Simplify Kubernetes debugging with declarative logic
Blog: Drools & jBPM Blog
We put Drools inside Kubernetes’ control plane …you wouldn’t believe what happened next! 😉
This is a longer post on the current status of explorations with RuleOps; you may want to skim or skip to different sections, depending on your interests.
| RuleOps in a nutshell |
| Read time: ~ 1 minute Kubernetes is an orchestration platform, very powerful but also complex with multiple layers of abstraction, interdependent components, relying on automation and orchestration to manage deployments; this can make it difficult at times to pinpoint the actual root cause of an issue when troubleshooting. We have coined the terms RuleOps to identify both the abstract concept and the actual solution which can pragmatically be of support in many of those scenarios: 1. In the context of RuleOps, we believe that a declarative approach helps a lot while defining the root cause analysis, troubleshooting concepts, standard operating procedures (SOP), and is an effective instrument to help in debugging and troubleshooting Kubernetes operations. 2. We have developed a real application (based on Drools and Quarkus), which can be used from the command line as well as a continuously running application on a control plane, which demonstrates in practice the RuleOps concepts and techniques. We have implemented some best-practice troubleshooting guides available on the public domain as well as built PoC on some real SOP used by teams that we know. We believe RuleOps is valuable research exploration and a tangible, pragmatic, helpful instrument you can start to use in your day-to-day when managing a Kubernetes cluster. |
Introduction to RuleOps
DevOps practitioners who interact daily with Kubernetes throughout its control plane know the problem of having to apply different resources, through different interactions. Every DevOps engineer has experienced the feeling of having forgotten to create a specific resource, having the cluster in an unknown state or not being sure about what is the best action to do next to continue troubleshooting.
For example: if a Pod fails to start, it may be due to a misconfiguration in the Deployment, a problem with the container image, or an issue with the required resources on the cluster itself.
For another example: a DevOps team has several configurations in place to ensure two namespaces are properly isolated and related policies to segment the network in the cluster; this requires performing checks and maintenance to mitigate the risk of configuration drift, across the lifecycles of application deployments and other general operations on the cluster.
Troubleshooting may require digging through a variety of logs, configurations and exercising other debugging techniques.
RuleOps solves this problem by providing a toolchain to help users writing custom rules that will check the consistency of the cluster and more generally speaking, the health of the system.
In the following we’ll see some theory behind RuleOps and how it can detect problems in your cluster Control Plane, with a real demo showing the actual rules the users can model and define.
Here are some of the topic we’ll cover:
- The team managing the cluster can use RuleOps as a foundation to align on the definition of a healthy system (for example, define what is the expected relationship between resources being developed, define what are the requirements of a strict cluster security configuration), by providing specific checks beyond what Kubernetes can perform out-of-the-box, also correlating internal and custom resources with a high-level declarative language especially optimized for executing a large number of checks.
- RuleOps provides useful information about the issues so that DevOps and SRE can easily understand and resolve the issue.
- The checks and the rules provided can be packaged in a series of reusable components that can be shared throughout the different DevOps.
- In addition to that, RuleOps provides general rules that apply to most common error-cases that improves the debug experience of a vanilla cluster.
After understanding RuleOps, users can start defining their own rules to fix the most common Kubernetes problems.
Benefits to the Kubernetes Ecosystem
We strongly believe that RuleOps with its powerful declarative language based on symbolic AI reasoning can help the Kubernetes ecosystem in building more healthy cloud based application, by detecting anomalies in the control plane configuration and improving on the amount of time DevOps and SREs will take to find and resolve problem in a Kubernetes cluster.
In addition to that, we’d like to provide some contributions to the conversation on how to improve the robustness of Kubernetes with external tools.
Various tools such as monitoring are already available; our focus is to offer the full power of a symbolic AI rule engine in this space.
More specifically, even though Kubernetes by itself is a mature project and it’s meant to be reliable and consistent, once App Developers start building applications using the Kubernetes API a whole new set of problems emerge, i.e. how to handle the lifecycle of the custom resources, or how to make sure that error messages from the cluster are useful to the developers that need to detect inconsistent scenarios.
Day-2 operations are especially affected, as these broken scenarios will need clear and solvable error messages even after the application has been deployed and it’s currently running.
Why RuleOps
We believe it’s important to highlight that in Kubernetes the etcd key-value store is used as the Source of Truth but, on the other hand, typically operations on the cluster (e.g.: through kubectl apply ) are performed on several resources at different times, while the global configuration of the cluster is inherently eventually-consistent in nature.
This could lead to a global or local configuration drift for cluster resources, and in some way a semantically inconsistent state of the cluster; the probability of reaching such an inconsistent state also correlates with the number of operations performed on the cluster.
What we strive to do with RuleOps, in this whitepaper and demo, is to put more Dev skills inside of DevOps: from the software development principles we have a lot of debugging instruments which are at the core of our discipline and at the same time debugging can also be further complemented with a lot of automation using AI (Artificial Intelligence) as we will see in this content. We don’t want to overlook a potential opportunity for process improvement benefitting operations on the kubernetes cluster.
We are also aware that AI these days is quite a buzzword, but what we mean for AI in this context is a very pragmatic AI approach, specifically focusing on Rule Engine (previously related to expert systems) and a symbolic AI, used for Knowledge Representation and Reasoning (KRR). Throughout the rest of this document, when we refer to AI, kindly keep this smaller disclaimer in mind.
