
Roaming through contexts with Roam: How I use it
Blog: Strategic Structures
This is the last, 5th instalment on Roam. Here I’ll share how I use it. This part will be easier to write than some of the previous ones. What won’t be easy is to keep it short.
Here are the links to the previous post in the series: Part 1: what is it, Part 2: Distinction, Part 3:Self-reference, and Part 4: Organization.
Migrating from Evernote to Roam felt like going forward and backwards at the same time. Before Everone, I used Zim, which had the capability to create a new note from within a note and backlinks1. That’s why it felt like going backwards. And it felt also like a big leap forward because Roam changed the game not only on note-taking but on personal knowledge management in general.
The main difference is that conceptually Roam treats the data as a graph. I’m not referring to the graph view showing graphically how pages are linked by references. This view shows only a small part of the graph, hiding the main element, the block. Blocks in Roam a basically paragraphs and other units of content with unique identifiers. Blocks are not something RoamResearch came up with. Many contents management tools, for example, WordPress, refer to content components as blocks. But Roam pushed that idea a few steps further by allowing blocks to quickly be nested, referred to, embedded, created from a piece of text in a block, appear in the sidebar, being searched and queried and so on. Block capabilities can be extended and it has been, beyond what I thought was possible. Yet, for me, the most important thing is that blocks, along with the special kind of block called “page”, are the nodes of my graph.
Ontology
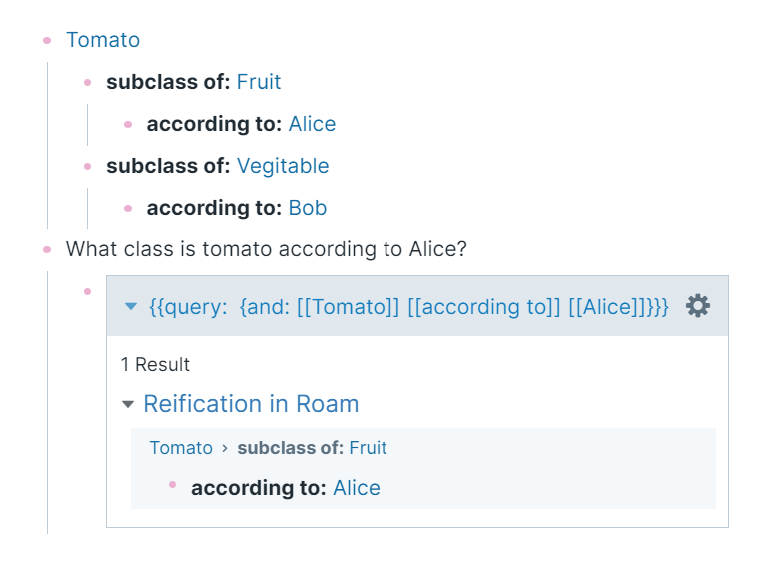
To get the most of my graph, I follow certain conventions and practices. As I explained in detail in Part 2, creating a page reference is making a distinction. It is followed by further distinctions. For example, I may create a reference to a named entity such as Paris, Athens, and Alice. In the context of a block, I know if I mean Paris the city, or Paris the street, or Paris the square, or Paris the cafe. I also know if I mean Athens the city or Athens Research, the open-source tool, inspired by Roam. I know that Alice is a person, and I know that I meant Paris the city, and Athens the tool but I want to let my graph know that as well. To query my graph, just like when querying Wikidata or DBpedia, it becomes very important to know the type of a thing. That’s one of the reasons to have a knowledge model, an ontology. In the example above in the page of Alice, I make a statement [is a::] [[Person]], where [is a::] and [[Person]] are defined in my ontology, [is a::] as a [[Property]] and [[Person]] as a [[Class]], using again the typing relationship [is a::]. This way [[Alice]] [is a::] [[Person]], [[is a]] [is a::] [[Property]], [[Person]] [is a::] [[Class]], and also [[Property]] [is a::] [[Class]].
