

Why We Love ProM 6

In my last post I elaborated on the reasons why the newly released ProM 6 is, in my opinion, not quite ready to render the venerable ProM 5.2 obsolete for practical use. So, does that mean you can ignore ProM 6 for now? That it will not have practical relevance beyond being a research tool? Or that it is even dead in the water?
Au contraire! The answer for which version of ProM you should use, as so often, depends on the context – and, in fact, there is nothing forcing you to make that choice, you can use both versions side-by-side. Does ProM 6, as it currently stands, have problems and shortcomings that would make people choose ProM 5.2, even after its release? You bet. After all, I was not lying when I wrote that we still generally recommend to use the 5.2 branch in practice. Do those problems outweigh the benefits of ProM 6? My answer is an unequivocal “No”, and I will elaborate on the other side of the story in the rest of this post.
Let’s get modular

Process mining research has started with a very tight focus on process discovery, which basically means to generate a visual process model from an event log. Over the years though, the vision for process mining, and the research topics covered, have been greatly expanded. Not only do researchers now also consider other perspectives (e.g., social networks) and vectors (e.g., conformance), and have integrated process ontologies and semantic mining – Process mining has been redefined as an fundamental technology, enabling such advanced use cases as operational decision support in flexible systems, or more faithful simulation of process alternatives including the current state.
With version 6, ProM finally gets a framework that can truly support these more advanced use cases, and many more that may lie ahead. For researchers and developers alike, this opens up a world of opportunities that have been simply impossible to realize with the old framework. For example, providing process mining as a service is pretty awkward and hard to scale when your service runs on a tightly integrated desktop application. Since ProM 6 radically separates the UI from the internal heavy lifting, while minimizing interdependencies, these types of applications now become much easier to implement.
I would describe this shift in framework design with the word “modularization”, since the focus is on keeping dependencies to a minimum, in order to enable you to use just the components you are actually interested in. This tendency is not limited to the core framework, though, but it rather affects every part of the system.
ProM 6 is so modular, in fact, that not even the user interface, let alone specific plugins, are a part of the core framework. Yes, there is a standard configuration, but every user is completely free to adjust it to their specific requirements and preferences. The integrated package management of ProM 6 breaks with the tradition of ProM being a monolithic application, which is only released in full, and in year-long release cycles. Everybody can now develop a ProM plugin and upload it to her own website – Just tell ProM where to get it, and it will be part of your system. And if there is a bug fix or new functionality, there is no need to wait for the next ProM release, since it is now the plugin authors who can determine their own release schedule.
While the main benefit of these changes is for developers and system integrators, I am convinced that end users will benefit greatly from the new situation. Only time will tell to which degree, or in which precise manner, developers will take advantage of the modularized architecture and package management. But I would be surprised if it does not translate to much shorter update cycles and a wealth of new, interesting functionality at your fingertips.
Welcome to UITopia
With its new and greatly improved framework, ProM 6 also got a completely redesigned user interface, called UITopia. This user interface was designed and implemented1 by myself, so I don’t want to go too far in tooting my own horn. However, I naturally agree with Joos Buijs that it definitely improves the way how the functionality of ProM can be accessed.
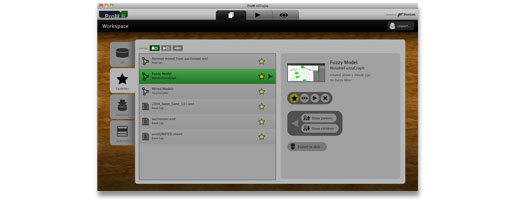
In previous versions of ProM, the available objects (e.g., logs or process models) were pretty well-hidden from the user. You would need to focus a specific plugin’s window, and then browse through ProM’s menus, to actually see what objects that window “provided”, and what you could do with them. The user interface of ProM 6 makes these objects explicit, enabling you to browse them in the workspace manager, as you would browse files on your filesystem.
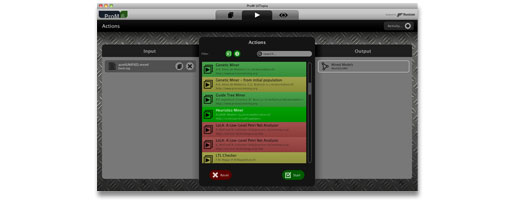
But, maybe more importantly, ProM 6 also allows you to browse the set of plugins that are available in the “action view”. This means, you no longer have to mine a Petri net from a log in order to discover that there is such a thing as a correctness checker for Petri nets in ProM. The UI of ProM 6 also explicitly shows the dependencies of each plugin (i.e., what object it requires to execute), and the list of objects that will be created after execution. In short, these changes make it much easier for you to find out what is there (your objects), and what you can do right now (the available actions), which should make working with ProM much more productive.
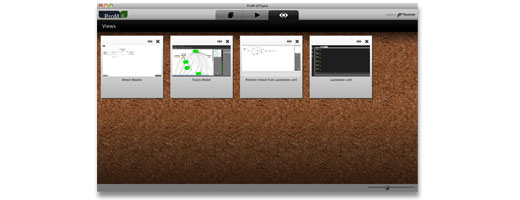
Finally, ProM 6 separates actual objects (e.g., a Petri net model) from their visualization (i.e., the image of the Petri net on your screen). This means that, if you are no longer interested in viewing the result of your analysis, you can simply close the visualizer – the actual object will still be in your workspace, until you choose to delete it explicitly. And even better, there can be multiple visualizers for each object type, so you are no longer limited to the standard view ProM 5 used to deliver.
The party is over here