State of the art in Debugging Kubernetes
A quick google search can sometimes be used as a litmus test for the actual day to day reality, especially when facing the needs of “Debugging Kubernetes” operations. The fact that such query returns millions of results and plenty of courses, videos, and other training material is a clear indication that is a hot topic and likely a problem without a trivial solution, but at the same time an opportunity for people to acquire new knowledge, undergo training, and improve their skills.
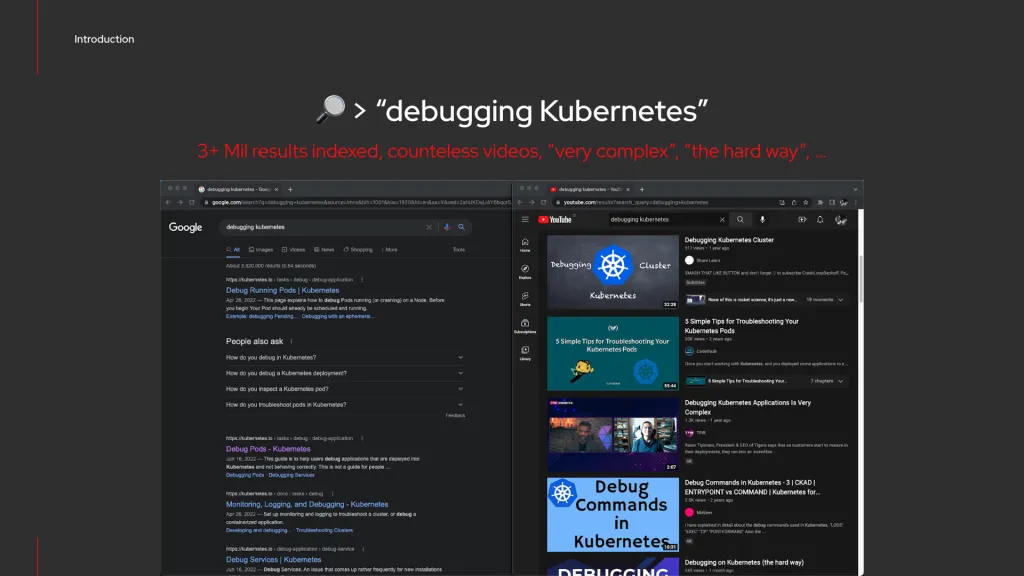
Another interesting consideration is that many of these “debugging kubernetes” resources are in the form of flowchart, decision tree, or more specifically if-this-do-that, when-this-do-that guides. This is interesting because it expresses a semantic reasoning, which can find a natural translation and equivalent in a semantic rule, such as DRL for Drools (but not limiting to DRL).
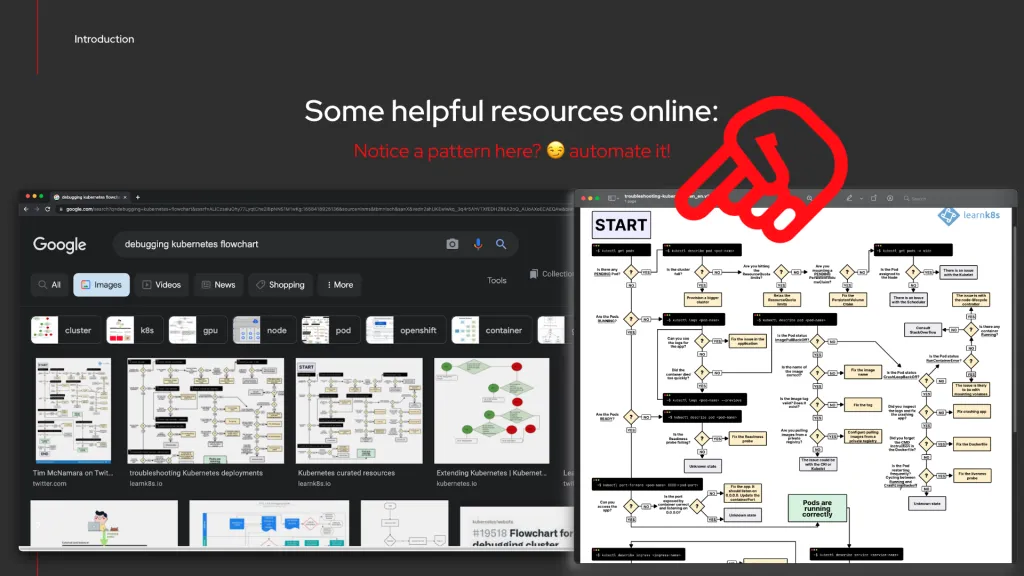
For example: many times the knowledge in these types of resources resembles “please check these things first, if those fail, then check these other things …” in order to provide a framework to identify the root-cause of the problem; once the root-cause has been identified, corrective actions can be effectively performed.
This is the perfect opportunity to automate all of this with KRR and a rule engine, such as Drools!
What RuleOps means
We coined the term RuleOps as an evolution of the term DevOps name.
DevOps is a compound name that brings together Development and Operations; we want to play on the term itself and add to the mix also the Rules as coming from rule engine: we believe that the declarative power that can be expressed with the rule definition, together with a lot of the features that are typical of rule engine (such as Drools) really make it a perfect fit for debugging, inspecting and automating a lot of the semantic reasoning on the cluster resources and on the cluster status.

