What is Big Data?
Blog: AuraQuantic Blog
Big Data is one of the many concepts that, in recent years, have gained momentum in the technological world. Simply speaking, it is a large volume of digital data that comes from different sources.
WHAT IS BIG DATA?
Big Data is not a specific technology, it is linked to other technologies related to digital information. Before delving a little deeper into the term, it is worth taking a look at some technological concepts related to data processing:
TYPE OF DATA
By ‘data’ we understand any information which is relevant for the company. For the remainder of this article we will assume that this data is digital, although in reality this is not always the case.
Structured data
This is data that is part of a predefined structure, for example an Excel sheet or an SQL database. Such data is easily cataloged and can be used for subsequent analysis and reliable predictions.
Unstructured data
This is data that does not have or isn’t part of a defined structure. For example, the body of an email, a conversation on Skype, data written in a word file, or even NoSQL databases. This data contains a lot of valuable information, but since it is not well structured and cataloged, its use is complicated when creating reports and performing analyses. The latest trends in Artificial Intelligence, especially Machine Learning algorithms, contemplate the analysis of unstructured data to obtain reliable conclusions; It is a complex and evolving field, with a very promising future.
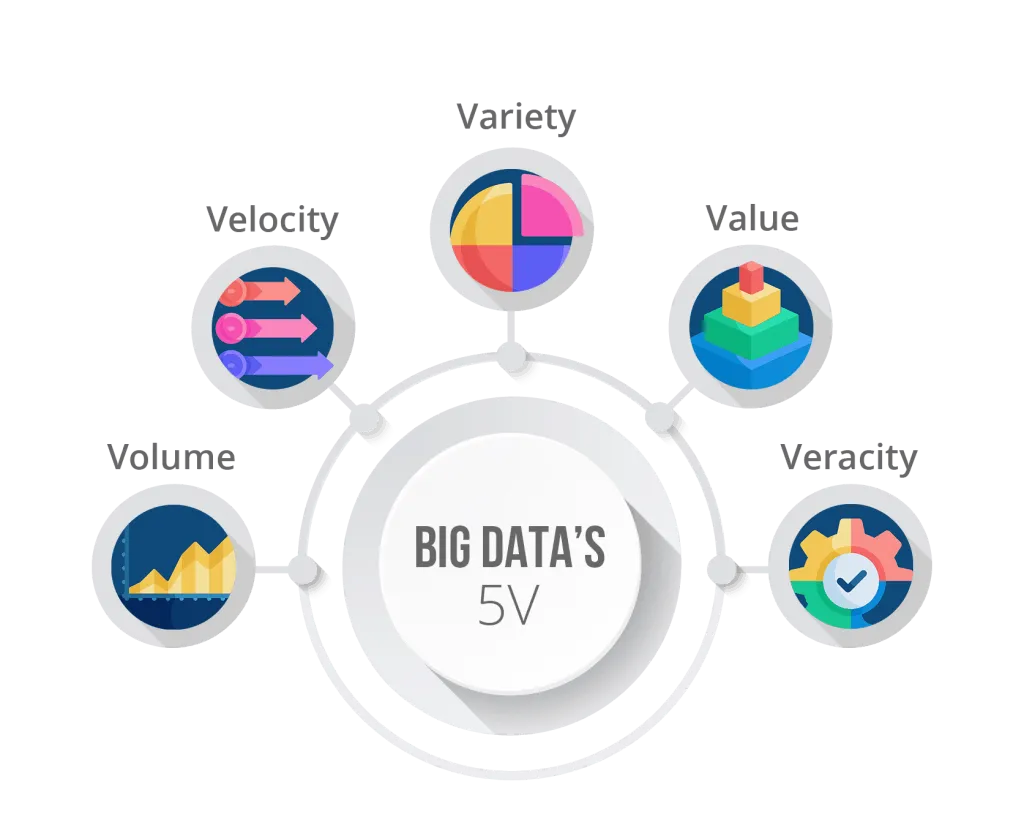
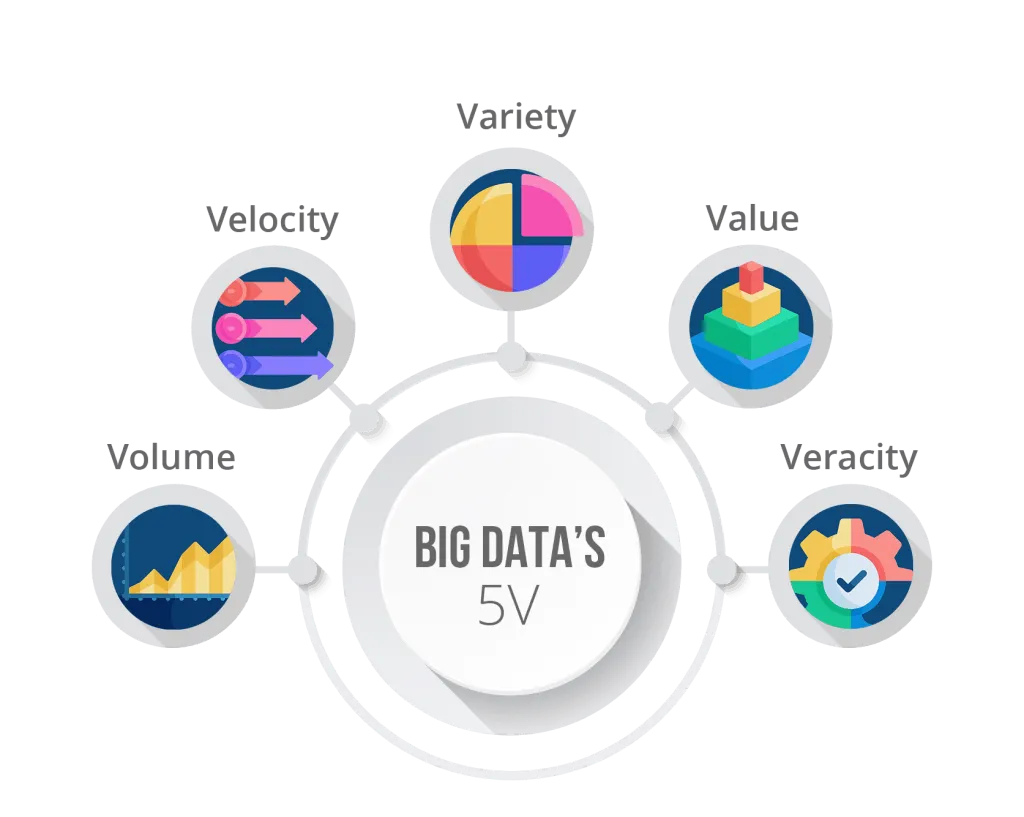
THE 5 «Vs» OF BIG DATA
Big Data is characterized by complying with the 5 «Vs», which are simply 5 characteristics of this technology.
Volume
One of the characteristics of Big Data is that new data is constantly generated. In addition, as the sources are diverse, the volume of data tends to be immense.
Velocity
Not only is a lot of data generated and from many sources, but the speed at which this data is generated tends to be very high. This causes a very difficult data flow for traditional software to manage.
Variety
Due to the unifying nature of Big Data, information that comes from very different sources must be managed. This means that, even if it is structured data, the structure is different at each source, which represents a new challenge for the company to solve.
Value
Due to the immense amount of data that must be processed, special care must be taken in choosing the data that is vital for the company and its future operations. A good definition of objectives and strategy prior to data storage will save a lot of computing time and facilitate long-term management.
Veracity
