
Why data is NOT the new oil: a peek at the economics of AI applications
|
|
Who stands to gain most from AI, and how? If we follow the money, where does it lead?
A few weeks back I tweeted
Thinking a lot about econ. of #AI for biz. Current suspicion: opptys for small/med size orgs way+ limited than for lge orgs w current tech
— Neil Ward-Dutton (@neilwd) July 3, 2017
I’ve been thinking a fair bit about this.
First, let’s get one thing out of the way. I’m going to use the troublesome ‘AI’ term here, even though lots of people get cross about its casual use. What I mean here is the application of machine learning and deep learning techniques to identify patterns in data, categorise data, make estimates and predictions.
The packageability of AI applications
The trouble is, not all AI applications are created equal. Really, when we talk about AI we’re talking about artificial specific intelligence: that is, systems that are tuned and trained to address specific challenges.
Furthermore, within each challenge domain, there’s real variation in what’s possible.
Fundamentally, for some challenge domains, some learned models and algorithms can be almost generically applicable; whereas in many other domains, many will only deliver value when they’re specialised in very particular ways. To put it another way: for some applications, it’s possible to train a system generically, against a broad training data set, and have it perform well for a variety of users. For many applications, this is a long way from reality.
A good example ‘generically-trainable’ application here is facial recognition: a system can be trained on a large library of images of faces, and then in order to recognise your face it needs only a relatively small amount of training. Access to training data is easy: there are dozens of facial recognition training datasets freely available online. (And if you want to find out more about image recognition more generically, you should check out this fascinating article).
You can see how, for these kinds of applications, packaged commercialisation is kind of straightforward: you provide a service that can be almost plugged in, as-is, to a wider application platform and Bob’s your uncle.
Similar things hold true, more or less, for many AI applications in the domain of natural communication – speech recognition, speech synthesis, natural language understanding, and so on.
Take a look at this chart. Here I’m endeavouring to show how different AI applications require different delivery models. On the left are applications that are more or less generically suited; on the right are applications that require much more specialisation to deliver value.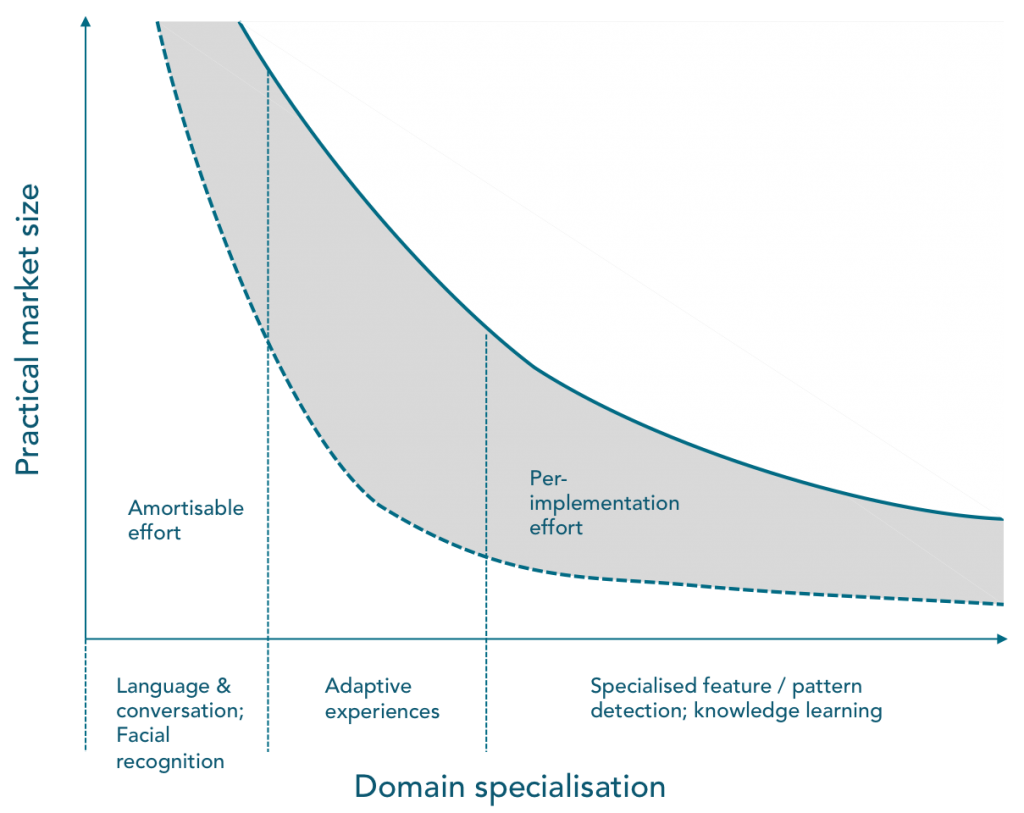
More data = better packaging
With all these generally-packageable applications, a key part of what makes systems ‘as packageable as possible’ is access to large amounts of training data.
