True Parallel Service Task Execution with Flowable
Blog: Flowable Blog
Introduction
Executing tasks in parallel has been supported by Flowable since its very beginnings, most of the time using the BPMN parallel gateway. In CMMN, parallel executed tasks are the default way tasks behave (if you are not that familiar with CMMN check out our Introduction to CMMN blog series).
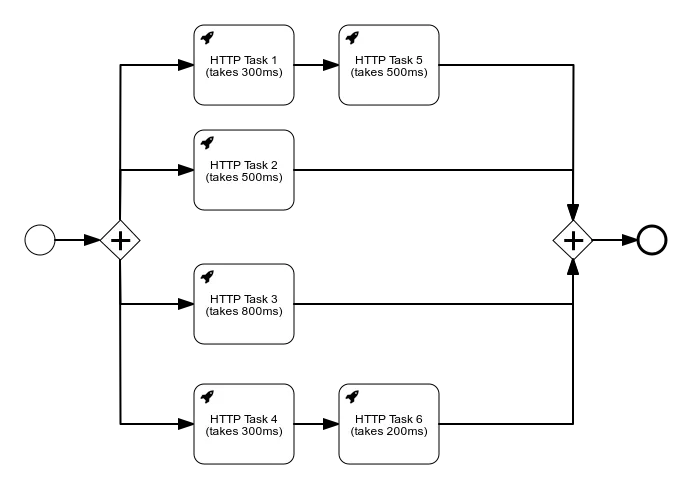
You are probably wondering what we mean by “true parallel execution” in the title. To answer that let’s do a small exercise in BPMN with some really simple HTTP Tasks. In every task name we have written how long it takes for that single HTTP Task to complete. By looking at the process below, how long do you think the following process is going to take to execute?

If you are not that familiar with Flowable or other similar workflow engines, you will probably say that it takes ~800ms for it to finish. In reality, however, this process instance actually executes in ~2.6s. Even though we have a parallel gateway depicting logical parallel business execution, the technical implementation will actually do this work sequentially, one HTTP Task after another. The main reason for this is transactionality: Flowable guarantees moving atomically from one wait state to another. The price for this is that the execution of all the tasks is single-threaded.
The Difference with the Async Flag
Some of you will immediately say: “Flowable already has a solution by making the task asynchronous, why do we need to read a new blog about parallel execution?”
Taking the example above and marking Task1, Task2, Task3 and Task4 as asynchronous will make the execution of the tasks all asynchronous, indeed (more about this can be found in Demystifying the Asynchronous Flag). However, doing this has some important caveats.
We will now have four different threads/transactions doing modifications to the same process instance. This can lead to optimistic locking exceptions when all branches join as they complete (which is completely fine, as Flowable will retry the async job if this happens). There’s a solution to that too: making those tasks exclusive. However, this means that only one single branch will be executed at a time per process instance to avoid the optimistic lock exception. In reality, this will make the execution parallel (with the possibility of spreading the load over different Flowable nodes even), but it might make a full start-to-end run slower when collisions occur and when exclusivity comes into play. Asynchronous / exclusive are thus mostly a way of spreading load across different Flowable nodes, rather than speeding up execution. Of course, using the asynchronous flag has other effects too, such as returning control to the user faster. But that’s not the focus of this post.
FutureJavaDelegates
There are use cases where the main focus is raw throughput, often in Service Orchestration, where it’s not about spreading the load. If we look at the example process model above, the natural inclination would be to say that this should be done in ~800ms, as that is the time needed for the path with the longest execution (the first and third path). The other branches are faster and shouldn’t impact the total execution time.
Exactly this is now possible with to the work we have done for the upcoming Flowable 6.6 Open Source release (the code is already there in the codebase if you want to experiemt by building the engines from source). With this, Flowable will allow you to write your own business logic so that it that it can be executed in a fully parallel way. To achieve this we are using Java 8 CompletableFutures and delegating the execution of the work to a new thread from a different thread pool, allowing the current thread to continue executing and scheduling other parallel flows.
To enable you to write true parallel business logic, we have added some new interfaces that you can use. The main interfaces are FutureJavaDelegate (for BPMN) and PlanItemFutureJavaDelegate (for CMMN). We are going to show the BPMN interfaces, but the CMMN ones have the same concept. By implementing this interfaces your business logic is automatically eligible for true parallel execution.
public interface FutureJavaDelegate<Output> {
/**
* Perform the execution of the delegate, potentially on another thread.
* The result of the future is passed in the {@link #afterExecution(DelegateExecution, Object)} in order to store
* the data on the execution on the same thread as the caller of this method.
*
* <b>IMPORTANT:</b> the execution should only be used to read data before creating the future.
* The execution should not be used in the task that will be executed on a new thread.
* <p>
* The {@link AsyncTaskInvoker} is in order to schedule an execution on a different thread.
* However, it is also possible to use a different scheduler, or return a future not created by the given {@code taskInvoker}.
* </p>
*
* @param execution the execution that can be used to extract data
* @param taskInvoker the task invoker that can be used to execute expensive operation on another thread
* @return the output data of the execution
*/
CompletableFuture<Output> execute(DelegateExecution execution, AsyncTaskInvoker taskInvoker);
/**
* Method invoked with the result from {@link #execute(DelegateExecution, AsyncTaskInvoker)}.
* This should be used to set data on the {@link DelegateExecution}.
* This is on the same thread as {@link #execute(DelegateExecution, AsyncTaskInvoker)} and participates in the process transaction.