Big Data must be fed with relevant and true data. We will not be able to perform useful analytics if many of the incoming data comes from false sources or has errors.
DATA STORAGE
On Premise
This term is used to refer to local software and hardware installations (servers, racks, storage systems…). A company can be said to have an on-premise installation when it is responsible for its infrastructure, software management and data.
Cloud
The term cloud is used to refer to the use of third-party infrastructures (both hardware and software), for the storage, management and processing of data and applications. The cloud, often referred to as ‘cloud computing’, is usually a rental or pay-per-use model, and some of the leading companies in this sector are Microsoft, Amazon or Google.
Data warehouse
A Data Warehouse is a data repository that stores information from various sources and systems of the company. These data stores are notable for their great capacity and for providing optimal access to data, regardless of whether they are on-premise or in the cloud.
DATA PROCESSING
As previously mentioned, the objective of Big Data is to unify the storage and processing of different data sources in order to perform various data analysis with all company information. For correct data processing it must go through 3 phases known as ETL (Extract, Transform, Load).
Extraction
This phase consists of centralizing data captures from various sources.
Transformation
This phase tries to standardize the different data sets to achieve a similar structure at the exit. This is a complex stage that will require custom code based on the data. This phase is also known as data cleaning.
Load
This consists of storing the data in a Data Warehouse, for subsequent analysis.
BIG DATA ANALYTICS
Once we have collected, unified and cleaned the data we can begin to analyze the information in a reliable way, for which we will need specialized software.
Data Analysis
This is a later stage of data management and, although Big Data aims to establish a base on which to perform complex analysis, it is a field rather associated with Business Intelligence. That is why many of the Big Data platforms or solutions incorporate integrated analytics tools.
Big Data tools
There are different solutions in the market to manage Big Data. Some worth mentioning, with vast experience in this field, are Hadoop (standard framework for storing large volumes of data and subsequent processing distributed in clusters) and Spark (seen as a natural evolution of Hadoop’s analytics in search of more optimized models) ; Both frameworks belong to the Apache project and are Open Source.
The post What is Big Data? appeared first on AuraPortal.