

An intro to Kogito
Blog: PROCESSES, RULES AND EVENTS

- Technology-driven: As you will see below, there’s a lot of great technology available for building cloud-native applications, but to be able to fully leverage these technologies in the context of business automation, we had to make a few radical changes.
- Focus and innovation: We wanted to focus specifically on what is needed to build next-gen cloud-native applications, and how you can leverage processes and rules in this context. This allows us to offer something that really fits this ecosystem and doesn’t bring in additional baggage that isn’t relevant.
When you’re building cloud-native applications, there’s a lot of great technology out there (some of it you’re probably already using). Kogito is closely aligned and leveraging these technologies, so you can build highly scalable cloud-native services, with extremely quick startup times and low footprint. Picking up some of these technologies and truly taking advantage of them sometimes required quite radical changes (so this definitely not a lift-and-shift of our existing engines but built from the ground up).

For example:
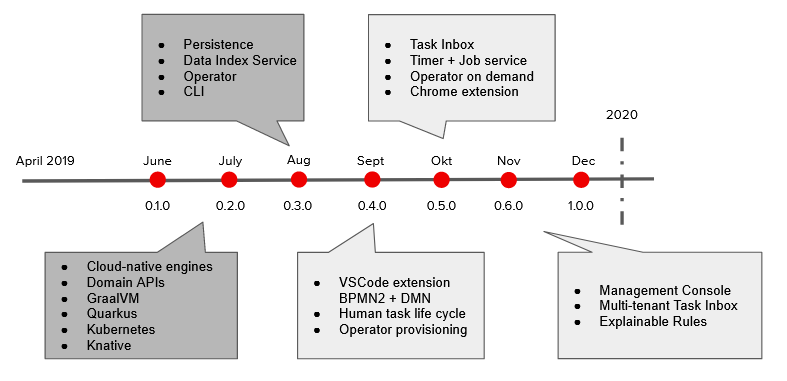
- Kubernetes is our target platform for building and managing containerized applications at scale.
- Quarkus is the new native Java stack for Kubernetes that you can leverage when you build Kogito applications and it’s a game changer. But don’t worry, if you are building your applications with Spring Boot, we will help you with that as well!
- GraalVM allows you to use native compilation, resulting in extremely quick startup times (a native Kogito service start about 100x faster ~ 0.003ms) and minimal footprint, which is almost a necessity in this ecosystem nowadays, especially if you are looking at small serverless applications. If you’re interested in what’s behind this, I would recommend to read Mario’s blog about this.
- Building serverless applications? Leverage Knative and Kogito together so your applications can scale up or down to zero based on the need.
- Kogito applications behave like any other service you build, so you can instantly leverage technologies like Prometheus and Grafana for monitoring and analytics with optional extensions.
- Internally we leverage quite a lot of other core middleware technogies like Kafka, Infinispan, KeyCloak, etc. This means we take care of setting these up (on demand, for our internal messaging, persistence and security requirements for example) but we strongly encourage you to start leveraging these technologies for your own use cases as well.
We want to make the life of developers easy, by offering them instant productivity and making sure we integrate well with how they are building their applications. So rather than asking developers to come to us with their requirements, we are coming to them !
- The tooling required to build your processes and rules needs to be closely integrated with the workflow the developer is already using to build cloud-native services. Therefore we have spent a lot of time on allowing this tooling to be embeddable. For example, we just released the first alpha release of our VSCode extension (see video below, credits to Alex) which allows you to edit your processes (still using BPMN 2.0 standard) from within VSCode, next to your other application code. We’re working on a similar experience for Eclipse Che.
