
Top 10 Tips for AWS Disaster Recovery Plan
In this blog, you will learn what an AWS disaster recovery plan (DRP) is as well as how to leverage the functions in your AWS console to recover from a disaster or prevent the disaster in the first place.
- What is an AWS Disaster Recovery Plan?
- Possible Cloud Disasters
- Why the need for an AWS disaster recovery plan?
- 10 Tips to Develop an AWS Disaster Recovery Plan (DRP)
- Identifying Critical Resources and Assets
- Recovery Time Objective (RTO) and Recovery Point Objective (RPO)
- Choosing a Disaster Recovery Planning Method
- Implementing Security and Corrective Measures
- Testing Plan before Implementation
- Schedule Maintenance
- Data Backup
- Cross-region Backups
- Multi-factor Authentication
- Third-party Disaster Recovery-as-a-Service (DRaaS)
- Conclusion
Robust AWS disaster recovery methods can help organizations immensely when trying to stay up and running during a disaster.
Curious about AWS? Watch this video to learn all about it.
What is an AWS Disaster Recovery Plan?
A DRP is a structured and detailed plan of action aimed at helping systems and networks recover whenever there is a failure or attack. The main objective is to help an organization get back to an operational state as quickly as possible.
On-premises AWS disaster recovery solutions typically incur heavy implementation and maintenance costs. As a result, most organizations turn to disaster recovery tools and solutions that are provided by cloud vendors. These solutions are, sometimes, also offered by third-party vendors. For instance, companies such as MSP360 and N2WS offer disaster recovery solutions specifically tailored to AWS.
AWS users can benefit heavily in the following ways from developing a DRP and having it at their disposal as it can help in:
- Minimal data loss through replication intervals
- Reduced downtime by quick restoration of critical applications
- Distributed risk through AWS cross-region disaster recovery
- Quick bounce-back rate and restoring operations through quick file and data retrieval
Possible Cloud Disasters
- Natural disasters: Natural disasters include bad weather conditions, floods, earthquakes, etc. Natural disasters have the capacity to disrupt cloud services, and the server that hosts the cloud service will require instant disaster recovery operations.
- Technical disasters: Power failures and loss of network connectivity are two of the more obvious technical disasters that can happen when it comes to cloud technology.
- Human disasters: Human failures are some of the more common occurrences. Oftentimes, these are accidents that happen while one is using cloud services. Cases like inadvertent misconfiguration, malicious third-party access, war, stolen servers, etc., are all considered human disasters.
Why the need for an AWS Disaster Recovery Plan?
To get a smooth operating business, establishing protocols and contingencies for disaster recovery is critical. A company with these in place can minimize disruption of services at its best in the event of a disaster. As a result, the overall damage is reduced.
Reduced service interruption means a reduced loss of revenue. Due to this, even user dissatisfaction is reduced.
Quantifying areas such as RTO and RPO (we will discuss more on this later in the blog) allows an organization to identify its optimal protection level for disaster recovery. Based on these parameters, organizations can choose appropriate protocols to apply backups and multiple servers.
Learn under industry experts and get your AWS Certification from Intellipaat.
10 Tips to Develop an AWS Disaster Recovery Plan (DRP)
As AWS does not come with its own DRP, developing an AWS DRP requires a certain degree of creativity and resourcefulness. However, one can make use of AWS to build a customized DRP, by repurposing some of the features and tools offered by AWS.
Using the following tips and tools and leveraging the AWS environment, one can develop a DRP on their own.
Identifying Critical Resources and Assets
A business impact analysis (BIA) can help to draw up a picture of critical resources and assets that can have a more damaging impact in the event of a threat. It can also help one to get a preview of the potential impact of a disaster on operations.