Demos
In this section, we present with pragmatic examples and real demo and working prototypes, some application of the RuleOps concepts.
Demo: “Relax the ResourceQuota limits for Deployment”
For the first example we would like to make reference to a tutorial in the kubernetes documentation titled “Configure a Pod Quota for a Namespace”.
Drawing inspiration from that tutorial, we simulate instead the case where a Deployment no longer fit the configured ResourceQuota on the cluster with:
apiVersion: v1
kind: ResourceQuota
metadata:
name: pod-demo
spec:
hard:
pods: "2"
and:
apiVersion: apps/v1
kind: Deployment
metadata:
name: pod-quota-demo
spec:
selector:
matchLabels:
purpose: quota-demo
replicas: 3
template:
metadata:
labels:
purpose: quota-demo
spec:
containers:
- name: pod-quota-demo
image: nginx
Preparing this experiment on a Minikube-based lab environment, accessing the dashboard we can see the deployment is grayed out:
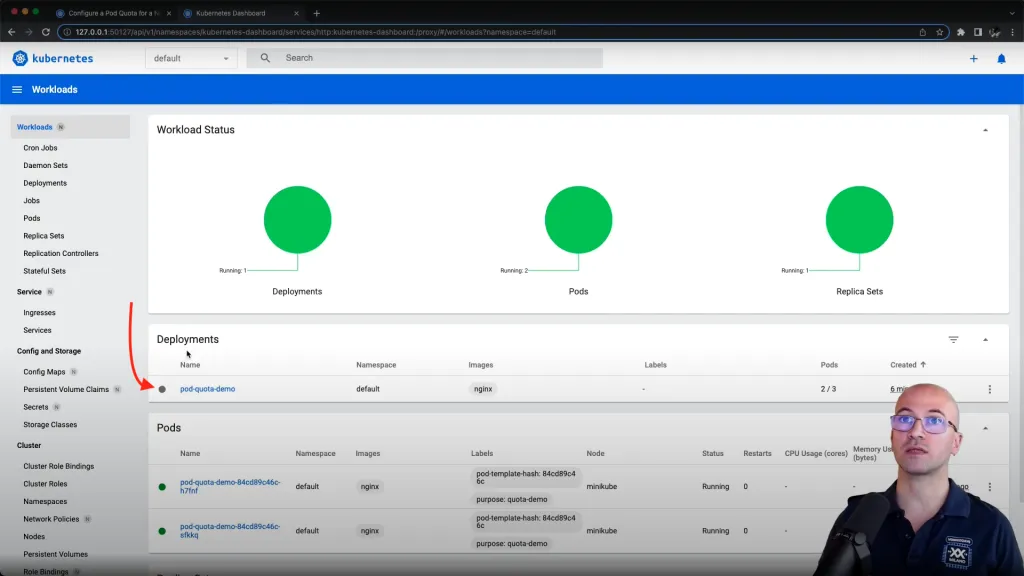
This scenario can easily be governed by defining a semantic rule using the domain model of kubernetes and in the rule example below we are correlating some of deployment conditions on the actual deployment:
- name: Relax the ResourceQuota limits Deployment PENDING
when:
- given: Deployment
as: $d
- given: DeploymentCondition
having:
- type == "Available"
- status == "False"
from: $d.status.conditions
- given: DeploymentCondition
having:
- message contains "exceeded quota"
from: $d.status.conditions
then: |
insert(new Advice("Relax the ResourceQuota limits", ...
And the RuleOps interface provide the defined advisory:
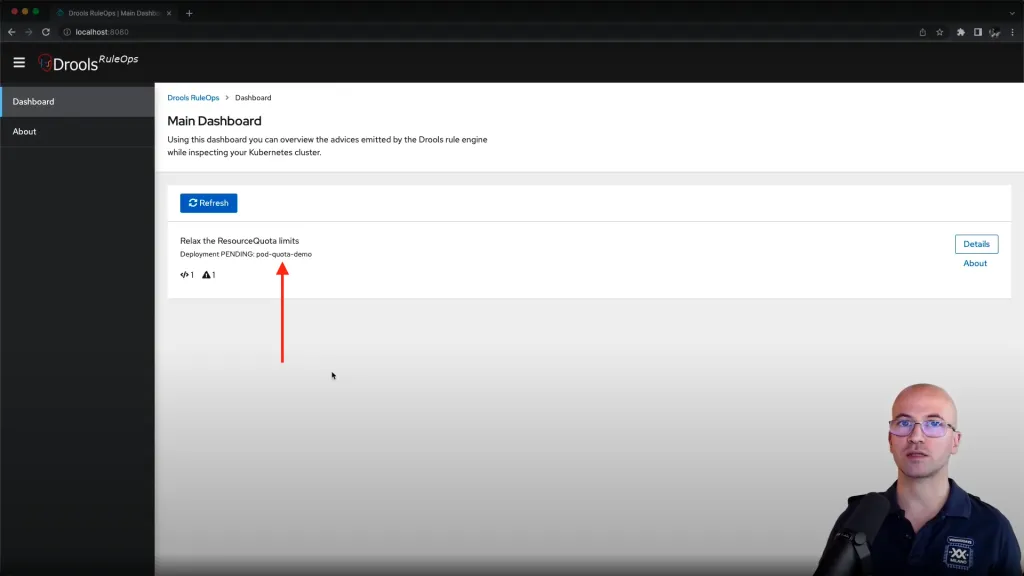
This is a very first example on how to implement a declarative rule on a concept which was expressed by the troubleshooting debugging flowchart section, and instead of manually performing some checks, we automated the same checks in a declarative way.