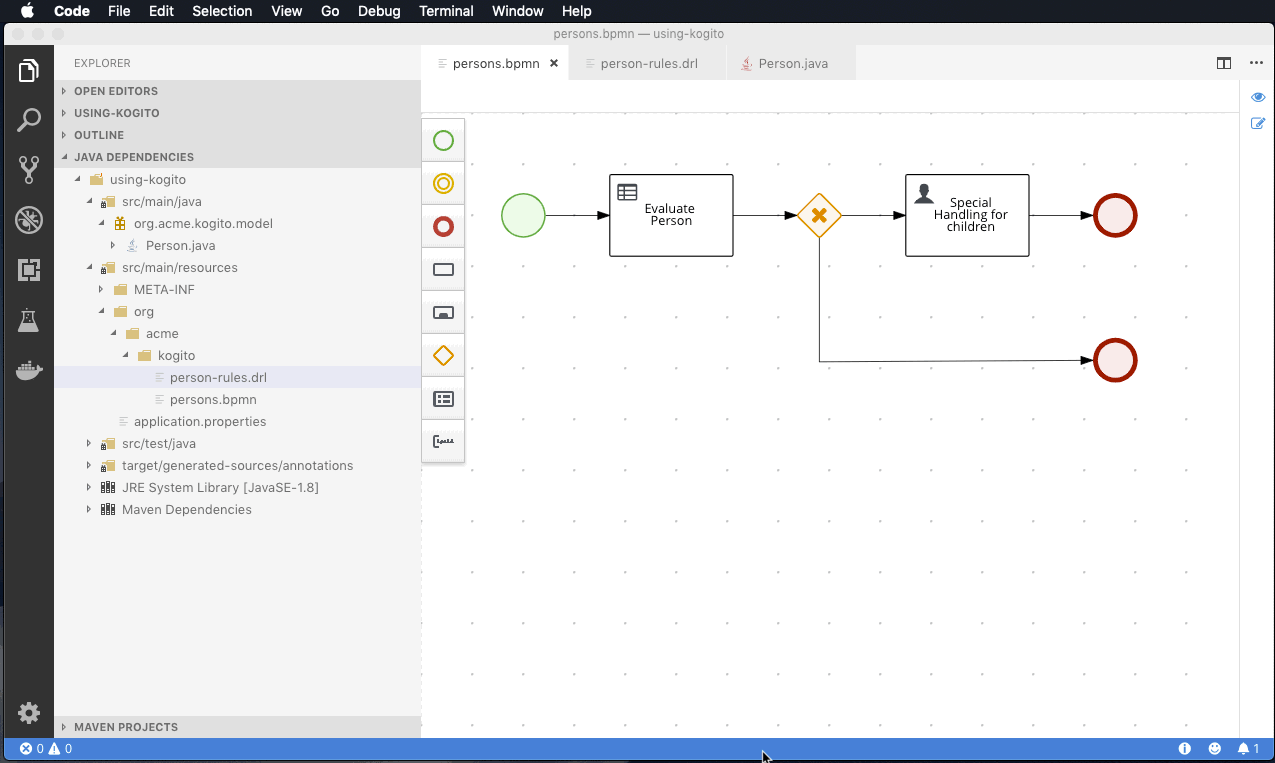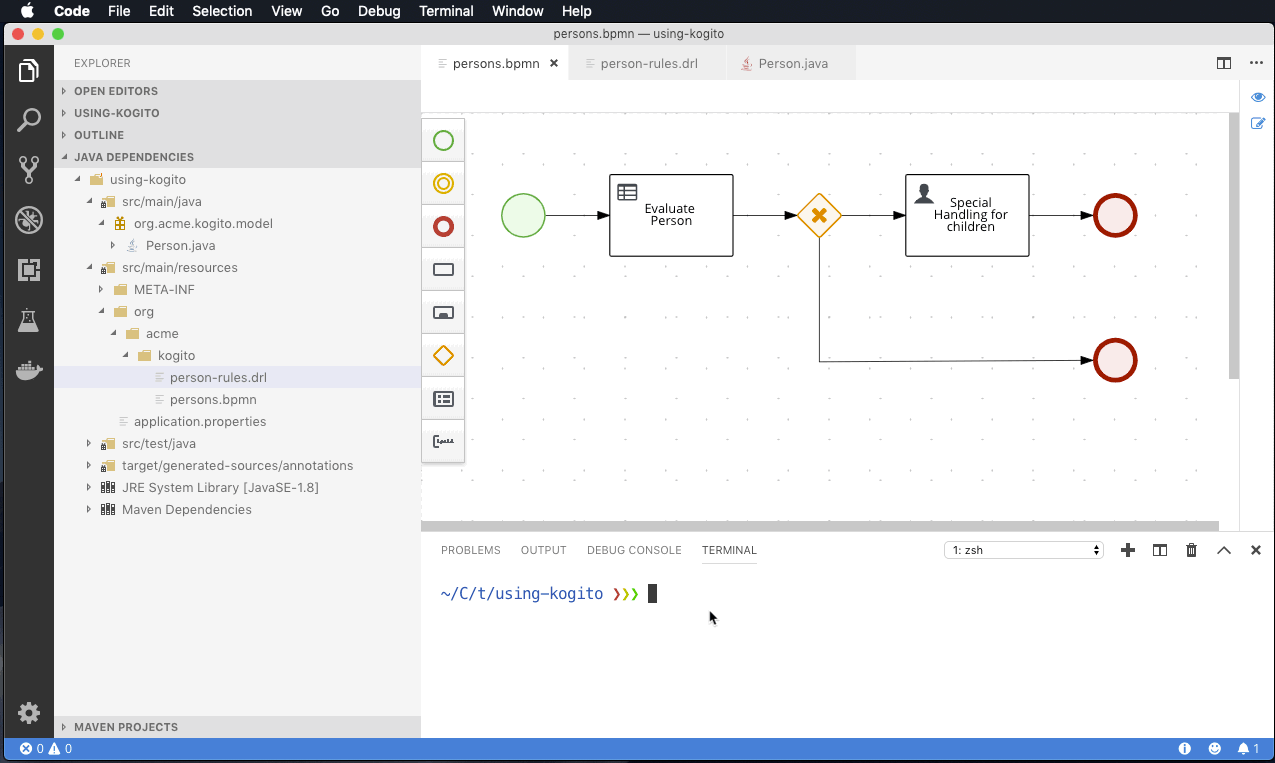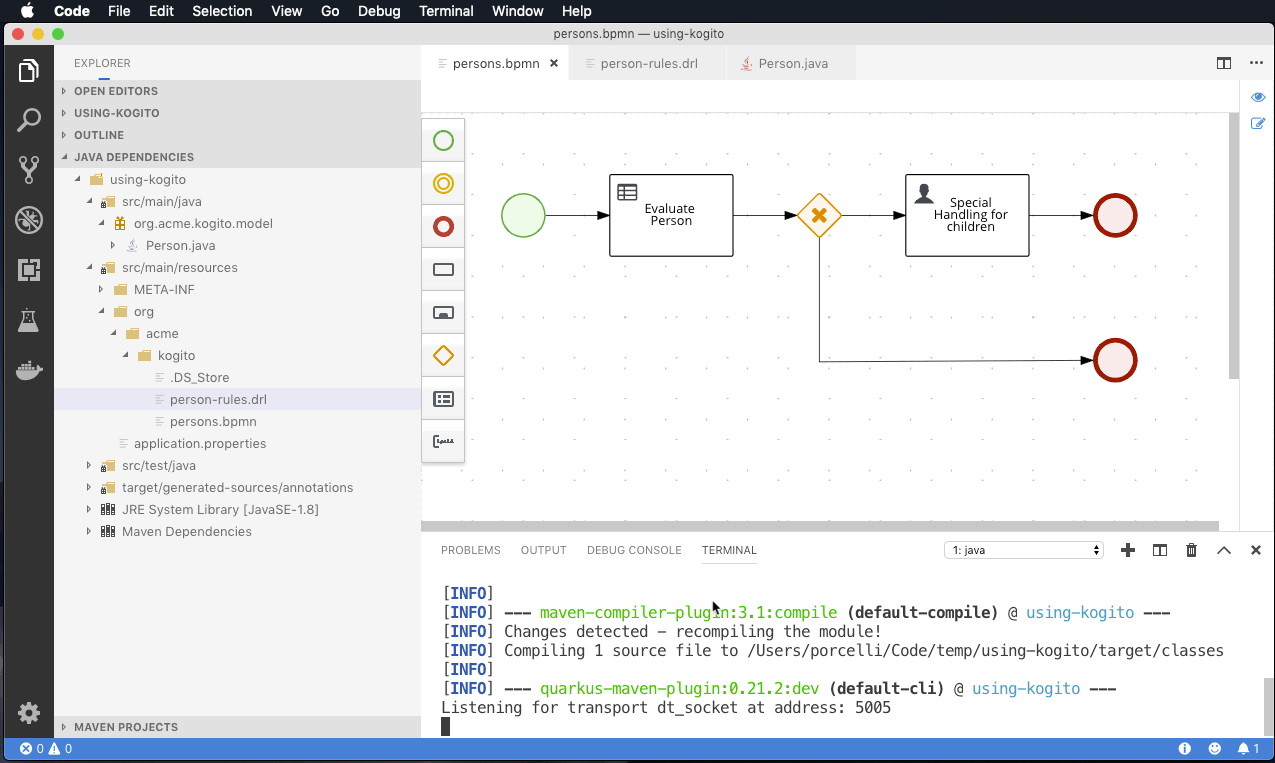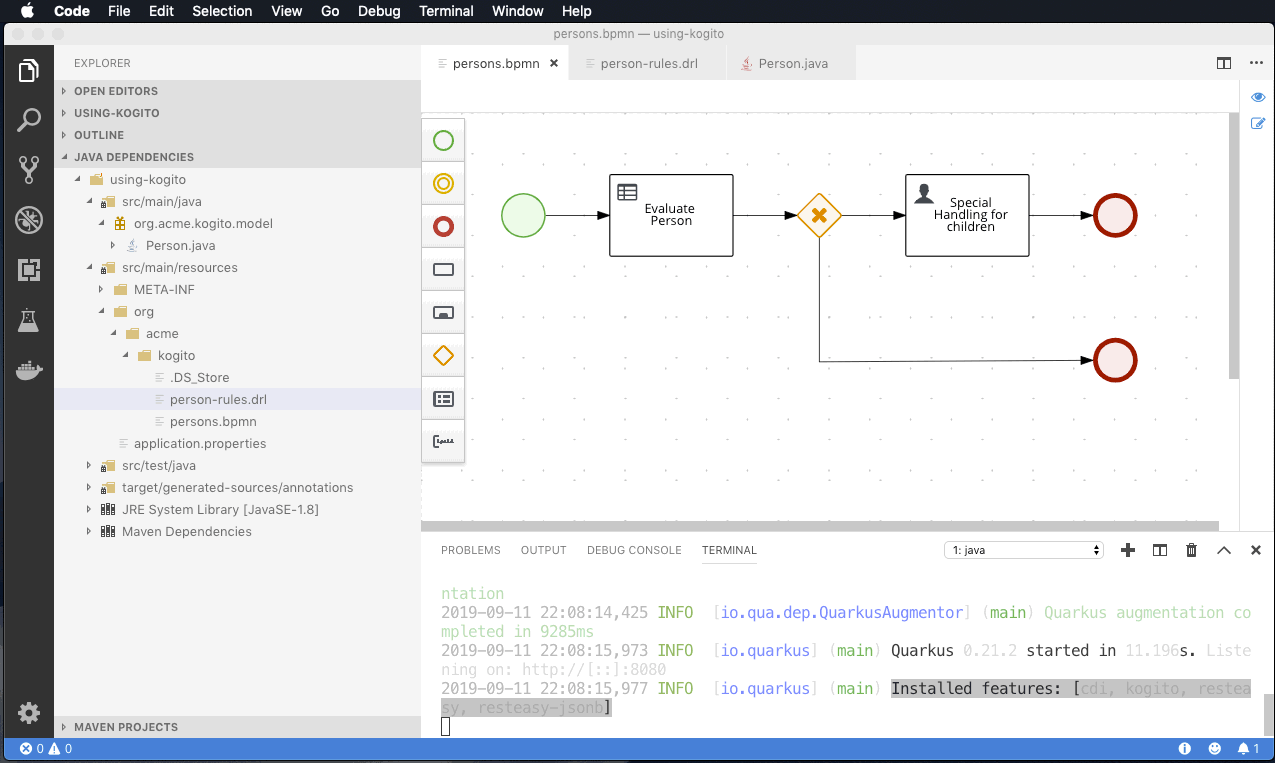
- Instant productivity means it should be trivial to develop, build and deploy your service locally so you can test and debug without delay. Both Quarkus and Spring Boot offer a dev mode to achieve this, Quarkus even offering live reload of your processes and rules in your running application (extremely useful in combination with the advanced debug capabilities).
- Once you’re ready to start deploying your service into the cloud, we take advantage of the Operator Framework to guide you through every steps. The operator automates a lot of the steps for you. For example, you can just give it a link to where your application code lives in git, and the operator can check it out, build it (if necessary including native compilation) and deploy the resulting service. We are working on extending this to also provision (on demand) more of the optional services that you might need (like for example a KeyCloak instance for security, or Infinispan for your persistence requirements). We also offer a Command Line Interface (CLI) to simplify some of these tasks.
Kogito, ergo domain