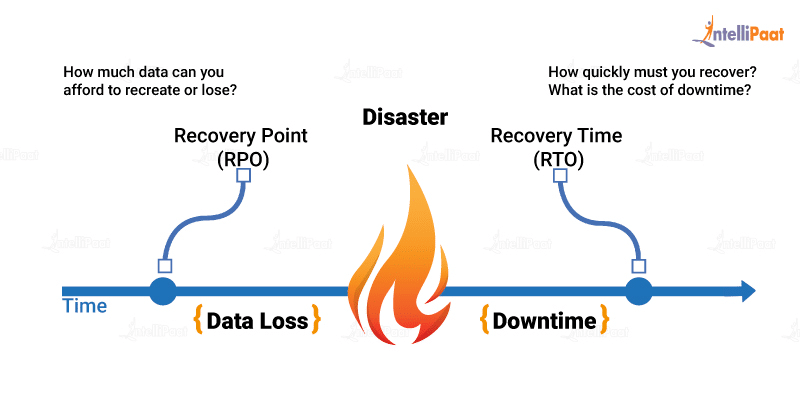
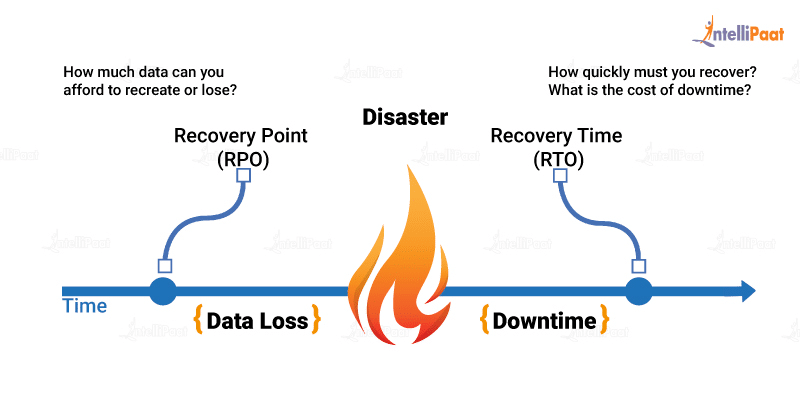
Recovery Time Objective (RTO) and Recovery Point Objective (RPO)
A DRP allows an organization to define its RTO and RPO.
The maximum acceptable delay between the service interruption and its continuation is referred to as the RTO. One should be aware of the system downtime that their organization can afford to avoid irrecoverable monetary damage. Therefore, calculating the RTO is critical for a recovery plan to be a success.
RPO, on the other hand, lets one gauge how much data loss an organization can afford before incurring hefty damage. It is the maximum amount of time between data recovery points. For instance, if losing six hours of data will result in heavy loss, then an RPO of less than six hours will need to be accounted for.
One should simultaneously map out the RPOs and RTOs keeping in mind the money, time, and reputation of the company. The measurement of RTOs and RPOs will prepare one for any kind of unexpected shortcomings that may surface.
Choosing a Disaster Recovery Planning Method
According to an organization’s requirements and preferences, there are four main recovery methods to choose from:
- Backup and Restore
Regularly backing up and restoring data can be a managed solution but the recovery time is the longest this way. Restoration consumes a lot of time and resources as the data is not on standby. AWS S3 is an ideal solution that offers data backup.
Data backup is only half the story. Data recovery needs to be tested and carried out quickly and reliably. Systems should have a configuration with appropriate data retention, data security, and testing of data recovery processes.
Here are the key steps for backup and restore:
- Choose an appropriate tool or method for backing up data into AWS
- Ensure that an appropriate retention policy for the data is in place
- Ensure the presence of appropriate security measures, encryption, and access policies
- Test the data recovery and restoration of the system regularly
- Pilot Light
This is similar to backup and restore, but the most critical core elements and data of your system are already configured and running in AWS, the pilot light, for quick retrieval. During recovery, a full-scale production environment is quickly provisioned around the critical core.
Pilot light has a quicker recovery time than backup and restore. Aside from the already running and up-to-date system core pieces, there are still some installation and configuration tasks for the full recovery of applications.
The provisioning and configuration of the infrastructure resources are automated by AWS. This saves time and helps avoid human errors.
- Warm Standby
Warm standby involves duplicating the system’s core elements and having them run on standby at all times. During a disaster, the duplicate version can be promoted to primary to continue operations. As a result, this method further decreases the recovery time.
