

What is AWS Glue?
Amazon Glue has grown in popularity as many businesses started using managed data integration services. Mainly, Data engineers and ETL developers use Glue, to create, run, and monitor ETL workflows.
So, before moving on to “AWS Glue”, it’s better to brush up on your ETL concepts. Please refer to this blog: What is ETL for more details. We’ll go through the following topics in-depth in this Amazon Glue blog:
- What is AWS Glue?
- AWS Glue Pricing
- When to Use AWS Glue?
- Features of AWS Glue
- AWS Glue Components
- AWS Glue Architecture
- Advantages and Disadvantages of AWS Glue
- Conclusion
To get started, Watch this informative AWS Glue Tutorial YouTube Video:
What is AWS Glue?
AWS Glue is a serverless data integration and ETL service that makes discovering, preparing, and combining data for data analysis, Machine Learning, and application development simple. To enable the data integration process smoother, Glue offers both visual and code-based tools.
Amazon Glue consists of three components namely, the AWS Glue Data Catalog, an ETL engine that creates Python or Scala code automatically, and a configurable scheduler that manages dependence resolutions, task monitoring, and restarts.
The Glue Data Catalog allows users to quickly locate and retrieve data. Customization, orchestration, and monitoring of complicated data streams are also available through the Glue service.
Learn in-depth about AWS through our AWS tutorial.
AWS Glue Pricing
Amazon Glue has a starting price of $0.44. There are four distinct plans available here:
- At $0.44, ETL tasks and development endpoints are available.
- At $0.44, Crawlers and DataBrew interactive sessions are available.
- Jobs at DataBrew start at $0.48
- Monthly storage and requests for the Data Catalog are $1.00.
There is no free plan for the Glue service in AWS. It will cost about $0.44 per DPU each hour. So, on average, you’d have to spend $21 each day. However, pricing can vary by region.
When to Use AWS Glue?
Knowing all the information about Amazon Glue is not enough, you should also know where to use it. Here are some AWS Glue use cases you need to consider.
- For running serverless queries across the Amazon S3 data lake, you can utilize Glue. Amazon Glue can help you get started right away by making all of your data available at a single interface for analysis without needing to relocate it.
- To comprehend your data assets, you can use Amazon Glue. The Data Catalog makes it easy to find different AWS data sets. Additionally, by using this Data Catalog, you may save your data across several AWS services while maintaining a consistent view of your data.
- While building event-driven ETL workflows, Glue is useful. By calling your Glue ETL tasks from an AWS Lambda service, you may execute your ETL operations as soon as fresh data is available in Amazon S3.
- AWS Glue is also useful to organize, clean, verify, and format data in preparation for storage in a data warehouse or data lake.
Features of AWS Glue
Amazon Glue offers all of the features you’ll need for data integration so that you can obtain insights and put your knowledge to create new advancements in minutes rather than months. The following are some features you need to know.
- Drag and Drop Interface: Using a drag-and-drop job editor, you can create the ETL process, and AWS Glue will instantly build the code to extract, convert, and upload the data.
- Automatic Schema Discovery: You may use Glue service to create crawlers that interface various data sources. It organizes the data, extracts scheme-related information, and saves it in the data catalog efficiently. This data may then be used by ETL tasks to monitor ETL processes.
- Job Scheduling: Glue can be used according to a schedule, on-demand, or in response to an event. You can also use the scheduler to create sophisticated ETL pipelines by establishing dependencies between tasks.
- Code Generation: Without having to write proprietary code, Glue Elastic Views makes it simple to create materialized views that aggregate and replicate data across different data stores.
- Built-In Machine Learning: Glue has an in-built Machine Learning feature named “FindMatches”. It detects records that are imperfect copies of one another and deduplicates them.
- Developer Endpoints: Glue offers developer endpoints for you to modify, debug, and test the code it has created if you wish to actively build your ETL code.
- Glue DataBrew: It is a data preparation tool for users such as data analysts and data scientists to assist them in cleaning and normalizing data using Glue DataBrew’s active and visual interface.
AWS Glue Components
Before understanding the architecture of Glue, we need to know about a few components. To design and maintain your ETL workflow, AWS Glue relies on the interaction of multiple components. The following are the key components of Glue architecture.
AWS Glue Data Catalog
Glue Data Catalog is where permanent metadata is stored. To maintain your Glue environment, it provides table, job, and other control data. AWS offers one Glue Data Catalog for each account in every region.
Classifier
A classifier is the schema of your data that is determined by the classifier. AWS Glue provides classifiers for common relational database management systems and file types, such as CSV, JSON, AVRO, XML, and others.
Connection
AWS Glue Connection is the Data Catalog object that holds the characteristics needed to connect to a certain data storage.
Crawler
It is a component that crawls various data stores in a single encounter. It determines the schema for your data using a prioritized set of classifiers and then generates metadata tables in the Glue Data Catalog.
Database
A formal group of Data Catalog table definitions that are linked together is known as a database.
Data Store
A data storage is a location where you can keep your data for a long time. Relational databases and Amazon S3 buckets are two examples.
Data Source
A data source is a collection of data that is utilized as input to a process or transformation.
Data Target
A data target is data storage where the job writes the transformed data.
Transform
Transform is the logic in the code that is utilized to change the format of your data.
Development Endpoint
You can use the development endpoint environment to build and test your AWS Glue ETL programs.
Dynamic Frame
A DynamicFrame is identical to a DataFrame, except each entry is self-describing. Therefore, there is no need for a schema at first. Additionally, Dynamic Frame comes with a suite of sophisticated data cleansing and ETL processes.
Job
AWS Glue Job is a business logic that is necessary for ETL work. A transformation script, data sources, and data targets are the components of a job.
Trigger
Trigger starts an ETL process. Triggers can be set to occur at a specific time or in response to an event.
Notebook Server
It is a web-based environment for running PySpark commands. On a development endpoint, a notebook allows the active creation and testing of ETL scripts.
Script
A script is a piece of code that extracts data from sources, changes it, and loads it into destinations. PySpark or Scala scripts are generated using AWS Glue. Notebooks and Apache Zeppelin notebook servers are offered by Amazon Glue.
Table
In data storage, a table is the metadata definition that describes the data. The names of columns, data type definitions, partition information, and other metadata about a base dataset are all stored in a table.
Moving on, let’s see how AWS Glue works.
Career Transition