Demo: “Relax the ResourceQuota limits for StatefulSet”
In this example we would like to make reference to another tutorial in the kubernetes documentation titled “Configure Memory and CPU Quotas for a Namespace”.
Drawing inspiration from that tutorial, we simulate instead the case where a StatefulSet no longer fit the configured ResourceQuota on the cluster with:
apiVersion: v1
kind: ResourceQuota
metadata:
name: mem-cpu-demo
spec:
hard:
requests.cpu: "1"
requests.memory: 1Gi
limits.cpu: "2"
limits.memory: 2Gi
and
apiVersion: v1
kind: Pod
metadata:
name: quota-mem-cpu-demo
spec:
containers:
- name: quota-mem-cpu-demo-ctr
image: nginx
resources:
limits:
memory: "1Gi"
cpu: "1"
requests:
memory: "600Mi"
cpu: "500m"
and finally
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app.kubernetes.io/version: 1.0.0-SNAPSHOT
app.kubernetes.io/name: hello-pvdf
name: hello-pvdf
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: hello-pvdf
app.kubernetes.io/version: 1.0.0-SNAPSHOT
serviceName: hello-pvdf
template:
metadata:
labels:
app.kubernetes.io/version: 1.0.0-SNAPSHOT
app.kubernetes.io/name: hello-pvdf
spec:
containers:
- env:
- name: KUBERNETES_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: PVDF_DIRECTORY
value: /mnt/data
image: quay.io/mmortari/hello-pvdf:1.0.0-SNAPSHOT
imagePullPolicy: Always
livenessProbe:
failureThreshold: 3
httpGet:
path: /q/health/live
port: 8080
scheme: HTTP
initialDelaySeconds: 0
periodSeconds: 30
successThreshold: 1
timeoutSeconds: 10
name: hello-pvdf
ports:
- containerPort: 8080
name: http
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /q/health/ready
port: 8080
scheme: HTTP
initialDelaySeconds: 0
periodSeconds: 30
successThreshold: 1
timeoutSeconds: 10
resources:
limits:
cpu: 2000m
memory: 2Gi
requests:
cpu: 500m
memory: 500Mi
volumeMounts:
- mountPath: /mnt/data
name: my-pvc-claim
readOnly: false
terminationGracePeriodSeconds: 10
volumeClaimTemplates:
- apiVersion: v1
kind: PersistentVolumeClaim
metadata:
labels:
app.kubernetes.io/version: 1.0.0-SNAPSHOT
app.kubernetes.io/name: hello-pvdf
name: my-pvc-claim
namespace: default
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Mi
storageClassName: standard
Preparing this experiment on a Minikube-based lab environment, accessing the dashboard we can see the stateful set is grayed out:

This scenario can also be governed very easily by defining a declarative rule, again using the domain model of kubernetes correlating event from the StatefulSet:
- name: Relax the ResourceQuota limits StatefulSet PENDING
when:
- given: StatefulSet
as: $s
having:
- spec.replicas != status.replicas
- given: Event
having:
- message contains "exceeded quota"
from: DroolsK8sClient.eventsFor($s)
then: |
insert(new Advice("Relax the ResourceQuota limits", ...
Again the RuleOps interface automatically generate the advisory:
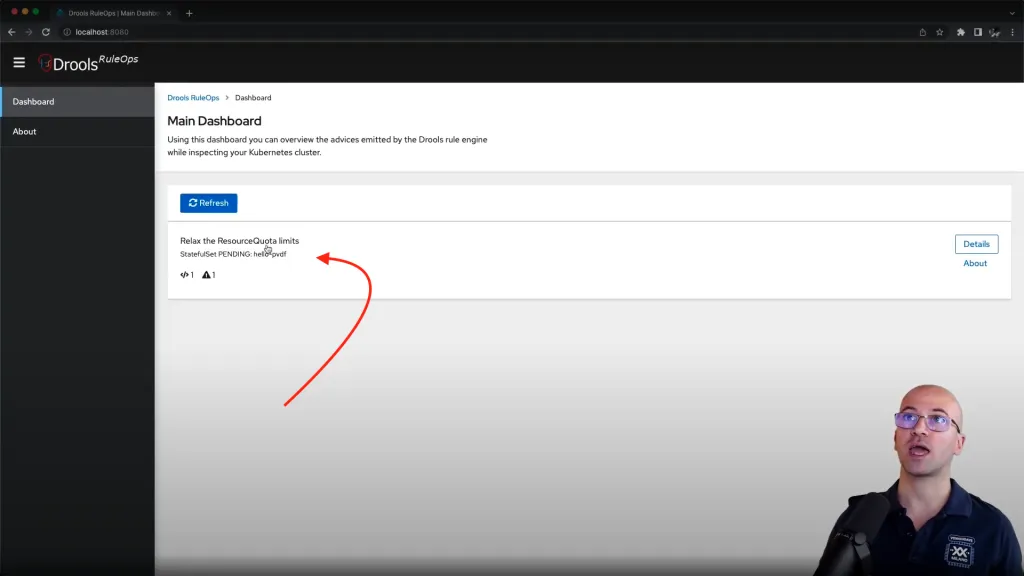
Please notice the name referenced in the advisory “hello-pvdf” is exactly the kubernetes resources we wanted to make reference to!