In this method, the business-critical systems are duplicated on AWS and they are always on. Warm standby is not built to take the full production load. However, it is fully functional. These servers may run on a minimum-sized fleet of AWS EC2 instances on the smallest sizes possible. This method can be used for non-production work such as quality assurance, testing, internal use, etc.
In the event of a disaster, system scale-up is done quickly to handle the production load. In AWS, this is possible through the addition of more instances to the load balancer and the resizing of the low-capacity servers to run on larger EC2 instance types. Whenever possible, horizontal scaling is preferred over vertical scaling.
- Multi-site Solution on AWS and On-site
A multi-site solution is one that runs in AWS as well as on the on-site infrastructure that exists in an active-active configuration. The data replication method is determined by the recovery point chosen. Various types of replication methods are available.
Amazon Route 53, a weighted DNS service, routes production traffic to different sites. A part of this traffic goes to the AWS infrastructure and the rest to the on-site infrastructure.
In the event of an on-site disaster, the DNS weighting can be adjusted and all traffic can be sent to the AWS servers. The AWS service capacity can be quickly increased to enable handling of the full production load. EC2 auto-scaling helps automate the process. However, some application logic will be required to detect the failure of the primary database services and move over to the database services running in AWS parallelly.
Going for an interview? Check out our complete list of Amazon AWS Interview Questions!
Implementing Security and Corrective Measures
One can implement security measures such as server and network monitoring software. One can also implement corrective measures as remediation tools. These measures can help with system restoration after a disaster.
Testing Plan before Implementation
During the development of the AWS DRP, testing should be scheduled to detect flaws before the implementation of the DRP. This ensures a well-oiled plan before any disaster hits or any kind of threat occurs.
Schedule Maintenance
The AWS DRP should be updated on a regular basis to catch up with system changes. As a result, in the aftermath of a disaster, it is possible to improve the plan to prevent future disasters, failures, or attacks.
Data Backup
Scheduling regular backups, sometimes, would not suffice in the face of a disaster. Quick data access is crucial in these kinds of situations. If the AWS DRP is detailed and up to date, it would allow for data backup recovery and restoration from the cloud environment with minimal downtime.
Career Transition






Cross-region Backups
When trying to come up with an AWS DRP, it is necessary to decide where to store critical data. To avoid impact on the entire system, it is advisable to have data distributed across different availability zones (AZ) around the world.
For example, S3 allows for data to be duplicated by default in several locations within a region ensuring high durability. This, however, does not remove the risk of data loss in a given region. To prevent this, the cross-region replication option for S3 can be used. It automates the copying of data to a designated bucket in another region.
For the deployment of a multi-region, multi-master database, one can also use global tables in DynamoDB. This spreads the changes across several tables. With the distributed data across different regions, the risk of data loss is minimized.
Multi-factor Authentication
It goes without saying that root passwords and credentials should be kept secure and hidden from unauthorized users. To prevent internal threats, it is a good idea to disable the programmatic keys once they are used. Having a multi-factor authentication solution can prevent the administrator and programmatic privileges from falling into the wrong hands.
Third-party Disaster Recovery-as-a-Service (DRaaS)
While it may seem like implementing all steps of a DRP in-house is a better solution, it is not the case for smaller companies. This is due to the absence of a dedicated IT team. In situations like these, third-party solutions are much more practical.
Disaster Recovery-as-a-Service (DRaaS) is primarily to help organizations develop, implement, and maintain their DRPs. This enables the organizations to focus on growing their business.
Conclusion
Disasters can prove to be a threat to the availability of an organization’s workload. However, AWS Cloud Services can minimize or remove these threats. The first thing to do is to understand the business requirements for the workload. This helps to choose the appropriate disaster recovery strategy. Then, with the help of AWS services, a suitable AWS disaster recovery architecture can be designed to achieve the RTO and RPO as per the business requirements.
Have you checked out our AWS community? Get all your AWS questions answered by our experts.
The post Top 10 Tips for AWS Disaster Recovery Plan appeared first on Intellipaat Blog.
Blog: Intellipaat - Blog
Leave a Comment
You must be logged in to post a comment.






