“Been there, done that” — a reaction both to the idea of resurrecting the failed portal concept and to the thought that respectable folks still see knowledge as manageable, in this, the Internet era, when facts, opinions and expertise move at light speed.
Not the Whole Story
There’s little exciting in KM as it has long (although serviceably) been defined, as the industry has long conceived it.
Industry’s idea is that an enterprise can beneficially manage knowledge by a) storing and organizing documents and providing a search function and b) cataloging employee abilities and facilitating collaboration. This approach works for some, but in my view, it delivers half-truths.
It ignores the information inside documents. It ignores enterprise-relevant knowledge and expertise that resides outside an organization’s boundaries, out in the wild-and-wooly online and social universe.
It largely ignores the social voice of the customer, business partner (and competitor) information, the wisdom of communities of practice and industry authorities, and the like.
KM’s short-comings aren’t going to be overcome solely, or primarily, by better data hygiene or consistent approaches to applying metadata, or by putting a new face — a reworked portal — on the same old searchable document sets. What’s needed?
A NewKM Need
My view: It’s time to bring knowledge to knowledge management, via:
- Analytics, specifically, exhaustive information extraction (and not just searchable documents) and then data mining to identify links and associations;
- An end to artificial boundaries, to neglect of extra-mural information;
- Purpose-driven, ad-hoc communities and collaboration (and not just rosters of experts); and
- Actual facts and connections, as captured in social and knowledge graphs.
Information extraction (IE) is the resolution of entities, pattern-based information such as events, topics, concepts, sentiment, and relationships of interest within source media, whether text, images, audio, or video.
IE may involve structural, statistical, and machine learning (ML) methods, that is machine intelligence or AI. Whatever the method applied, the aim is to discover relevant data wherever it occurs.
The graphs I’m referring to are network and property graphs, data structures that capture entities of interest — whether people, places and organizations or products, components and parts or something else — and their attributes and interconnections, as nodes, annotations and edges.
Two Paths
Seth Earley, whose portal article I cited (and who is a CMSWire contributor), is deservedly a recognized information-management authority. His views and mine do align to an extent, judging from a concluding line in his article.
He observes that “organizations are weighed down with legacy technologies” and that access difficulty stems primarily from “the underlying structures of corporate content and data.”
He expects that “knowledge management portals will continue to evolve with machine learning, natural language processing (NLP) and social collaboration integration.”
Replace “management portals” in that sentence and you’re golden. It’s knowledge we should focus on!
In other words, knowledge discovery will continue to evolve with machine learning (ML), natural language processing (NLP) and social collaboration integration.
As for portals as an access mechanism, they will remain a choke-point, given all the enterprise-relevant information they can’t get at. And while the tired document-centered data structures that sit behind KM portals will become more flexible via ML, NLP and collaboration, what you get out of them will continue to be records rather than knowledge.
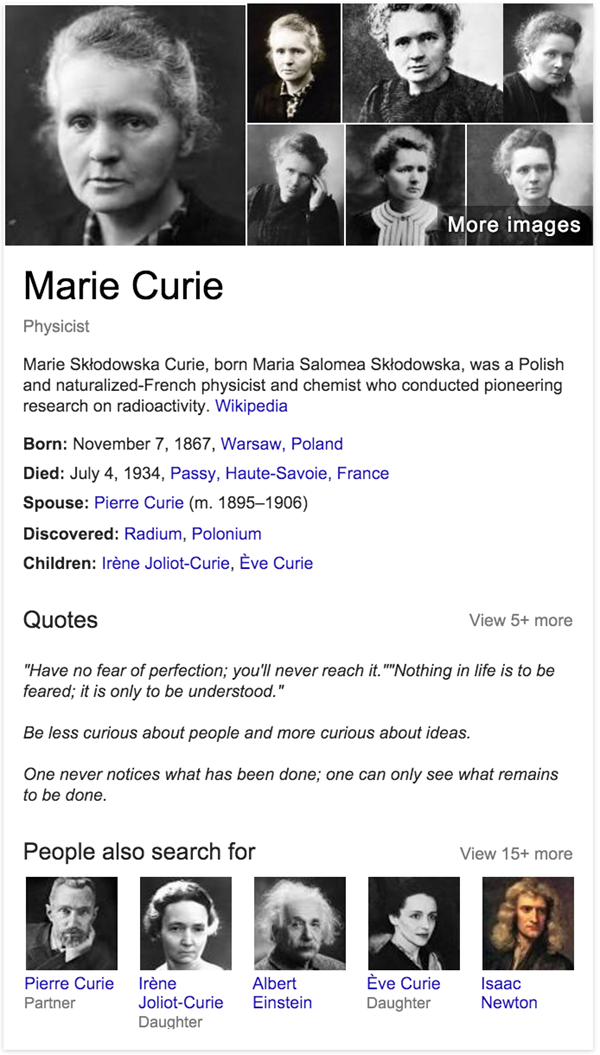
Knowledge — search-retrieved, interrelated facts — as captured in Google’s Knowledge Graph
Some Get It – Somewhat – and Some Don’t
Judging from the agenda of last November’s KMWorld conference (where I spent a day), the broad KM community — unlike Seth Earley — largely doesn’t get analytics, openness, network or knowledge bases.