Demo: “Fix the PersistentVolumeClaim for Pod”
In this example we would like to make reference to another tutorial in the kubernetes documentation titled “Configure a Pod to Use a PersistentVolume for Storage”.
Drawing inspiration from that tutorial, we simulate instead the case where a Deployment is not healthy as a PersistentVolumeClaim is still pending because failing to bind on a matching persistent volume on the cluster with:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: task-pv-claim
spec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 3Gi
and
apiVersion: apps/v1
kind: Deployment
metadata:
name: pod-quota-demo
spec:
selector:
matchLabels:
purpose: quota-demo
replicas: 1
template:
metadata:
labels:
purpose: quota-demo
spec:
volumes:
- name: task-pv-storage
persistentVolumeClaim:
claimName: task-pv-claim
containers:
- name: pod-quota-demo
image: nginx
ports:
- containerPort: 80
name: "http-server"
volumeMounts:
- mountPath: "/usr/share/nginx/html"
name: task-pv-storage
Preparing this experiment on a Minikube-based lab environment, accessing the dashboard we can see the deployment is red:
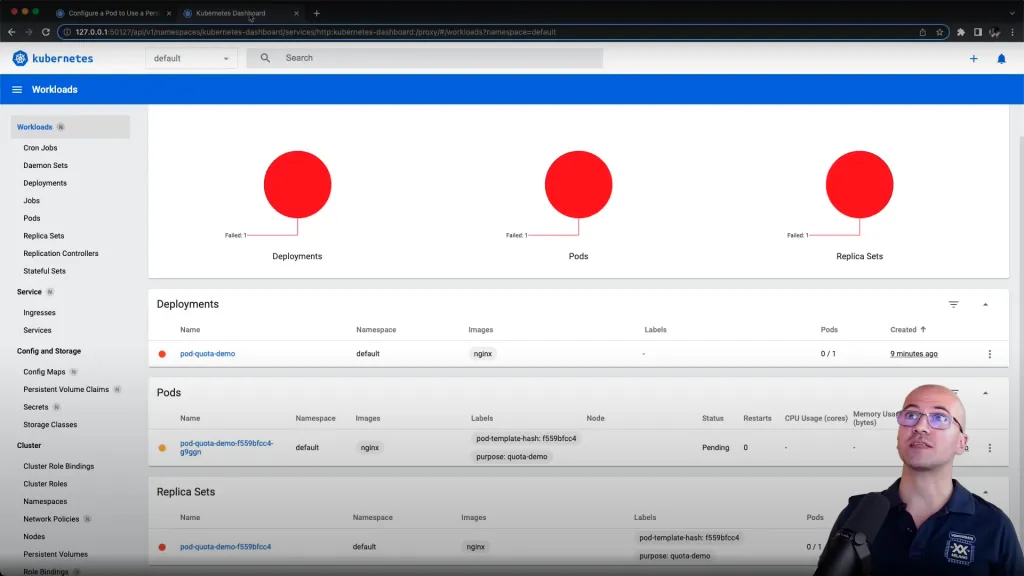
We can define a semantic rule to cover this scenario with ease:
- name: Fix the PersistentVolumeClaim Pod PENDING
when:
- given: PersistentVolumeClaim
as: $pvc
having:
- status.phase == "Pending"
- given: Pod
as: $pod
having:
- status.phase == "Pending"
- given: Volume
having:
- persistentVolumeClaim!.claimName == $pvc.metadata.name
from: $pod.spec.volumes
then: |
insert(new Advice("Fix the PersistentVolume", ...
The RuleOps interface automatically generate the relevant advisory:
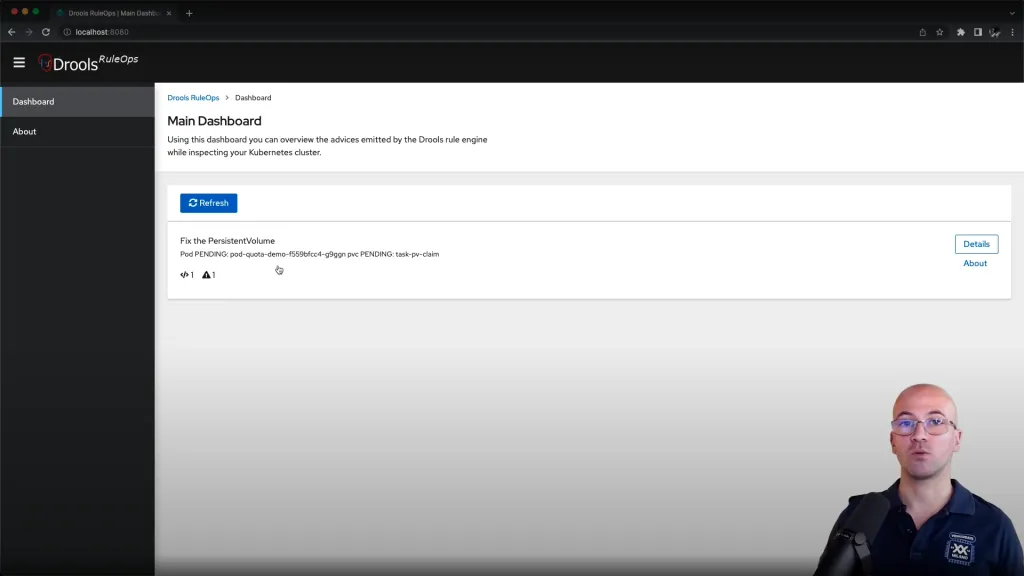
Where we are clearly instructed about the need to fix the requirement of PersistentVolume so that the indicated pvc of the indicated pod can fully deploy.