Kogito has a strong focus on building your own domain-specific services. While we hope you can leverage our technology to significantly help with that, we want developers to be able to build the service they need, exactly how they want it. As a result, the fact that Kogito is leveraged to do a lot of the hard work is typically hidden and your service exposes itself as any other with its own domain-specific APIs.
To achieve this, Kogito relies a lot on code generation. By doing so we can take care of 80% of the work, as we can generate a domain-specific service (or services) for you, based on the process(es) and/or rule(s) you have written. For example, a process for onboaring employees could result in a remote REST api endpoints being generated that you can use to onboard new employees or get information on their status (all using domain-specific JSON data).

Additionally, domain-specific data can also be exposed (through events or in a data index) so it can easily be consumed and queried by other services.
Architecture
When using Kogito, you’re still building a cloud-native application as a set of independent domain-specific services, collaborating to achieve some business value. The processes and/or rules you use to describe the behavior are executed as part of the services you create, highly distributed and scalable (no centralized orchestration service). But (by using this additional compilation step) the runtime your service uses is completely optimized for what your service needs, nothing more.
If you need long-lived processes, runtime state can be persisted externally in a data grid like Infinispan. Each service also produces events that can be consumed. For example using Apache Kafka these event can be aggregated and indexed in a data index service, offering advanced query capabilities (using GraphQL).
What’s coming next?
At this point, Kogito 0.3.0 is the latest release (from August 23rd), but we have much more coming on our roadmap before our 1.0.0 release which is targeted towards the end of the year.
Get started
And now I believe you are ready to give it a try yourself, so please do and let us know! You can start with building one of the out-of-the-box examples, or by creating your first project from scratch. Follow our getting started documentation here ! You will see you can build your own domain-specific service in minutes.

Or if you want to watch a small presentation (and demo!) from Maciej, check out his latest DevNation Live talk here.
Leave a Comment
You must be logged in to post a comment.