All the work involved in completely redesigning and re-engineering the framework for ProM 6 has already paid off in spades. Process mining researchers have taken advantage of the newly-given flexibility and openness of ProM, and delivered functionality in plugins which would have been impossible to realize based on the ProM 5.2 architecture. In hindsight, I am honestly surprised at how far we were able to push the old codebase. Sometimes it truly felt like deliberately cheating and abusing the framework, when one needed to hack in a sorely needed extension.
Given that, it is no surprise that most of the action in process mining research and development has been squarely in ProM 6. Just to give you a hint, here are some current features of the core ProM 6 framework, which would have been impossible to realize in the old codebase.
-
Action chaining: In the new architecture, the framework has a lot of meta-information about plugins. It knows precisely what types of input objects they require to function, and what types of objects a plugin will deliver back, once executed. This enables the framework to find a “chain” of plugins, on its own, that can create a desired result from a given input. This feature has the potential to be truly revolutionary, assisting users which are new to ProM, and saving you a lot of clicking.
-
XES support: The log management layer of ProM 6 uses the OpenXES library, the reference implementation of the new XES standard for event logs. This makes ProM 6 the tool with the most complete XES support in the world right now. XES is still quite a young standard, but it fixes a lot of problems and limitations of the previous MXML standard and has the potential to make event logs, and their analysis, much more useful.
-
Performance: The OpenXES library does not only make handling event logs much more flexible. It also handles the common tasks of loading, reading, and managing event logs much more efficiently, and is finely tuned for maximum performance. That means you can analyze larger event logs, and in a much shorter timeframe. Plugins automatically take advantage of that performance boost. And this is just one of many examples where ProM 6 brings consistent, noticeable improvements in performance, across the board. What’s not to like about that?
-
Workspace persistency: You can now shut down ProM at any point in time when you’re done – once you open ProM the next time, it will be just as you left it, with all your objects and analysis results right there. The concept of a workspace in ProM, and that it is automatically made persistent across restarts, makes managing an analysis project that much easier that you will be left wondering how you had ever done without.
And outside of the core framework, innovation within ProM 6 has been happening even more aggressively. New plugins and analysis approaches are almost exclusively implemented on ProM 6. And these new plugins include a lot of exciting and promising research, many of which will no doubt be part of everybody’s standard repertoire in practice in a few years.
Developers, developers, developers, …