AWS Glue Architecture
The architecture of Glue is depicted in the figure below.
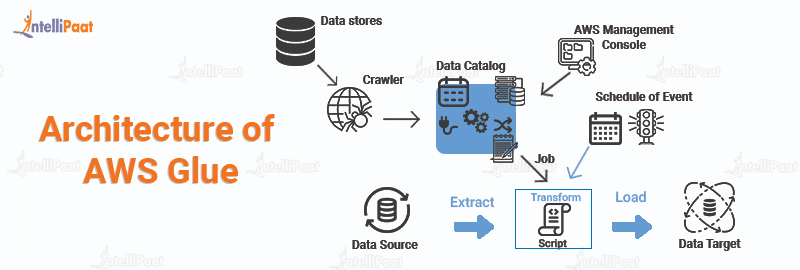
In AWS Glue, you define jobs to do the process of extracting, transforming, and loading (ETL) data from a data source to a data destination. The following are the steps you need to follow:
- Firstly, you need to decide which data source you are using.
- If you are using a data storage source then you need to build a crawler for feeding the AWS Glue Data Catalog with metadata table definitions. When you aim your crawler at a data store, the crawler fills up the Data Catalog with metadata.
- Or, if you are using streaming sources then you need to create Data Catalog tables and data stream characteristics explicitly.
- Once the Data Catalog is categorized, the data will become instantly searchable, queryable, and available for ETL.
- Then, AWS Glue converts the data by generating a script. You may also use the Glue console or API to supply the script. (In AWS Glue, the script executes in an Apache Spark environment.)
- After generating the script, You can run the task on-demand or schedule it to begin when a certain event happens. A time-based schedule or an event can be used as the trigger.
- While you run the job, the script will extract the data from the data source, transform it, and load that data to the data target as shown in the above image. In this way, the ETL(Extract, Transform, Load) job in AWS Glue succeeds.
Are you preparing for a job interview? Visit our AWS Interview Questions blog for more information.
Advantages and Disadvantages of AWS Glue
Like anything else in the world of big data computing, AWS Glue also has both advantages and disadvantages.
Here are some benefits of AWS Glue:
- Glue is a serverless data integration solution that eliminates the need to create and manage infrastructure.
- It provides simple tools for generating and following up on job activities that are triggered by schedules and events, or on-demand.
- It is a cost-effective solution. You just have to pay only for those resources you utilise during the running process of jobs.
- Based on your data sources and destinations, Glue will automatically generate ETL pipeline code in Scala or Python.
- AWS Glue may be used by multiple organisations within the company to collaborate on various data integration projects. This cuts down the amount of time it takes to analyze the data.
Courses you may like
While Glue has a lot of interesting features, it also has certain drawbacks. So, we’ll look into some of the AWS Glue limitations.
- Glue has Integration Limitations. Only ETL from JDBC and S3 (CSV) data sources works properly with Glue. If you want to load the data from other cloud services, such as File Storage Base, Glue would not be able to assist.
- Individual table jobs are not controlled with glue. The ETL process is used only to process the whole database.
- Only a few data sources, such as S3, are supported by AWS Glue. As a result, incremental sync with the data source is not possible. This means that you won’t be able to have real-time data for complicated processes.
- AWS Glue supports only two programming languages such as Python and Scala for modifying ETL scripts.
Conclusion
We explored AWS Glue through this post, which is a strong cloud-based solution for working with ETL pipelines. There are just three key phases to the user interaction procedure. You begin by using data crawlers to create a data catalog. Then you write the ETL code that the data pipeline requires. Finally, you build the ETL work schedule.
We hope you have got a complete understanding of Amazon Glue through this blog.
If you still have any questions or concerns about this technology, please post them on the AWS Community.

The post What is AWS Glue? appeared first on Intellipaat Blog.
Blog: Intellipaat - Blog
Leave a Comment
You must be logged in to post a comment.