Roam is very flexible. That’s great by it come with a price: when the graph grows it may become unmanageable. On the other hand, applying a fixed schema would be very restrictive. That’s why, to find the balance, I decided to use an ontology but an emergent one. What I do is look for patterns in the way I use Roam and then decide which of them I want to establish as conventions to follow. I call this emergent ontology RIO. It stands for “Roam Internal Ontology”. Since Roam cannot reuse external ontologies such as schema.org or Dublin core, I can at least maintain an internal one, to get better organization and retrieval.
If RIO gives semantics to my knowledge graph, who will give semantics to RIO? For that, I defined another ontology, ROCO. ROCO stands for ROam COre ontology. ROCO gives explicit semantics to RIO, which in turn gives explicit semantics to the rest of my knowledge graph. ROCO, imitating terms of RDFS, OWL, and SKOS, defines the classes of Property and Class, and properties such as [is a:], [same as::], [subClassOf::], [subPropertyOf::], [described by::] and a few others. It’s a small ontology with fewer than twenty terms and I don’t expect it to grow much. The property for typing, [is a::], as expected, is used a lot, both in RIO and in the rest of the graph. The property [same as::] is used even more because it doesn’t only bring equivalence between properties and entities within my graph but also links to external graphs. I’ll come back to this later.
So, here are a few of my conventions:
Class labels start with a capital letter, for example, Person, Meeting, Paper, Article, Issue, Bug, Tool, Organization, Question, Answer, Highlight and so on. The only exceptions are the subclasses of Action: toShare, toPlan, toWatch, toRead, toTest and so on. That’s a special kind of class. (More on them later.)
I classify most of the named entities (pages) and many of the content chunks (blocks). For named entities, I do it directly on the page with the property as the root block, so that the subject of the statement is the page. So on the page of [[Alice]], there will be a root block [is a:] [[Person]].
When classes content chunks, they are used directly in the block with # format. For example:
- The range axiom will limit the reuse of this property #Issue
This is the same as stating “The range axiom will limit the reuse of this property” [is a:] #Issue. In other words, this block is an instance of the class [[Issue]]. And, as said earlier, the fact that [[Issue]] is a class is stated on the Issue page with [is a::] [[Class]], along with the declaration that it is defined by RIO. There are classes and properties not defined in RIO or ROCO. These are created by linking the graph to external graphs such as Wikidata.
Property labels start with a small letter. Those defined by RIO and ROCO have labels formed in a way that statements can be read as close as possible to natural language. This gives the extra benefit that the queries also look close to the natural language. Here’s a query to list all classes:
Tags are with small letters, which is a way to visually distinguish them from classes. Of course, in Roam terms both are pages. But through different classification and conventions, I make this distinction. Tags (categories, topics, keywords) can be about the same thing which exists as a class such as [[Person]] or [[Organization]]. For example, [[Niklas Luhmann]] is a [[Person]], while #luhmann is a tag. All linked references of [[Niklas Luhmann]] will be blocks that are instances of books, papers or quotes of Niklas Luhmann, while #luhmann will filter articles, papers, ideas, thoughts etc associated or referring to Niklas Luhmann. I established this practice long before I started using Roam and I still find it useful.
Speaking of quotes, [[Quote]] is an equivalent class to ‘>’. This way I don’t have to type quotes with Quote, just use [[ >]] instead of ‘>’, which will produce the same block-quote rendition.
Unfortunately in Roam, relationships are not first-class citizens. There are 36 predefined ones, called “attributes” but the user cannot define new ones or sub-properties. For example, there is an attribute [:block/children] so it would’ve been great to define sub-properties such as [:hasInstance], [:hasPart] and so on, to distinguish different types of relationships, created through the indentation feature.
What is left to the user are so-called Roam attributes, a block string ending with ::. They have three important qualities. One is that the :: specifies a direction, so when used as a child of a block or a page, it works as a triple, with the parent being the subject, the attribute being the predicate and whatever is after ::, in the same or in a child block, is the object2. When the value is a page reference or a block, this predicate works as a user-defined labelled edge between the two nodes. But I’ll keep using property or relationship, to avoid confusion.