Extra: Automate it with Event Driven Ansible!
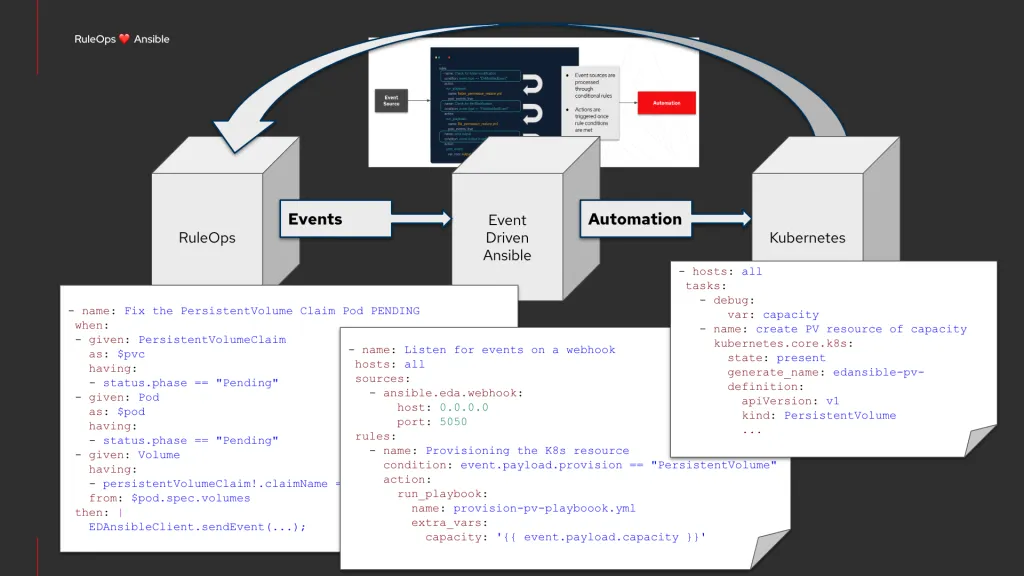
The same demo discussed in the previous chapter, can be further automated integrating it with Event Driven Ansible.
In this case, we extended the semantic rule to send a relevant event to an Ansible rulebook, which will be in charge of defining the appropriate remediating response depending on the type of events, and in the specific case of a missing PersistentVolume, we could invoke a playbook creating a new volume from a NAS and make that available to the Kubernetes cluster. In other scenarios, this integration could identify the requirements of more compute nodes, which could also be provided to the cluster with similar automation.
We have demonstrated this integration with some sample rulebook and playbook:
You can refer to this video for more details:
Demo: “Fix the Service selector: No Pod found for selector”
In this example, we’ll start from the perspective of overlooking the cluster with the dashboard:
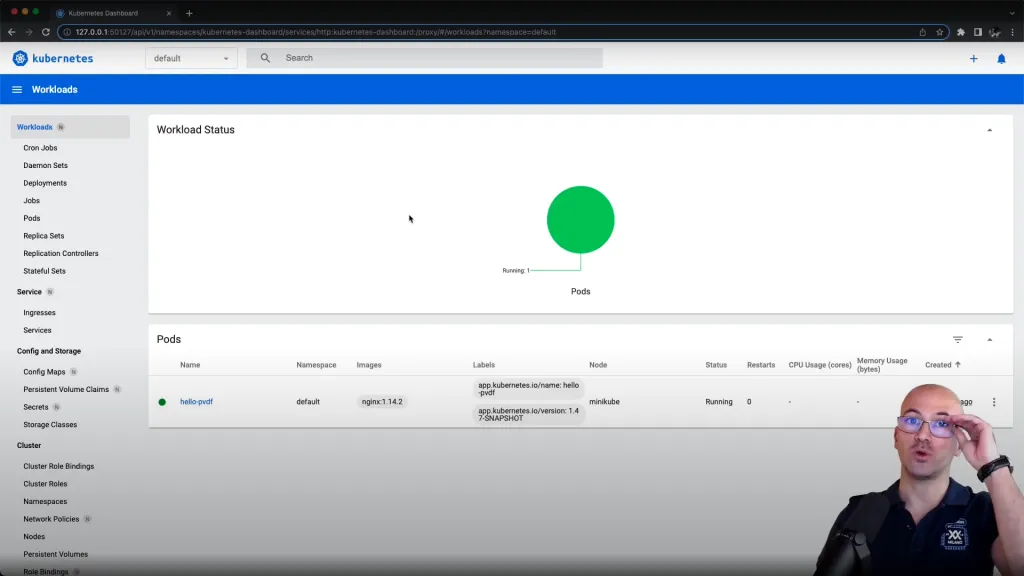
Everything seems to be working fine –all is green.
