
Saga pattern with processes and Kogito – Part 1
Blog: Drools & jBPM Blog
What is a SAGA?
Saga is a design pattern to manage data consistency across participants in distributed transaction scenarios.
NOTE: In a microservice world, a participant could be defined as a microservice, responsible to perform actions related to its business domain.
In summary, Saga is meant to provide transaction management using a sequence of steps that could be also called local transactions. In this way, each action performed by a participant is a local transaction.
While executing a transaction, failures might happen, in this situation, a sequence of compensating actions (or local transactions) are executed to undo the changes that were made during the execution, or to leave the system in a known termination state, aiming for consistency.
With that said, Saga is not a solution for strong consistency like the Two-Phase Commit (2PC), but it is more about eventual consistency, which means at some point in time the system will reach a consistent state.
The concept of Saga is not new; the initial idea was published in this paper in ’87, by Hector Garcaa-Molrna and Kenneth Salem. Besides, the topic has been discussed a lot in the community, mainly after the popularization of microservices architecture.
Ok, that is fine, but let’s take an example to see how it works in practice, things are always easier with a concrete example.
The Order fulfillment example
This is a very common use case, present in many companies and for sure it should be familiar to you.
The basic idea in this scenario is a user buys some item through an e-commerce application inputting the payment method and delivery information and waits for this item to be delivered at the specified address.
So given this use case, what in general happens behind the scenes is a sequence of steps that should be executed to complete the order, as shown in the picture:

In the example there are mainly the following steps:
- Order checkout: the user confirms the order with the chosen items, payment method, and delivery address.
- Stock reservation: where this item from the order is selected from the stock and reserved, being removed from the total stock item.
- Payment processing: based on the payment method and the user information, for instance, the credit card, the credit is checked and allocated to that payment.
- Shipping schedule: it represents a scheduling mechanism that could communicate with third-party companies responsible to deliver orders or even an internal system responsible for logistics and delivery.
Based on described steps, let’s see how a simple microservice architecture could be used to implement this example:
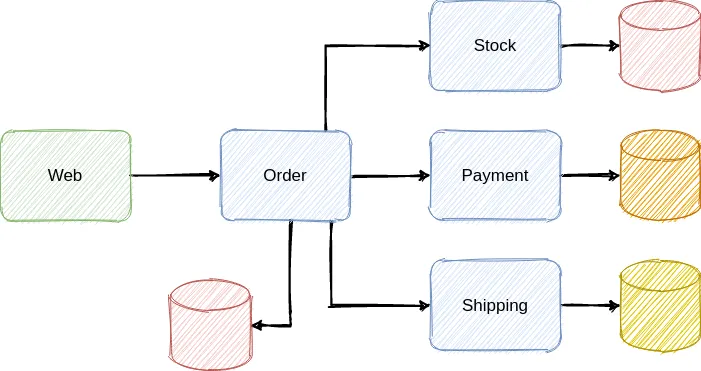
This architecture is composed mainly of 4 microservices, each one of them is responsible for a specific business domain.
Order: the entry point for the communication with a frontend application where the user does the checkout and besides it is the service that controls the order and all the lifecycle of an order.
Stock: this service is responsible to keep track and control the item’s stock, reserving or releasing items from the stock.
Payment: this service has a well-defined role, to process the payment for an order, it could even handle communication with different credit card providers, for example.
Shipping: control the order delivery and the delivery scheduling and similar to the payment service, it could communicate with third-party providers.
Let’s abstract the communication technology used by them, it could be through REST, Messaging with Kafka, gRPC, etc. But this is not important for now, the most important thing is to identify that each microservice is responsible for a domain and they are performing actions (local transactions) to the respective domain they own.
Now that we have an understating of the problem, let’s see how Saga could be used to implement it in a very quick way.
In the below picture, it is possible to visualize the two main flows during the order fulfillment process.
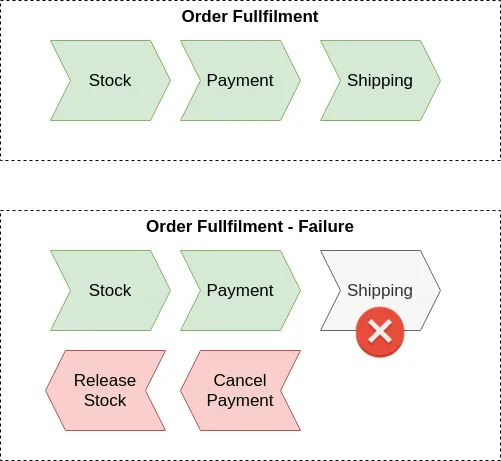
In the first case, the happy path, the stock is reserved, after that, the payment is successfully processed and finally, the shipping is scheduled and done for that order.
The second case describes an example where a failure or any error is thrown during the shipping process for an order, and in this situation, a sequence of compensation actions are executed, to cancel the payment and to release the stock for the items in the given order.
In general, there are two approaches to address this kind of problem. Choreography and Orchestration.
