

Configuring MuleSoft Batch Processing
Blog: BPM Blog Avio Consulting

Batch Scope
The batch scope within a MuleSoft application enables the ability to process a message as a batch, splitting the incoming payload into individual records to be processed. While the default values within this scope can be used, considerations around what these default values provide along with implications of these chosen values are explained within this article.
The batch scope configurations to be discussed are limited to just the General configurations. For reference, the default values for this configuration are shown below:
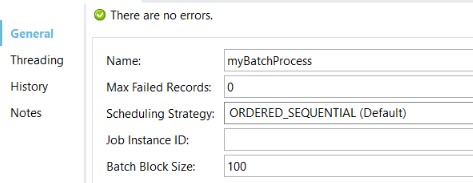
Max Failed Records
The integer value specified within this field defines the threshold for the number of failed records allowed in a batch. Depending on what value is designated determines how a batch will handle failed records (a record is deemed failed when a batch step is unable to process it):
- -1 means there is no limit to the amount of failed records
- 0 is the default value and designates no failures
- An integer value specifies the number of allowed failed records
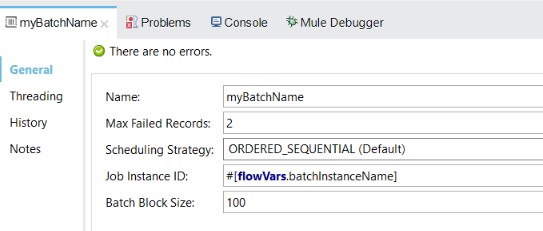
As shown in the screenshot above, in my scenario I set this value to 2, expecting that after reaching 2 failed records the batch process would halt. But during the running of my application, I discovered that within the first step of my batch, all the records were processed, even after 2 of them failed. So, what happened? Why did the batch step not stop after it hit the Max Failed Records threshold? Why did it not immediately stop the batch processing after it hit the threshold?
The answer can be found in the Mule documentation:
When one of the records fails, the batch job does not immediately stop there.
The batch step where the failed record was encountered needs to finish processing before Mule stops the batch job.
This means that if you set a block size of 100 records, and the first record fails, Mule still needs to process the remaining 99 records before stopping the batch job.
Since I had the block size set to 100 it pretty much mirrored what the documentation stated (hate when that happens). So, just be aware of this and know that the batch does not stop processing in the middle of the batch step when failures occur. Also, only consider changing this block size if necessary.
Scheduling Strategy
To alleviate competing resources, Mule will allow only one batch job instance to be executed at a time. Subsequent batches are submitted and executed in the order defined within the scheduling strategy, with ORDERED_SEQUENTIAL as the default. For the most part, this setting is sufficient. But what may catch you up is the testing of batch processes within Studio. If the application was aborted within the middle of the batch processing, the process picks back up where it left off in the batch process. It could also fail to initiate a new batch instance.
Before you consider that something is wrong with your batch scope code, understand that this is by design, due to the persistence of a batch instance within the object store. A batch is persisted to ensure no loss of data. Given the scenario when a Mule server goes down during the middle of processing a batch, it will pick up where it left off thanks to the persistence in the object store.
If the application seems to just hang at the Execute Batch Element component, not stepping into the batch scope, this is due to the feature where only one batch job instance is executed at a time. The object store has retained the state of the previous run of the application and Mule is waiting for it to complete before initiating a new batch instance.
This may not be a desired effect while testing within Studio on a developer’s machine, though. To get a clean run, set the ‘Clear Application Data’ within the General Tab of the run/debug configuration. This will clear out the object store:

An alternative is to delete the application objectstore subdirectories found within the work space .mule directory:
Job Instance ID
If the default value is accepted for the Job Instance ID, a guid is generated and used to track the instance. The application log entry generated when a batch is instantiated contains this guid, along with informational event details about the batch. For example, when an instance is created, the log will contain an entry similar to below:
Created instance 3b16dec0-926b-11e7-aec0-9cebe84afc32 for batch job myBatchName
Consider instead, to define a unique value that will provide meta-data about the batch. For example, if the batch processes purchase orders, use the purchase order number along with a date/timestamp, for uniqueness, as the job instance id. Doing this will provide more detail about the data that a particular batch instance is processing:
Created instance PO-12345-2017-10-03T15:36:46.163 for batch job myBatchName … Starting execution of onComplete phase for instance PO-12345-2017-10-03T15:36:46.163 of job myBatchName
Conclusion
Batch processing within Mule is very powerful and understanding how to configure it will enable a better experience.
Leave a Comment
You must be logged in to post a comment.







Join the Conversation