Service Mesh Meets BPM
Blog: Collaborative Planning & Social Business
We demonstrated a service mesh architecture approach for BPM and Case Management in order to show that the Fujitsu DXP product could scale to any size and performance desired. First we started 12 million running process instances, and then we simulated 3000 users hitting those server, and while that was going on, showed that a work list could be retrieved — for any of the 3000 users — in less than 2 seconds. How did we do this? Read on.
What is a Service Mesh?
An important customer was concerned about the ability to scale to very large applications. It is an unavoidable fact that a single server will at some point hit a hard limit on how many requests it can handle per second. While servers continue to get incrementally more powerful every year, there is ultimately a hard limit on the total data bandwidth that a server can provide.
The way around this is to break the single server into a number of servers. This is the same approach that the big SaaS providers like Google and Facebook use to scale their ability to handle requests. The programming and implementation approach has been called MapReduce for many years, but now with the advent of containerization the term Service Mesh is becoming popular. It implies that not only do you have a set of servers (a.k.a. micro services) handling requests, but that can have multiple layers of small services each multiply connected to services at the next layer.
Isn’t this a Cluster?
A cluster is another way of providing parallel processing capability to handle high request loads and Fujitsu DXP has supported cluster deployment since 2002. The standard symmetric cluster falls prey to a problem: if each server is set up such that any server can any request it means that each server has to be kept up to date on what each of the other servers is doing. This implies some significant overhead in synchronizing. Since each server must access all of the production data, you still run into data size limits as well as unavoidable performance limits from handling very large indices.
To use the mesh approach for extreme scalability, we wanted to partition data. With ten servers, each server handles only one tenth of the data, thereby increasing the speed of all the servers. Unlike a cluster where your client request is handled by one of the servers, with the mesh approach the client request is routed to all of the servers simultaneously. Each server handles a fraction of the request, and the results are consolidated by the client.
Does it Really Scale?
For a cluster, each server still gets more and more bogged down with the increasing size of data. This means that the number of servers needed increases exponentially as the full production data set increases.
But for the partitioned mesh approach, as your data set increases in size, you simply add more servers. As you do so, each server remains handling a fixed amount of data, so performance never degrades as the full production data set increases. The number of servers needed increases linearly with respect to the amount of data. The overhead for making multiple requests and consolidating the results is tiny compared to the processing time on the server, so in practice 10x to 100x scalability can be achieved without complicated programming.
Can Process Data be Partitioned?
The approach relies on being able to break the data into sets that operate independently. It turns out that BPM and case management are manifestly appropriate for this kind of scaling. The business process is built around “process relevant data” which is all the data that is needed collected together in one place. Therefor each process instance runs virtually independent of all the other process instances. What we can then do, is simply partition all of the process instances into ten shards, put each shard on one BPM server which runs independently of all other servers.
The only place where data needs to be consolidated across multiple servers is the work list and process lists. When a given worker is looking for a task to do, the client needs to query all of the servers in parallel, but once the user chooses a particular process instance to work on, the interaction with that server is exactly as it always has been without any additional complexity.

10x Scalability Demonstration
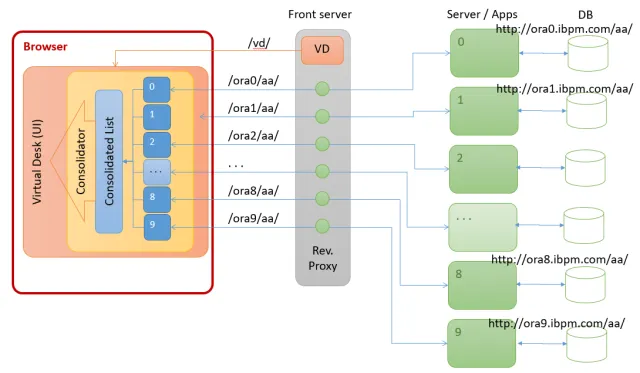
The customer was using Oracle, so we started by provisioning 10 Oracle databases from the Oracle cloud. We then provisioned 10 computer servers, also from the Oracle cloud, and installed a copy of the Fujitsu DXP software on each. This gave us 10 running DXP server without any modification to the software. We set up an 11th server, the Front Server, to act as a reverse proxy to the other ten so that all the data appeared to be coming from one server, and thereby avoid JavaScript cross site scripting limitations.
We ran some scripts to load the DXP servers with 1.2 million running process instances each, to make 12 million running process instances in total. Each process we used assigns each task to 4 users, so we had 48 million work items total.
The only software modification we had to make to the DXP standard client was to have it make 10 calls when retrieving a work list or process list, and to consolidate those results in the client. The interface to DXP is completely JSON REST API calls, and so making 10 identical calls, and consolidating the JSON results was a modification that took less than 100 lines of java script. Not really a big change, but that is all that was necessary to enable the mesh approach.
We then can 10 copies of a standard load testing software. Each copy simulated the load of 300 users working on process instances spread across all of the servers, to give us a total load simulating 3000 users constantly hitting the servers.
Success
While the 3000 users load was applied, we pointed a browser to the system, and fetched the top 1000 work items (100 from each server). By retrieving the top 100 from each server, you are guaranteed to get the top 100 work items across the whole system no matter how you are sorting them. The work list was retrieved in 1.5 to 1.8 seconds. More than 99% of all the work list requests done by the automated load software was retrieved in less than 3 seconds.
My only misgiving is that we could have demonstrated much more. When the results came in, I realized we could have easily doubled it, supporting 25 million processes and 100 million work items in the same server configuration, but it was too late to set up all the data again.
We are comfortable running 1.2 million processes on a single server, but what we demonstrated is that we can scale easily to 10x that size with no degradation in performance. Because there is no interaction between the servers, adding servers does not slow down the existing servers in any way. We were able to demonstrate linear scalability to any size load. What is best, we have already done the hard system implementation so that you get this all for free if you implement on the Fujitsu DXP platform.
If you would like to know more please contact [email protected] and we can send you a document outlining the details of how you can achieve this with your own applications.
Acknowledgement
We would like to thank the excellent Oracle support team for helping us to figure out the Oracle Cloud configuration options. We originally planned to run the compute servers on a different, unnamed cloud, however we ended up running everything in the Oracle cloud because we found the performance to be a small bit better.
It is interesting to note that the servers were spread across two data centers. The mesh approach allows the servers to be distributed such that even if an entire data center was to go down, the rest of the server mesh would continue to run with that fraction of the data.