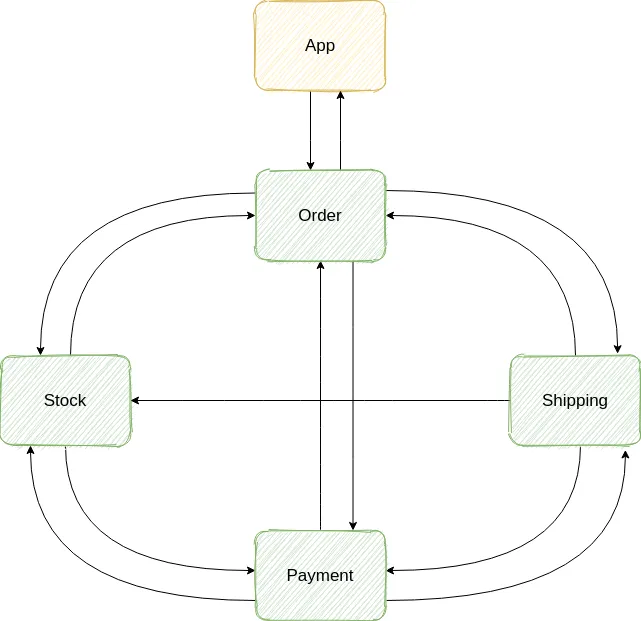
Choreography requires each participant to react to an event, or to something that has happened in the system, thus each participant should be aware of things or events that might happen to other participants. There is no central point where the business logic is defined; it is spread in all the participants which give more flexibility.
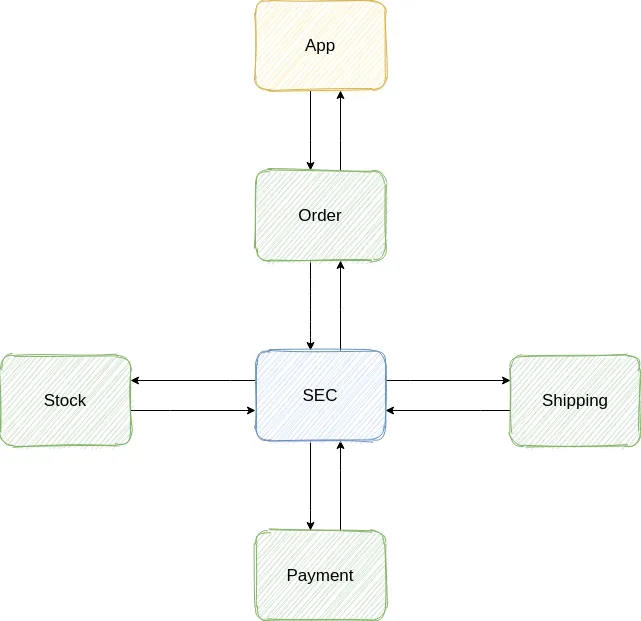
Orchestration centralizes complexity and the business logic into a single entity, also called Saga Execution Coordinator (SEC) which is the component that orchestrates calls to the participants, thus services should only be aware of their own domain events. This makes things easier to monitor, evolve and change over time, but introduces a potential single point of failure.
In the article, What do you mean by “Event-Driven”?, from Martin Fowler, there is this interesting part:
"The danger is that it’s very easy to make nicely decoupled systems with event notification, without realizing that you’re losing sight of that larger-scale flow, and thus set yourself up for trouble in future years".
In some situations, a choreography approach that is all event-driven, which might contain a huge number of steps, and many microservices interacting with each other things could become very complex to maintain. The orchestration could be very useful to decrease complexity. It provides and an easier way to have control regarding what is going on in the whole system, what is being executed, and even to detect potential errors that might impact the business.
With a centralized workflow, it is easier to evolve the architecture, adding or removing steps and microservices.
Considerations about Sagas and orchestration approach
- Stateful: keep track of each executed step in a persistent way
- Saga workflow declaration, is way to declare the workflow, all the steps and compensations
- Each action, or step, might have a correspondent compensation for it
- Actions must be idempotent, this means to be executed multiple times with no impact, which allows fault tolerance and retries. This is important mainly considering the remote communication among the participants
Kogito as a Saga orchestrator
Kogito process runtime allows the execution of workflows in a lightweight and cloud-native way, this is a great fit to implement a Saga Coordinator Executor (SEC) because a Saga can be modeled as a process, where we can define a sequence of steps and compensations for each step, besides all the decisions and logic control we have with processes. Error handling is another useful feature when designing Saga as a process, more information was published in this post.
Leveraging Kogito capabilities it is possible to achieve a scalable stateful workflow control, with different pluggable persistence mechanisms that control the executions and the compensations that might be executed in case of a failure or an unexpected in a given step of the workflow.
Timer events are another important feature to control async communication, for instance when a message is sent in a process and it waits for another message to come, timers can be used as a timeout control in this situation. This is not a simple in-memory control like in a timeout for an HTTP request, this is a stateful control with wait states to not block the process runtime. This feature makes use of the Job Service, which is a microservice responsible for controlling timers in Kogito.
Kogito includes supporting services like Data-Index and Management Console that provide out-of-the-box monitoring capabilities that are useful to check the Saga execution in a UI and expose query APIs in case some integration is needed.
There are different ways to declare a workflow in kogito, for example, BPMN2 or Serverless Workflow, and they are easily integrated with Decisions, either DMN and DRLs that could be very helpful to evaluate data and choose a path to be executed in a Saga.
To be continued…
In the next blog post, it will be covered a concrete example implemented with processes and Kogito to declare and run the order fulfillment Saga, where kogito will play the orchestrator role.
The post Saga pattern with processes and Kogito – Part 1 appeared first on KIE Community.