering transformation in phased manner to mature it over period of time. Below diagram covers the specific aspects of quality engineering aligned to the SRE offering.
For further discussion and queries, please reach out to Deepa Talwaria ([email protected]), Apps NA DevOps COE lead.