Again and again, I am surprised at how many people, in this day and age, still honestly think that development is a commodity. Need an application? Well, let the admin configure an open source tool. Or hire some student interns or offshore developers, and let them quickly cobble something together from some open source libraries. The result is consistently the same: You get some shoddy, ugly piece of code which does not do what it is supposed to.
But even if you have a team of solid developers, and you provide them with the right resources, their performance and quality will still be limited by the constraints of the platform. Here is where the ProM 6 architecture has achieved a major breakthrough compared to the old codebase. Developing for the ProM 6 APIs is a much more coherent, sane, and enjoyable pastime than it used to be before.
On the one hand, this is a direct result of the complete redesign, where starting from scratch has been taken as an opportunity to get things right this time. This means, a more logical layout of the framework and libraries, and more well-documented interfaces to develop against. Developing against the ProM 6 API also means writing a lot less boilerplate code – Since ProM 6 makes heavy use of annotations, and limits code that you had to write over and over again, you can focus on the actual heavy lifting most of the time.
On the other hand, as a result of the modularized approach, developing additional components for ProM 6 becomes a much more focused affair. Since model types (e.g., event log, Petri net, or BPMN model), analysis components, and visualizers have been strictly separated, you can now implement just one of these if that is what you want. You have a new algorithm that mines a BPMN model? No need to take care of how it will be displayed, the framework will do that for you. Or you hate the way BPMN models are shown in ProM 6? You can just write a new visualizer component, which will then be available for all BPMN-producing plugins. In short, with ProM 6 you develop just what you are missing – nothing more, nothing less.
In combination with the open package management of ProM 6, this ease of development should significantly lower the barriers of entry for developers who want to contribute process mining functionality. You can start small, on your own, and upload the resulting plugin to your own website. And then, you take it from there. I can’t wait for the amount of interesting plugins that will undoubtedly turn up sooner or later, now that people can contribute that easily.
License to Killer App

And since we are talking about contributions, that part has also become a whole lot easier on a completely different level. Due to inherent dependencies, the old ProM versions needed to be released under the terms of the CPL license. Now, there’s nothing wrong in principle with the CPL license, but it is a so-called viral license. So, just as much as ProM was forced to adopt the CPL license (by virtue of using another CPL-licensed library), that license was also forced upon all code within ProM, and thus also on all contributed plugins.
Starting from ProM 6, this problem has been resolved, and most parts of ProM are now being released under the terms of the, much more liberal, LGPL license. This means that, whatever you change in the core parts of ProM, you will still have to contribute back under the LGPL terms. But the LGPL does not “bleed over” into your contributed plugin code, or into code that uses the ProM core. In my opinion that is a sensible compromise – If you build upon the ProM 6 framework, the community benefits from your enhancements. But anything you build on top of that foundation is still yours to own and license as you please.
Many vendors are interested in adding process mining functionality to their products these days. And, with the new license terms of ProM 6, this platform becomes very attractive for doing so in a responsible manner. No, there is no free lunch – if you use ProM 6, you will also have to give something back in return. But, at the same time, you will not have to make your most intimate business secrets completely open to the world.
I would imagine that this change will make the ProM 6 platform much more attractive to system builders, where process mining functionality is not the focus, but a way to enhance their functionality portfolio. And, if there is adoption from this side, it can only be beneficial for the community in the long run. There will be more developers, from different groups and companies around the world, joining in to enhance and extend ProM. And with the load of development spread more evenly among the various benefactors, we will all be better off. Especially the end users of ProM.
So, what you’re saying is… What?

I know what you’re thinking. So what now? First I’m telling you to stick to ProM 5.2, and then I’m here singing the praises for the new ProM 6 platform. But the truth of the matter is, there is no choice you need to make here between 5.2 or 6. There is neither a reason to be scared of ProM 6, nor is there a reason to dismiss 5.2 altogether and focus only on the new ProM 6.
While there is no active development to speak of in the old ProM 5.x codebase, and existing bugs probably won’t be fixed anymore, that is not really a problem. ProM 5.2 works reasonably well, and our recommendation stands that, if you need to urgently analyze a process from its logs, then 5.2 is what you should turn to first and foremost. On the other hand, ProM 6 is certainly stable and complete enough to do real process mining with, so there is no need to wait for it to reach some kind of magical “generally-usable version”. That version is ProM 6, available right now.
But why would you need to make that choice in the first place? One great feature of modern computers is that you can install multiple versions of the same software side by side, and that is what I would advise the majority of you to do. Download and install ProM 6 to see where process mining is heading, and explore the wealth of plugins and functionality that is growing there day by day. And when ProM 6 should be acting weird, or when you need some plugin has not been ported yet – Well, ProM 5.2 is still around, happy to serve you.
And, rest assured that, from all I know, the ProM project team around Boudewijn van Dongen and Eric Verbeek2 are working tirelessly on ProM 6, fixing bugs and adding features on a daily basis. Before we know it, we will all be happy users of ProM 63, say good riddance, and not even think to look back. And, if you can’t wait – Fire up your editor and contribute something to what is undoubtedly the future of process mining!
(I have probably not even started to answer all the questions you may have about ProM 6, and I have undoubtedly missed a lot of exciting and important features of ProM 6. So, if there is something you’d like to ask or add, please don’t hesitate and fire away in the comments!)
Leave a Comment
You must be logged in to post a comment.






