
What is Hierarchical Clustering? An Introduction
This technique is frequently used to find patterns and correlations in large data sets in a variety of disciplines, including biology, social sciences, and computer science.
Let’s dive deeper to understand the hierarchical clustering with the following sub-topics:
- Introduction to Hierarchical Clustering
- Why do we need Hierarchical Clustering?
- How Hierarchical Clustering Works?
- Types of Hierarchical Clustering
- Advantages of Hierarchical Clustering
- Use Cases of Hierarchical Clustering
- Conclusion
If you are a Beginner, then do watch this Data Science Course to have in-depth knowledge about the specialization
{
“@context”: “https://schema.org”,
“@type”: “VideoObject”,
“name”: “Data Science Course | Data Science Full Course | Data Scientist For Beginners | Intellipaat”,
“description”: “What is Hierarchical Clustering? An Introduction”,
“thumbnailUrl”: “https://img.youtube.com/vi/a5KmkeQ714k/hqdefault.jpg”,
“uploadDate”: “2023-05-25T08:00:00+08:00”,
“publisher”: {
“@type”: “Organization”,
“name”: “Intellipaat Software Solutions Pvt Ltd”,
“logo”: {
“@type”: “ImageObject”,
“url”: “https://intellipaat.com/blog/wp-content/themes/intellipaat-blog-new/images/logo.png”,
“width”: 124,
“height”: 43
}
},
“contentUrl”: “https://www.youtube.com/watch?v=a5KmkeQ714k”,
“embedUrl”: “https://www.youtube.com/embed/a5KmkeQ714k”
}
Introduction to Hierarchical Clustering
In Data Science, a common method for clustering related objects is called hierarchical clustering. It is an unsupervised learning approach that may be used in exploratory data analysis because it doesn’t require any prior information about the data or labels.
The data points are first represented as independent clusters in hierarchical clustering, and then they are combined or divided depending on some similarity or distance metric. Until a stopping condition is satisfied, usually when the desired number of clusters or a certain threshold for similarity is reached, this procedure is repeated.
A dendrogram, a tree-like structure that shows the hierarchical links between clusters, may be created using hierarchical clustering, which is one of its key advantages. Users may utilize the dendrogram to view the results of clustering and decide how many clusters to employ for future study.
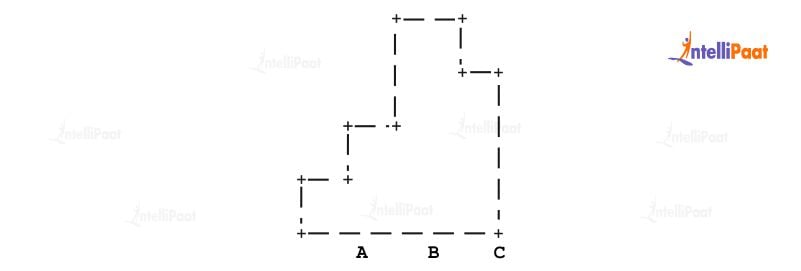
In this dendrogram, the data points A, B, and C are shown at the bottom, and the clusters they belong to are represented by the branches above them. At each level, the distance or similarity between the clusters is shown on the vertical axis. In this example, the two closest clusters are A and B, which are merged into a new cluster, shown by the branch connecting them. This new cluster is then merged with C to form the final cluster, represented by the top branch in the dendrogram.
To learn more check out Intellipaat’s Data Science course.
Why do we need Hierarchical Clustering?
Hierarchical clustering is in demand because it is helpful in exploratory data analysis since it doesn’t require any prior information or labeling of the data. When working with vast and complicated datasets, this method may be very helpful since it enables researchers to find patterns and links in the data without any prior preconceptions.
It also offers a dendrogram as a visual representation of the grouping outcomes. Users may use the dendrogram to examine the data’s hierarchical structure and decide how many clusters to employ for future analysis. When working with huge datasets where the ideal number of clusters is not immediately obvious, this is very helpful. Hence this is the main reason why hierarchical clustering is in high demand.
How Hierarchical Clustering Works?
An unsupervised machine learning approach called hierarchical clustering is used to sort comparable items into groups based on their proximity or resemblance. It operates by splitting or merging clusters until a halting requirement is satisfied.
Each data point is first treated separately by the algorithm as a cluster. At each iteration after that, it merges the two closest clusters into a single cluster until only one cluster contains all of the data points. A dendrogram, which resembles a tree and depicts the hierarchical connection between the clusters, is the result of this procedure.
In hierarchical clustering, the choice of distance or similarity metric is crucial. Manhattan distance, Euclidean distance, and cosine similarity are three common distance metrics. The types of data and research issues are being addressed to determine the distance metric to be used.