And this, combined with their broad applicability, is why consumer-oriented online platform operators – Amazon, Google, Microsoft – are likely, before very long, to drive the price of these services towards zero (you can already see what Amazon’s doing on pricing for its AI services, initially announced in 2016). If you’re selling generic AI application services as part of large portfolios of other application platform services, at very high volumes, the pricing will naturally follow suit.
What this also means is that very soon, it will be impossible for IBM, or any of the other major enterprise tech vendors (SAP, Oracle, Salesforce etc) to make serious money from services that are focused on the left-hand side of the chart.
The real money will come from specialised domains
Other AI applications are completely different.
As we slide down from the ‘head’ of the curve on the left of the chart, we come to less general-purpose capabilities that will be applicable in many scenarios, but far from universally. What makes sense for one insurer wanting to weed out fraud may be partially be transferrable to another; but the technology implementation is unlikely to be completely transferable.
One approach to enabling ‘maximum packageability’ for these AI applications is the providers to integrate them across cloud-delivered services that are themselves already packaged to some extent (see Salesforce’s Einstein). In this way, systems can be trained on (anonymised, or meta-) data aggregated across the installations of broad customer populations… so even where one customer’s platform instance doesn’t drive enough training data, the total data set provides what’s needed.
The further to the right on the chart we go, the more AI applications only really deliver value when system components are custom-assembled, configured and trained in particular environments.
The challenge for any vendor wanting to play here is in how well it can package frameworks, knowledge and consulting personnel to minimise the amount of custom work (and time) that will be required to deliver value. In today’s increasingly cloud-first world, few organisations are prepared to wait 9-12 months, or more, for something that may or may not deliver an advantage. You can see what Craig Wentworth had to say about IBM’s challenge here.
And still, the tail is a tail…
The last point I want to make is about the size of the available market for these specialised AI applications.
The thing we can’t get away from is that – regardless of how generic a given application is – to make an AI application really worthwhile, you need access to significant amounts of training data.
Small- and medium-sized enterprises have the ability to capture the benefits of AI at the head of our curve: where applications can be packaged and delivered to wide audiences. And through cloud-hosted services, there’s also a chance they can capture value in the middle zone of the chart.
The value of many applications at the ‘specialised tail’ will be harder for small- and medium-sized enterprises to capture, though, because – particularly where applications are focused on improvement of operations, using data generated from operations – it’s just not practical to get access to enough data.
A large bank will have interactions with tens of thousands of customers every month; the data from those interactions might provide great training data. A specialist engineering firm may have interactions with tens of customers every month at most; there’s not much AI fuel there.
Data is NOT the new oil
I’ve lost count of how many times I’ve seen presentations that proclaim “data is the new oil”.
Yes, at a very abstract level, generic ‘data’ is increasingly a source of business growth and potential competitive advantage… but when it comes to specifics, and when we get away from those ‘generic head of the curve’ applications, this is an analogy that just doesn’t hold water.
The post Why data is NOT the new oil: a peek at the economics of AI applications appeared first on MWD Advisors.
Leave a Comment
You must be logged in to post a comment.






