

Combining Multiple Columns as Case ID

In a previous article, we discussed how you can take different perspectives on your data by choosing what you want to see as your activity name, case ID, and timestamps.
One of the examples was about changing the perspective of what we see as a case. The case determines the scope of the process: Where does the process start and where does it end?
You can think of a case as the streaming object that is moving through the process. For example, the travel ticket in the picture above might go through the steps ‘Purchased’, ‘Printed’, ‘Scanned’ and ‘Validated’. If you want to look at the process flow of travel tickets, you would choose the travel ticket number as your case ID.
In the previous article we saw how you can change the focus from one case ID to another. For example, in a call center process you can look at the process from the perspective of a service request or from the perspective of a customer. Both are valid views and offer different perspectives on the same process.
Another option you should keep in mind is that, sometimes, you might also want to combine multiple columns into the case ID for your process mining analysis.
For example, if you look at the callcenter data snippet below then you can see that the same customer contacts the helpdesk about different products. So, while we want to analyze the process from a customer perspective, perhaps it would be good to distinguish those cases for the same customer?

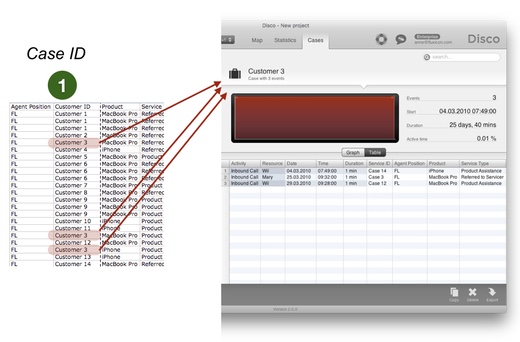
Let’s look at the effect of this choice based on the example. First, we only use the ‘Customer ID’ as our case ID during the import step. As a result, we can see that all activities that relate to the same customer will be combined in the same case (‘Customer 3’).
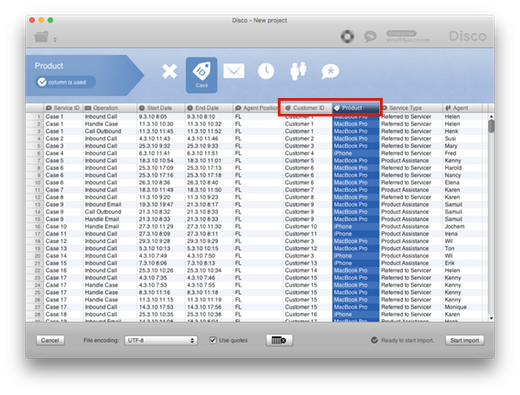
If we now want to distinguish cases, where the same customer got support on different products, we can simply configure both the ‘Customer ID’ and the ‘Product’ column as case ID columns in Disco (you can see the case ID symbol in the header of both columns in the screenshot below):
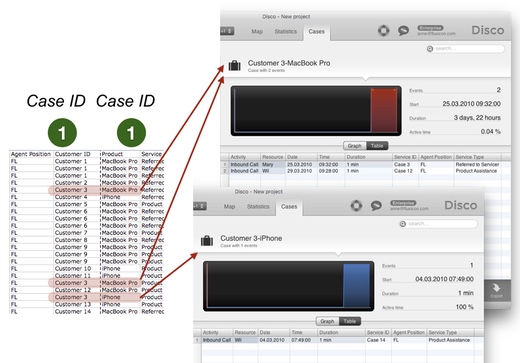
The effect of this choice is that both fields’ values are concatenated (combined) in the case ID value. So, instead of one case ‘Customer 3’ we now get two cases: ‘Customer 3 – MacBook Pro’ and ‘Customer 3 – iPhone’ (see below).
There are many other situations, where combining two or more fields into the case ID can be necessary. For example, imagine that you are analyzing the processing of the tax returns at the tax office. Each citizen is identified by a unique social security number. This could be the case ID for your process, but if you have data from multiple years then you also need the year to separate the returns from the same citizen across the years.
To create a unique case identifier, you can simply configure all the columns that should be included in the case ID as a ‘Case’ column like shown above, and Disco will automatically concatenate them for the case ID.
As before, there is not one right and one wrong answer about how you should configure your data import but it depends on how you want to look at your process and which questions you want to answer. Often, you will end up creating multiple views and all of them are needed to get the full picture.
Leave a Comment
You must be logged in to post a comment.