Example:
!pip install scipy
import numpy as np
from scipy.cluster.hierarchy import dendrogram, linkage
import matplotlib.pyplot as plt
# Create a sample dataset
X = np.array([[5, 3], [10, 15], [15, 12], [24, 10], [30, 30], [85, 70], [71, 80], [60, 78], [70, 55], [80, 91]])
# Perform hierarchical clustering on the dataset
Z = linkage(X, 'ward')
# Plot the dendrogram
fig = plt.figure(figsize=(10, 5))
dn = dendrogram(Z)
plt.show()
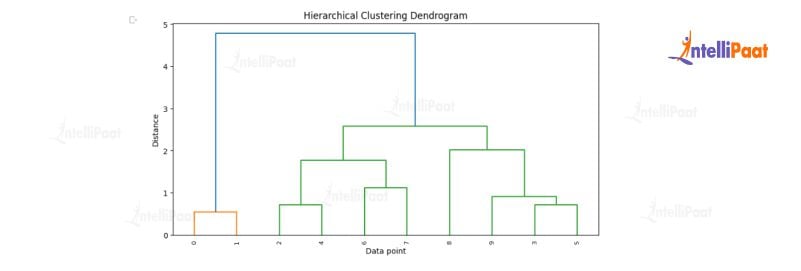
To show the process of hierarchical clustering, we generated a dataset X consisting of 10 data points with 2 dimensions. Then, the “ward” method is used from the SciPy library to perform hierarchical clustering on the dataset by calling the linkage function.
After that, the dendrogram function is used to plot the hierarchical clustering result, where the height of each node represents the distance between the merged clusters. The dendrogram plot provides an informative visualization of the clustering result.
Check out our blog on Data Science tutorials to learn more about it.
Types of Hierarchical Clustering
Agglomerative and divisive clustering are the two basic forms of hierarchical clustering. Let’s discuss each of them in detail:
- Agglomerative clustering: The most popular method for hierarchical clustering is agglomerative clustering. It iteratively joins smaller groups of individual data points into bigger clusters based on how similar or distant they are to one another.
Up until all data points are part of a single cluster, the two closest clusters at each phase are combined to form a new cluster. The outcome is a dendrogram that shows the clusters’ hierarchical connections. - Divisive clustering: On the other hand, this type of clustering starts with a single large cluster, and recursively breaks it down into more compact clusters according to how different they are. Compared to agglomerative clustering, this method is less often utilized since it is more computationally intensive and tends to yield unstable results.
Advantages of Hierarchical Clustering
Hierarchical clustering provides the following benefits:
- Creates a dendrogram: A dendrogram is a visual representation of the results of hierarchical clustering. The dendrogram demonstrates the hierarchical links between the clusters, enabling researchers to decide on the ideal number of clusters and proceed with additional analysis with confidence.
- Flexibility: Any form of data, including category, binary, and continuous data, can be employed with hierarchical clustering.
- The number of clusters need not be specified: Hierarchical clustering does not need a predetermined number of clusters, in contrast to other clustering techniques. The dendrogram has a built-in threshold, allowing researchers to select the ideal number of clusters.
- Robust against noise: Hierarchical clustering is strong against data noise and outliers. Even when there is substantial noise in the data, it is still able to recognize and group related data points.
- Results can be understood easily: The dendrogram created by hierarchical clustering is simple to understand and can offer insights into the underlying structure of the data. Labeling the clusters and providing a meaningful interpretation of the findings are additional options.
Go through these Data Science Interview Questions and Answers to excel in your interview.
Use Cases of Hierarchical Clustering
A flexible and popular method with many useful applications is hierarchical clustering. Listed below are a few applications for hierarchical clustering:
- Market segmentation: Based on their commonalities, clients or items may be divided into groups using hierarchical clustering. This can assist companies in identifying various client categories and customizing their marketing plans accordingly.
- Image segmentation: According to their similarities, photographs may be divided into various areas using hierarchical clustering. Applications for computer vision and image processing may benefit from this.
- Gene expression analysis: Analyzing gene expression data and identifying patterns of gene expression in several samples may be done using hierarchical clustering. This can aid in understanding the biology of illnesses and the development of novel therapies.
- Social network analysis: Hierarchical clustering may be used to examine social network data, and finds groups of people that share a common set of interests or activities. This is helpful for marketing.
Career Transition





Conclusion
Organizations may use hierarchical clustering as a potent tool for complicated data analysis and interpretation. Moreover, companies may use hierarchical clustering to find patterns, connections, and anomalies in data, which can help them make better decisions and achieve better business results.
If you have any queries related to this domain, then you can reach out to us at Intellipaat’s Data Science Community!
The post What is Hierarchical Clustering? An Introduction appeared first on Intellipaat Blog.
Blog: Intellipaat - Blog
Leave a Comment
You must be logged in to post a comment.






