
Unsupervised Learning Part 2: The AML Connection
Blog: Enterprise Decision Management Blog

Putting innovation into production is a big theme at FICO, as we commercialize analytic breakthroughs from FICO Labs into the products our customers rely on, worldwide. Recently, this has included applying advanced unsupervised learning to money laundering, one of the many domains in which FICO technology fights financial crime.
In my first blog about unsupervised learning, I took a deep dive into this machine learning technique, which draws inferences in the absence of outcomes. In a nutshell: “Good unsupervised learning requires more care, judgement and experience than supervised, because there is no clear, mathematically representable goal for the computer to blindly optimize to without understanding the underlying domain.”
Springboarding from that blog, today’s post covers three categories of unsupervised learning that FICO has investigated, refined and put into our anti-money laundering (AML) solutions.
The State of the Art in Unsupervised Analytics
Category 1: Finding distance-based outliers relative to training points
This category of unsupervised learning quantifies “outlierness” under the principle that if a query point is close to many training points, it is considered ordinary, but if it is further from them, then it should score higher (e.g., to denote greater outlierness). These are the most well-known and intuitive approaches, and what a data scientist would typically respond with if given a pop quiz to find outliers in multi-dimensional data. Here are two classic techniques:
- Near-neighbor statistics, for example, the average distance from the query point to its M closest neighbors, with higher values corresponding to greater outlies. Arbitrariness in the metric is a difficult problem, and run-time scoring requires potentially expensive searches through saved data.
- Clustering, a technique that, in training, estimates a finite number of cluster centers, thus characterizing the dataset in a fewer number of prototypical points. Score points are determined by the query points’ distance to their closest cluster center. Clustering suffers from an arbitrary free parameter that defines the number of clusters.
These techniques hinge on the choice of metric, and excess feature cross-correlation can be a big problem. A Mahalanobis distance may help somewhat with correlation, but performs poorly with the frequently encountered non-Gaussian distributions and categorical features. Focusing on the difficulties involved in defining a proper metric becomes a matter of art and science trying to deal with cross-correlation and improper variable scaling, which emphasizes some outliers while being less sensitive to others.
Category 2: Machine learning of underlying data
Unsupervised learning methods that adapt to underlying data present a more sophisticated approach with explicit machine learning. They are less commonly used and understood than the Category 1 methods, but have some support in published scholarly and scientific literature. Based on ML concepts, these methods are more adaptive to the underlying data even when they have complex distributions and correlations.
- One-class support vector machines (OCSVMs) transform a complex geometry in the observed data into a simple geometry in an abstract kernelized space, and draw a simple outlier boundary in this space. FICO has had significant success with the OCSVM method; its best feature is the ability to learn complex boundaries observed in real, non-linear data and handle some feature correlation.
Drawbacks to OCSVM include:
- An explicit dot-product/metric is necessary in the kernel function and has major effects on results
- A significant number of training data must be stored for scoring
- The raw score has no quantitative interpretation and often has a very ugly empirical distribution
Furthermore, the training procedure for the OCSVM, like most support vector models, does not scale sufficiently to the sizes of data sets now commonly encountered.
- Neural-network autoencoders train multi-layer neural networks to predict their inputs, with a hidden layer “bottleneck” of smaller dimensionality than the original space. Outliers are those points that are less predictable than inliers. Autoencoders adapt to nonlinearity well, and explicitly reduce redundancy in inputs by mapping to a lower-dimensional manifold. In addition, being a neural network, training is easily scalable to large data set sizes, scoring is fast and score distributions are smooth.
Neural network practitioners can readily use this technique to adapt to combined continuous and categorical features. There are still some arbitrary choices in the distance metric, but the arbitrary element has less direct impact than in previously described methods in which the metric intimately controls the geometry.
Category 3: Probabilistic and topological detection
Probablistic and topological methods showcase FICO’s latest machine learning innovations; our data science team is unaware of any other technique that has all the associated advantages. FICO has developed and implemented these in our labs from scratch, mindful of our experience with the previously discussed varieties of unsupervised learning.
- Probabilistic neural-network outlier detection obtains a true calibrated probability estimate by starting from an analytically compact probability model. Bayesian principles are used to correct and enhance the first stage with a multi-layer neural network, to best represent the observed training data. With probabilistic neural-network outlier detection, training is scalable to large data sizes; scoring is rapid and provides smooth, calibrated probability estimates; and through the neural network, learns complex correlations. Furthermore, the flexibility of the starting probability model has let FICO’s data science team overcome the vexing boundaries and constraints of methods with explicit distances, such as the one-class SVM.
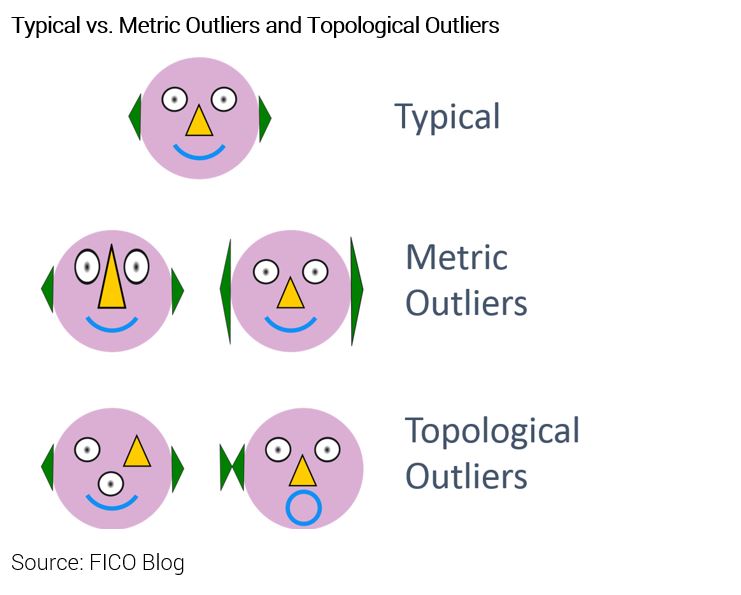
- “Topological” outlier detection finds outliers that show patterns and relationships which are rarely or never seen in the baseline data. Some new data may be an outlier compared to the training database by being exaggerations or mutations of normal data. For instance, professional athletes are outliers in being often faster and stronger than 99.9% of us. But other sorts of outliers, which we call “topological” or “structural”, are even more exotic, showing patterns and relationships never or rarely seen in the baseline data. So, compared to professional athletes, imagine an otherwise normal person who happens to have an entirely different configuration of internal organs. That individual would be a topological outlier!
Advanced Analytics for AML
FICO’s advanced analytics for anti-money laundering incorporates our most sophisticated machine learning-based outlier detection technologies. One key feature of our product is a quantification, from transaction and other data, of the degree of unusual and risky behavior that a few customers exhibit relative to the bulk of low-risk customers. Our fundamental innovations in unsupervised modeling and outlier scoring have improved the sophistication, palatability and success to tackle one of the world’s most elusive and disturbing channels: money laundering and associated crimes against humanity.
Follow me on Twitter @ScottZoldi.
The post Unsupervised Learning Part 2: The AML Connection appeared first on FICO.
Leave a Comment
You must be logged in to post a comment.






