Update on DMN TCK
Blog: Collaborative Planning & Social Business
Last year we started the Decision Model & Notation Technical Compatibility Kit (DMN-TCK) working group. A lot has happened since the last time I wrote about this, so let me give you an update.
Summary Points
- We have running code!: The tests are actual samples of DMN models, and the input / output value force a vendor to actually run them in order to demonstrate compliance. This was the main goal and we have achieved it!
- Beautiful results web site: Vendors who participate are highlighted in an attractive site that lists all the tests that have passed. It includes detail on all the tests that a vendor skips and why they skip them. Thanks mainly to Edson Tirelli at Red Hat.
- Six vendors included: The updated results site, published today, has six vendors who are able to run the tests to demonstrate actual running compliance: Actico, Comunda, Open Rules, Oracle, Red Hat, Trisotech.
- Broad test set: The current 52 tests do a broad coverage of DMN capability. Will jump to 101 tests by mid September. Broad but not deep at this time: Now that the framework is set up, it is simply a matter of filling in additional tests.
- Expanding test set: Participating vendors are expanding the set of tests by drawing upon their existing tests suites and converting into the TCK format, and including in the published set. We are ready to enter a period of rapid test expansion.
- All freely available: It is all open source and available on GitHub.
How We Got Here
It was April 2016 that DMN emerged onto the stage of the BPMNext conference as an important topic. I expressed skepticism that any standard could survive without actual running code that demonstrated correct behavior. Written specifications are simply not detailed enough to describe any software, and particular one that has an expression language as part of the deal. Someone challenged me to do something about it.
We started meeting weekly in summer of 2016, and have done so for a complete year. There has been steady participation from Red Hat, Camunda, Open Rules, Trisotech, Bruce Silver and me, and more recently Oracle and Actico.
I insisted that the models be the standard DMN XML-based format. The TCK does not define anything about the DMN standard, but instead we simply define a way to test that an implementation runs according to the standard. We did define a simple XML test case structure that has named input values, and named output values, using standard XML datatype syntax. The test case consists purely of XML files which can be read and manipulated on any platform in any language.
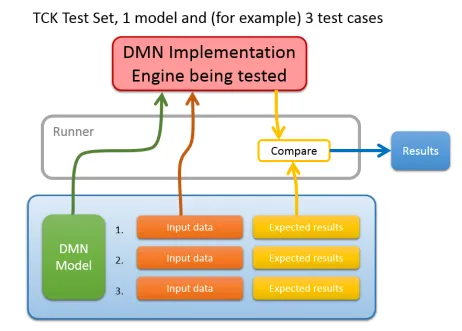 We also developed a runner, a small piece of Java code which will read the test cases, make calls to an implementing engine, and test whether the results match. It is not required to use this runner, because the Java interface to the engine is not part of the standard, however many vendors have found this a convenient way to get started on their own specific runner.
We also developed a runner, a small piece of Java code which will read the test cases, make calls to an implementing engine, and test whether the results match. It is not required to use this runner, because the Java interface to the engine is not part of the standard, however many vendors have found this a convenient way to get started on their own specific runner.
As we worked on the tests, we uncovered dozens, possibly hundreds, of places where the DMN spec was ambiguous or unclear. One participant would implement a set of tests, and it was — without exception — eye opening when the second participant tried to run them. This is the way that implementing a new language (FEEL) naturally goes. The spec simply can not get 100% on all the edge cases, and the implementation of the tests forced this debate into the public. Working together with the RTF we were able to come to a common understand of the correct behavior of the evaluation engine. Working through these cases was probably the most valuable aspect of the TCK work.
A vendor runs the tests and submits a simple CSV file with all the results back to the TCK. These are checked into GitHub for all to see, and that is the basis for the data presented on the web site. We open the repository for new tests and changes in tests for the first half of every month. The second half of the month is then for vendors that wish to remain current, to run all the new tests, and produce new results. The updated web site will then be generated on the first of the next month. Today, September 1, we have all the new results for all the tests that were available before mid August. This way vendors are assured the time they need to keep their results current.
The current status is that we have a small set of tests cases, that test a broad but shallow coverage of DMN capabilities. A vendor who can pass the tests will be demonstrating a fairly complete implementation of all the DMN capabilities, but there are only a couple of tests on each functional area. The next step will be drive deeper, and to design test that verify that the functional area works correctly in a larger number of special situations. Some of the participating vendors already have such tests available in a non-TCK format. Our immediate goal is then to encourage participating vendors to convert those tests and contribute them to the TCK repository. (And I like to remind vendors that it is in their advantage to do so, because adding tests that you already pass, makes the test suite stronger, and forces other vendors to comply to functionality that you already have.)
What this means to Consumers
You now have a reliable source to validate a vendor claim that they have implemented the DMN standard. On the web site, you can drill down to each functional category, and even to the individual tests to see what a vendor has implemented.
Some vendors skip certain tests because they think that particular functionality is not important. You can drill down to those particular tests, and see why the vendor has taken this stance, and determine whether you agree.
Then there are vendors who claim to implement DMN, but are not listed on the site. Why not? Open source: All of the files are made freely available at GitHub in standard, readily-accessible formats. Ask questions. Why would a DMN implementation avoid demonstrating conformance to the standard when it is freely available? Are you comfortable making the investment in time to use a particular product, when it can not demonstrate publicly this level of conformance to the spec?
What this means to Vendors
There are certainly a number of vendors who are just learning of this effort now. It is not too late to join. The last participant to join had the tests running in under two weeks. We welcome any and all new participants who want to demonstrate their conformance to the DMN spec.
To join, you simply need to read all the materials that are publicly available on the web site, send a note to the group using GitHub, plan to attend weekly meetings, and submit your results for inclusion in the site. The effort level could be anywhere from a couple hours up to a max of 1 day per week.
The result of joining the TCK is that you will know that your implementation runs in exactly the same way as the other implementations. You product gains credibility,and customers gain confidence in it. You will also be making the DMN market stronger as you reduce the risk that consumers have in adopting DMN as a way to model their decisions.
Acknowledgements
I have had the honor of running the meetings, but I have done very little of the real work. Credit for actually getting things done goes largely to Edson Tirelli from Red Hat, and Bruce Silver, and a huge amount of credit is due to Falko Menge from Camunda, Jacob Feldman from Open Rules, Denis Gagne from Trisotech, Volker Grossmann and Daniel Thanner from Actico, Gary Hallmark from Oracle, Octavian Patrascoiu from Goldman Sachs, Tim Stephenson for a lot of the early work, Mihail Popov from MITRE, and I am sure many other people from the various organizations who have helped actually get it working even though I don’t know them from the meetings. Thanks everyone, and great work!