But actually from an operational perspective we would not be satisfied with the current health of the system, as we will reveal by the end of this demo.
We can showcase the command-line version of using RuleOps:
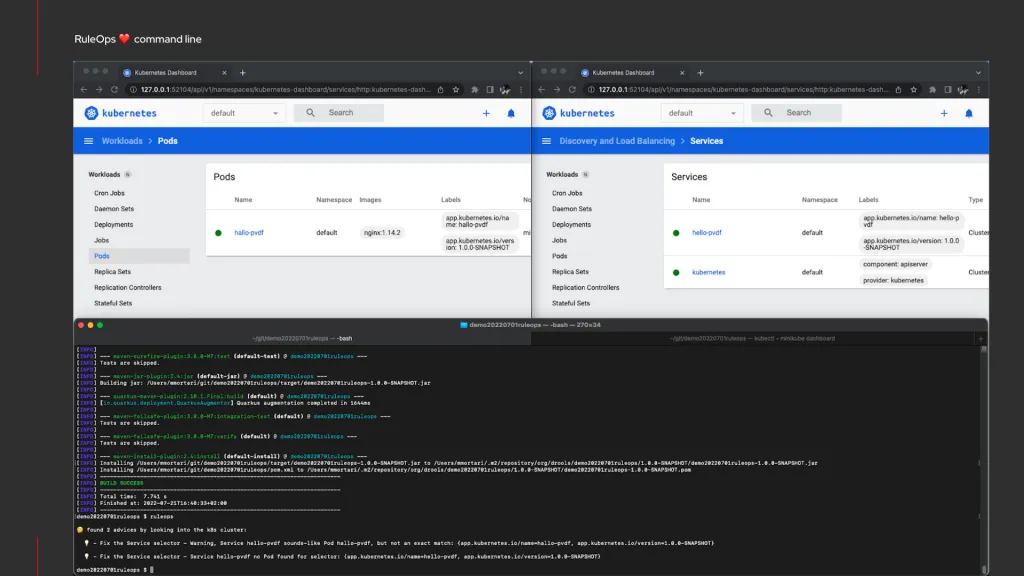
In this scenario, we are advised that the Service selector is faulty.
We believe this is of great help, because despite all dashboards looking green, the expressivity of the declarative rules allow us to capture the semantics of a healthy cluster –or a degraded cluster, as this demonstration highlighted.
In summary:
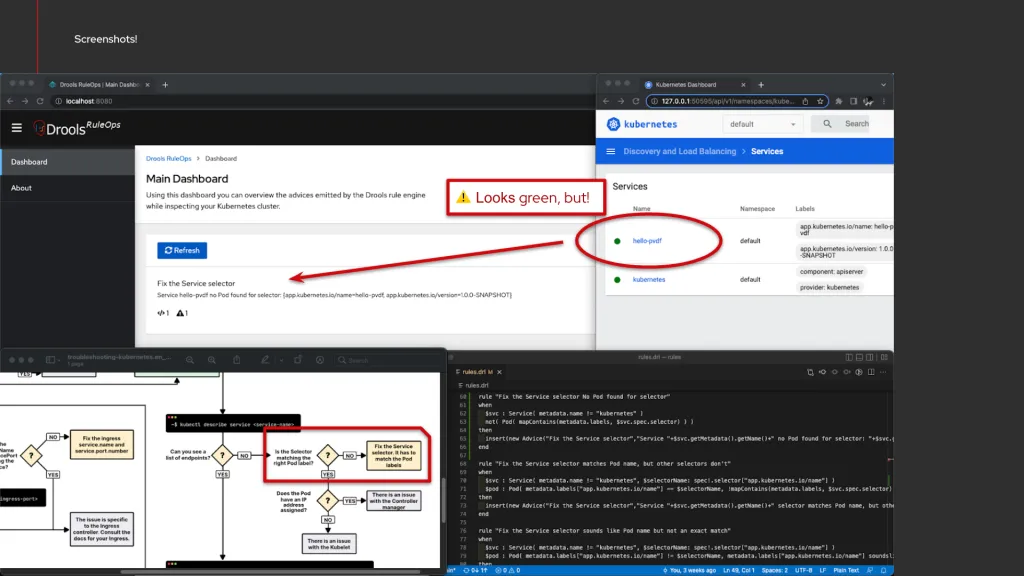
Demo: “Fix the Service selector because it sounds like another Pod name but not an exact match”
This demo is a variation of the previous one, where we would like to highlight other characteristics of the expressive power of the semantic rules, in order to catch name similarities which may produce inconsistent or degraded state of the cluster.
Such rules could easily be expressed as, for example:
- name: Fix the Service selector sounds like Pod name but not an exact match
when:
- given: Service
as: $svc
having:
- metadata.name != "kubernetes"
- '$selectorName: spec!.selector["app.kubernetes.io/name"]'
- given: Pod
as: $pod
having:
- 'metadata.labels["app.kubernetes.io/name"] != $selectorName'
- 'metadata.labels["app.kubernetes.io/name"] soundslike $selectorName'
then: |
insert(new Advice("Service selector hint", ...
