
Combining Machine Learning with Credit Risk Scorecards
Blog: Enterprise Decision Management Blog

With all the hype around artificial intelligence, many of our customers are asking for some proof that AI can get them better results in areas where other kinds of analytics are already in use, such as credit risk assessment. With 25 years of experience with AI and machine learning under our belt, we can certainly provide that proof.
My colleague Scott Zoldi blogged recently about how we use AI to build credit risk models. In this post, I’d like to drill into one of the examples he gave, to show some of the explorations we’re doing to make sure we get the full power of machine learning without losing the transparency that’s important in the credit risk arena.
How Do You Build a Model with Limited Data?
A traditional credit risk scorecard model generates a score reflecting probability of default, using various customer characteristics as inputs to the model. These characteristics could be any customer information that is deemed relevant for assessing the probability of default, providing the information is also allowed by regulations. The input is binned into different value ranges and each of these bins is assigned a score weight. While scoring an individual, the score weights corresponding to the individual’s information are added up to produce the score.
While building a scorecard model, we need to “bin” the characteristics into value ranges, and the bins are meant to maximize the separation between known good cases and known bad cases. This separation is measured using weight of evidence (WoE), a logarithmic ratio of fraction of good cases and fraction of bad cases present in the bin. A WoE of 0 means that the bin has same distribution of good and bad cases as the overall population. The further away this value is from 0, the more concentration the bin has of one type of case versus the other, as compared to the overall population. A scorecard will generally have a few bins, with a smooth distribution of WoE.
As Scott described in his post, our project was to build credit risk models for a home equity portfolio. Home equity lending slowed dramatically after the recession, and due to this we had few bad exemplars in the development sample, and only a 0.2% default rate. It was difficult to build models using traditional scorecard techniques.
The primary reason for this is the inability of a scorecard model to interpolate information. Information needs to be explicitly provided to the scorecard model and the standard way to do this is by providing sufficient good and bad counts for each bin to compute reliable WoE. If good or bad counts are not sufficient, as in this case, this approach ends up yielding noisy, choppy WoE distribution across bins, leading to weak-performing scorecard models.
Enter Machine Learning
Next, we used a machine learning algorithm called Tree Ensemble Modeling or TEM. TEM involves building multiple “tree” models, where each node of the tree is a variable which is split into two further sub-trees.
Each tree model that we build in TEM is built on a subset of the training dataset, and uses just a handful of characteristics as input. This limits the degrees of freedom of the tree model, yields a shallow tree as a consequence and ensures that the splitting of the variables is limited. This allows us to meet the requirement on the minimum number of good and bad cases more diligently.
The following schematic shows an artistic rendition of a TEM, depicting multiple shallow trees in a group or an Ensemble. The final score output, produced through Ensemble Modeling, is usually an average of the scores of all the constituent tree models in the Ensemble.
Such a model can have thousands of trees and tens of thousands of parameters that have no simple interpretation. Unlike a scorecard, you can’t tell a borrower, a regulator or even a risk analyst why someone scored the way they did. This inability to explain the reason why someone got a particular score is a big limitation of an approach like TEM.
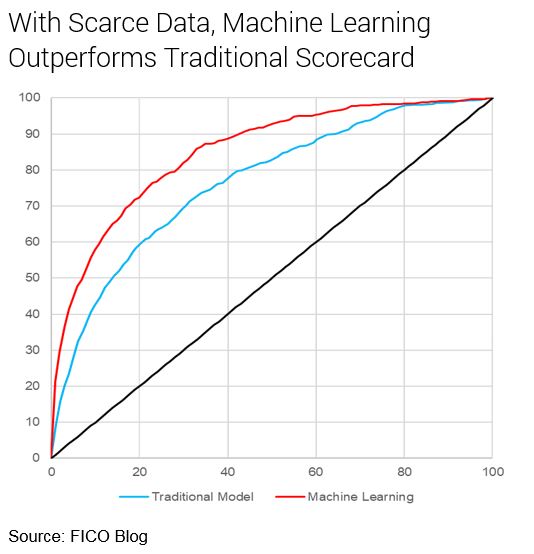
However, by building a machine learning model, we were able to confirm that our scorecard approach was losing a significant amount of predictive power. Although not practical for use, the machine learning score outperformed the scorecard. Our next challenge was to try and narrow the performance gap between the TEM and the scorecard models.
“Scorecardizing” Machine Learning
FICO has faced this challenge many times before: How do you merge the practical benefits of a scorecard — such as explainability, the ability to input domain knowledge, and ease of execution in a production environment — with the deep insights of machine learning and AI, which can uncover patterns scorecard development approaches can’t?
Over the years we have developed practical ways to solve for this challenge. For instance, we have developed mechanisms for imputing domain knowledge into neural networks and other machine learning models.
To impute explainability, we have built a tool called Scorecardizer. You can guess what it does from the name! Scorecardizer recodes the patterns and insights discovered using machine learning or AI and turns them into a set of scorecards. The tool tries to match the score distribution generated by a machine learning algorithm like TEM, instead of relying on the WoE approach that we discussed earlier. So instead of providing good and bad data points and directly computing the WoE, the score distribution in each bin derived from the machine learning model ends up providing an estimate of WoE.
Significantly, the final model is almost as predictive as the machine learning model. An out-of-time validation of the final model demonstrates that it performs well over a period of time, as shown in the following figure.
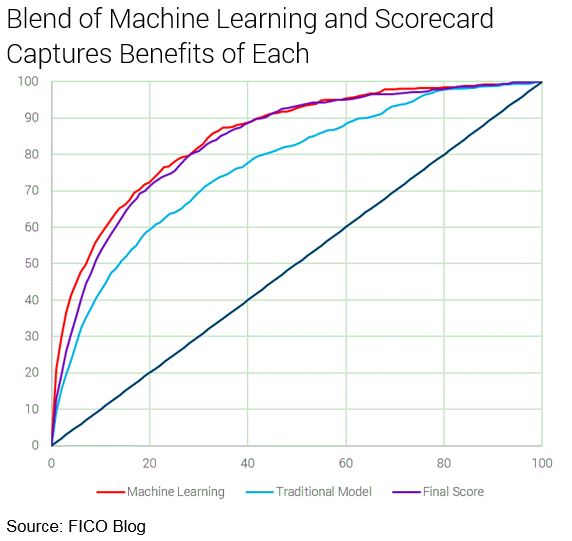
The final result of the Scorecardizer solution is a strong, palatable model. Our hybrid approach overcame the limitations imposed by fewer number of bad cases. Whereas previously it was considered impossible to build powerful scorecards for problem spaces with such sparse bad cases, the Scorec
ardizer approach allows us to do so, whenever a machine learning algorithm can be built to extract more signal from such datasets.
Scorecardizer is just one approach that FICO uses to leverage the power of AI in heavily regulated areas where reasons related to score loss is needed. It represents our commitment to expanding AI to new areas for our customers, something we have been practicing for the last 25 years. To see some of the ways we do this today, check out our page on artificial intelligence and machine learning.
The post Combining Machine Learning with Credit Risk Scorecards appeared first on FICO.
Leave a Comment
You must be logged in to post a comment.