*
* @param execution the execution to which data can be set
* @param executionData the execution data
*/
void afterExecution(DelegateExecution execution, Output executionData);
}As you can see this interface looks very similar to the JavaDelegate. There is an execute method taking the DelegateExecution and a new AsyncTaskInvoker. The AsyncTaskInvoker is a new interface that you can use to schedule work on a common shared thread pool maintained by Flowable. However, you can use your own implementation if you want to, or even reuse a CompletableFuture returned from a library that you use (for example, the Java API of Elasticsearch, MongoDB and so on do this).
Apart from the execute method there is another method (afterExecution) that is taking the DelegateExecution and the execution data. This method is invoked from the same thread and in the same transaction as the process instance and should be used to set data on the DelegateExecution once your expensive logic has completed. The DelegateExecution should not be used in the work that is scheduled on another thread; all the data that is needed should be retrieved before scheduling the work. An example implementation might look like:
public class LongRunningJavaDelegate implements FutureJavaDelegate<String> {
public CompletableFuture<String> execute(DelegateExecution execution, AsyncTaskInvoker taskInvoker) {
// This is running in the same transaction as the process instance and is still possible to set and extract data from the execution
String input = (String) execution.getVariable("input");
// The taskInvoker is a common invoker provided by Flowable that can be used to submit complex executions on a new thread.
// However, you don't have to use it, you can use your own custom ExecutorService or return a CompletableFuture from your own services.
return taskInvoker.submit(() -> {
// This is running on a new thread. The execution shouldn't be used here.
// There is also no transaction here. In case a new transaction is needed, then it should be managed by your own services
// Perform some complex logic that takes some time, e.g. invoking an external service
return "done";
});
}
public void afterExecution(DelegateExecution execution, String executionData) {
// This is running in the same transaction and thread as the process instance and data can be set on the execution
execution.setVariable("longRunningResult", executionData);
}
}Apart from the FutureJavaDelegate, there are two other interfaces that can make it easier for you to implement your business logic:
- FlowableFutureJavaDelegate<Input, Output> – Can be used when you don’t need a custom way of creating the CompletableFuture and Flowable will do the scheduling for you via the AsyncTaskInvoker. It provides a hook point to create the input data on the same thread as the transaction and an execute method that does not return a CompletableFuture
- MapBasedFlowableFuture – An interface that exposes a snapshot of the delegate execution as input data for the execution and a map as the result of the execution. All entries of the resulting map will be stored on the delegate execution.
The example implementation above can be created in the following way with the MapBasedFlowableFutureJavaDelegate:
public class LongRunningJavaDelegate implements MapBasedFlowableFutureJavaDelegate {
public Map<String, Object> execute(ReadOnlyDelegateExecution execution) {
// The execution contains a read only snapshot of the delegate execution
// This is running on a new thread. The execution shouldn't be used here.
// There is also no transaction here. In case a new transaction is needed, then it should be managed by your own services
// Perform some complex logic that takes some time, e.g. invoking an external service
Map<String, Object> result = new HashMap<>();
result.put("longRunningResult", "done");
// All the values from the returned map will be set on the execution
return result;
}
}Apart from having support for true parallel execution by using a delegate, we also support such executions for service tasks with an expression returning a CompletableFuture. If a result of an expression for a Service Task returns a CompletableFuture we continue executing parallel flows and, once the future is done, we will continue on the path of that flow.
How are we achieving this?
We’ve shown what you need to do to achieve true parallel execution with Flowable. Let’s have a quick look at how this is implemented, and why we didn’t do this before.
The main solution consists of splitting up the execution of the delegate classes into different phases. Phases that work on execution data (such as variables) are scheduled to run on the calling thread and participate in the existing transaction. This avoids, for example, the problem of joining multiple asynchronous paths that need to join data on the same entities, as described above when using the asynchronous flag. The actual logic, which uses this data as input and produces output data, is then planned in a phase using a separate thread pool. Eventually, all paths of execution and their results are merged in a phase that is, again, transactionally safe.
We’ve had this feature on our radar for many years. The main reason it took a while to get here is that it is technically difficult to implement. The original V5 architecture was not meant for things like this, and the way it was being executed meant that it is extremely difficult to achieve this. Mind you, not impossible (it’s all code after all), but cumbersome and, from our experience with the V5 architecture, error-prone to maintain for all use cases.
However, with the V6 architecture and recent refactorings we’ve made, this became easy to achieve. All the operations are planned on an Agenda (all the engines, BPMN/CMMN/DMN/… work like this), which allows us to plan special operations that are going to check if a future has completed or not when the agenda has no remaining normal operations. This allows the execution to continue for other parallel flows that are already planned on the agenda. Once there are no more normal operations, we execute an operation that will block until any one of the planned futures complete (keeping the transaction open). The completion of this future will allow the planning of new normal operations on the agenda, which can then be executed. This will continue until we reach a wait state and there are no more operations of any kind (including futures) to be executed in this transaction.
This is of course a simplification of how it’s implemented. If you are interested in the low level details then we suggest you look at this PR that added this functionality.
True Parallel HTTP Tasks
Coming back to the example in the introduction, we used HTTP Tasks. By default in Flowable 6.6+, HTTP Tasks are not executed using this true parallel approach. We decided to keep it this way to ensure the order of the execution remained the same for any currently running processes and to give the control to you to decide whether you want them to be executed in the same thread or a new one. To achieve this we added a new BPMN and CMMN extension attribute, flowable:parallelInSameTransaction, that can be set to true to execute the HTTP Task using the new parallel method. When that attribute is not set then the global defaultParallelInSameTransaction from the HttpClientConfig in the BPMN and CMMN engine configuration is used to decide how it should be executed.
We’re currently working on a Benchmark where we will show you the difference between the true parallel execution and the synchronous parallel execution of the Flowable HTTP Tasks. We are also experimenting with using HTTP NIO as well as the Spring WebClient to achieve even higher throughput.
Stay tuned for more information this topic very soon on!