In order to detect those anomalies with an increased level of nuances:
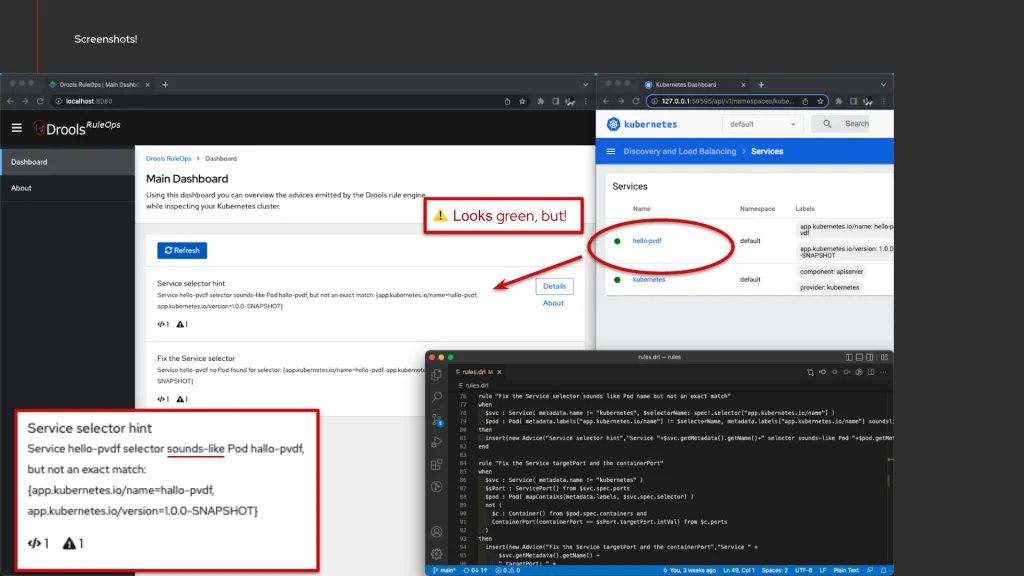
Demo: “Fix the Service targetPort and the containerPort”
In this example we want to highlight the expressive power of the semantic rule making use of existential operators:
- name: Fix the Service targetPort and the containerPort
when:
- given: Service
as: $svc
having:
- metadata.name != "kubernetes"
- given: ServicePort
as: $sPort
from: $svc.spec.ports
- given: Pod
as: $pod
having:
- 'mapContains(metadata.labels, $svc.spec.selector)'
- not:
- all:
- given: Container
as: $c
from: $pod.spec.containers
- given: ContainerPort
having:
- containerPort == $sPort.targetPort.intVal
from: $c.ports
then: 'insert(new Advice("Fix the Service targetPort and the containerPort", ...
In order to detect mismatch between the definition in a service and its related pod:
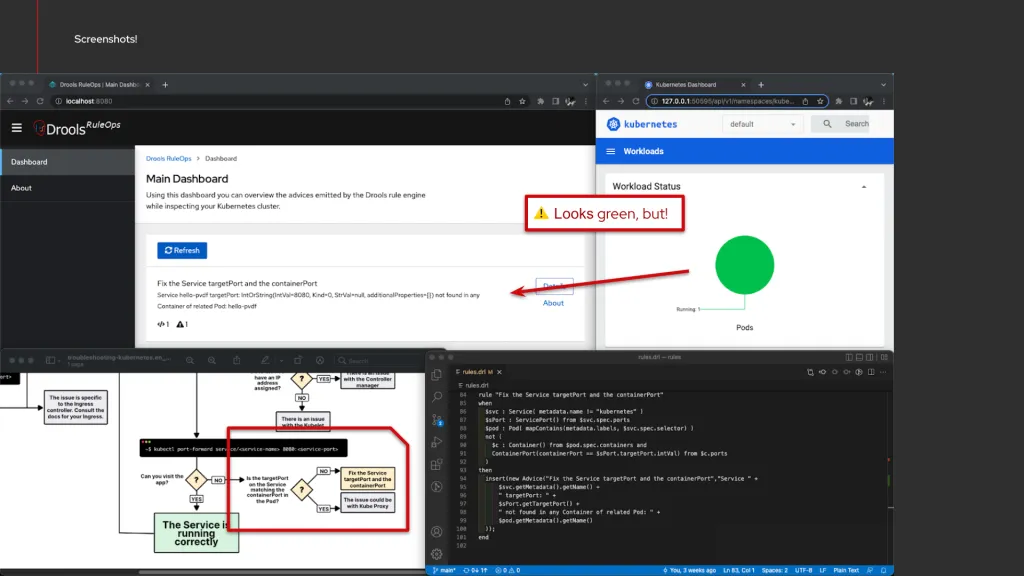
It is to be noted how making use of existential operators in semantic rules make it very easy to express declaratively these types of checks, with a relatively lower effort if compared to coding the same manually by hand using an imperative-style programming language.
Conclusions (for today!)
We have introduced RuleOps, a concept and a very powerful instrument based on symbol AI, to help with debugging Kubernetes operations. We have demonstrated with some entry-level but also pragmatic use-cases how RuleOps supports the DevOps practitioners while developing and deploying their application on Kubernetes. We believe RuleOps is valuable research exploration and a very helpful instrument you can start to use today, in your day-to-day management of Kubernetes cluster and cloud-native applications!
The post Simplify Kubernetes debugging with declarative logic appeared first on KIE Community.