

Cloud Datastores Simplify Business Automation
Blog: Method & Style (Bruce Silver)
Cloud datastores are a new feature of the Trisotech Automation platform. They are most useful in BPMN, but they can serve also as input data in DMN. Datastores are a standard BPMN element representing persisted storage, accessed by a process task via data association but available for external access as well. In Trisotech’s implementation, each datastore is a single relational table. It acts like a database but requires none of the extra work involved in using something like OData. For example, to incorporate a relational database table in your model with OData, you need to host the database yourself, subscribe to an OData wrapper service like Skyvia Connect, and use a Service task for the database operation. Datastores are much more convenient: They are built into the Trisotech platform, so they require no external components and they are directly accessible like any process variable. If your table is a few thousand records or fewer, datastores could make your Low-Code Business Automation project a lot simpler. In this post we’ll see how they work.
In the process diagram, a datastore is represented by the can shape, unlike the dogeared page shape used to represent data objects, data inputs, and data outputs. Like data objects, cloud datastores are process variables based on a FEEL datatype, which is a collection of the table row type. But a datastore differs from a data object in two important ways: First, its value is persisted even after a process instance that accesses it is complete. Second, a datastore does not belong to a single process. It belongs to the entire workspace, with access granted to its creator and selected other workspace members. That means it can be used to store data shared between a process and an external entity or between multiple processes.
In Trisotech, datastore content is typically created and maintained with the help of Excel on the desktop. Importing an Excel file in a management utility creates and populates the table. For example, here we have an Excel table of the available vacation days for each employee. In the management utility, importing this Excel file populates the datastore and adds it to the list of the user’s defined datastores. You can also modify datastore content via Excel using the utility. Authorized external entities can also do that via an API, enabling interaction with the process via shared data, a familiar pattern from Method and Style.



Binding a datastore shape in BPMN (or an input data in DMN) syncs the model element to the datastore content, indicated by a lock icon inside the shape. Unlike a database table, which requires a Service task to perform a query, insert, or update operation, operations on a datastore use standard FEEL list functions and operators. They are typically performed by data associations, i.e., the input and output mappings of a Script task, Decision task, or User task, tasks which can perform actions in addition to the datastore read or write. To perform a datastore operation and nothing more, a Script task is simplest, as shown in the model below:

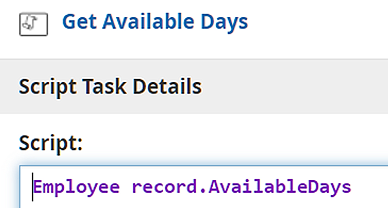
Here the Script task Get Available Days queries the datastore to find the accrued vacation time for the employee identified by the data input Vacation Request. This involves selecting the employee record from the datastore and then extracting the AvailableDays value from that record. Since both the input mapping and the script are FEEL expressions, you have several possible ways to do this: Get the entire datastore in the input mapping and extract AvailableDays for a particular employee in the script expression; select the employee record in the input mapping and extract AvailableDays in the script; or do it all in the input mapping with the script being just the identity mapping. With datastores there is no difference in performance, but I think it’s most “natural” to do it the second way, as shown here. The input mapping selects Employee record using a filter of the datastore, and the script extracts AvailableDays.

While querying a datastore usually involves a filter, inserting a record in the datastore uses the standard FEEL list functions, append, insert before, or insert after. Deleting a record uses the list function remove. Some of these require knowing a record’s position in the datastore, which you can get using the index of function. The more interesting operation is a record update. Let’s say in this example we want to reduce the employee’s AvailableDays value by the vacation days requested, as in the process diagram below.

Record updates like this use the list replace function, new in DMN 1.4. This function has two forms: list replace(list, position, newItem) and list replace(list, match, newItem). The first one requires knowing the position, as with insert before. In the second, the parameter match is a function definition, similar to the precedes function in sort. The first argument of match is a range variable representing any item in the list. As with precedes, it is most common to define match inline as an anonymous function using the keyword function.
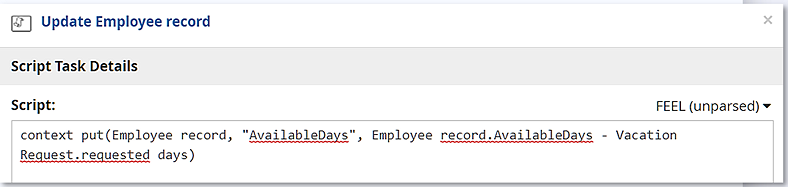
In this example, the input mapping of Update Employee record is the same as before, a filter extracting the original Employee Record from the datastore. But this time, the script expression uses the context put function to modify the value of that record’s AvailableDays component, subtracting Vacation Request.requested days from the original value.
Then the output mapping uses list replace to replace the original employee record with the updated one. Here match is an anonymous function in which the range variable x stands for any record in the datastore and the function selects the one for which the EmployeeId value matches that of Employee record. The list replace function substitutes the script output Employee record – now updated – for the original datastore record.

Admittedly, datastore updates involve unfamiliar FEEL functions like context put and list replace, but learning those is a small price to pay for the extra convenience. Cloud datastores make data persistence easy. You should give them a try!
To learn how to do Low-Code Business Automation using both datastores and OData, check out my new training.
Leave a Comment
You must be logged in to post a comment.