The second quality is that attributes are entities, pages, in Roam terms. As such they are nodes in the graph and can have relationships between them.
The third quality is that they work like relationship types. The relationship type ID is the respective page ID and the instance ID is the block containing a property.
This last quality allows the make statements about statements directly3.

At the time of writing, RIO has 153 classes and 45 properties.

In some cases the application of classes and properties is manual, but in many cases it’s automatic, using templates, smart blocks and configuring imports. Some of them, for example, the configuration of Reawise, is explained later in this post.
Earlier this year, at a Knowledge Graph Conference workshop on Personal Knowledge Graph, I talked about this ontology and practice and made a small demo.
Once I find time to review the ontology, I’m going to share it so that others can give it try.
Daily
I don’t use templates or smart blocks for daily notes pages. When templates are used for daily note pages (DNPs), they tend to unify them. I prefer that every day is different. Yet, I have established some routines. On weekdays, I trigger the command for Google calendar import, courtesy of the respective RoamJS extension. It is configured so that the blocks created are already made as instances of [[Event]]. I reorder my tasks. Sometimes I split the day to AM and PM. I may also group tasks by category and almost always I group them by the project. Of course, many project tasks are pulled from their Kanban boards as references.
When I finish a couple of tasks or meetings, I create a horizontal line and send the finished block to the bottom of the page to keep them out of the way. As I do this many times a day, it is automated with a Roam 42 workbench inbox. I called it “.Bottom of page”, so that when I press Ctrl+; it appears on top. Often I select and send several blocks at once. When the tasks are too many or verbose, I may indent them below the horizontal line block, so that I can collapse the line block to hide them.
Some tasks in my DNPs come from email and Telegram, through Phone2Roam.
Apart from tasks and events, another type of block in my DNPs are blocks for learning stuff. Here, I’m also quite lean, I use the built-in spaced repetition with Δ. There is a great SR extension but it has way more features than I need.
A small detail: I tag the learning topics with a dot in front so that they are not visible unless I roll over.
Often I send blocks of my DNPs to the weekly notes page or to another day. When the destination page is open on the sidebar, I do it manually. Otherwise, I use 42 workbench command to move the block to another day, often leaving a reference for reporting or other purposes.
Tasks
My tasks either {{[[TODO]]}} items or instances of Kanban board classes (yes, RIO again), such as [[BACKLOG]], [[TODO]], [[DOING]], and [[DONE]]. For those classified as action items, I use David’s to-do trigger extension, for automatic change of state (class), based on the {{[[TODO]]}} state.
(table)
(diagram, more explanations)
Projects
When it comes to projects, one of the many things that set Roam and Roam-like tools apart is that they can be used not only for managing but also for doing and presenting the work. Having these three aspects integrated into one knowledge graph gives enormous benefits4.
My projects pages start with a typing statement, [is a:], followed by blocks collecting reference links, main deliveries and milestones, Kanban board and logs. Often I keep in the Kanban only three of the columns, TODO, DOING and DONE, and the blocks with BACKLOG and ONHOLD I put respectively before and after the board, on the same block level. As the DONE column tends to become the longest, I keep it short by having an ARCHIVE group.
There is a lot more than can be said but I’ll stop here for now. Here’s a recording of my recent talk on using knowledge graphs for managing projects. Most of it is coming from my practice of using Roam and Roam-like tools.
The slides are available here. See the section Presentation below for more information about presentations.
Research
For research, I rely on PDF Highlighter and the Sidebar extensions, as well as integrations such as Readwise and Hypothesis.
Research is one of the key use cases for Roam. It’s in the name. But there is nothing special worth sharing, with the exception of the use of RIO.
Maybe a few words about the sidebar. The need to have many facets of the graph open at the same time leads to heavy use of the sidebar. Although the standard filtering, pinning and reordering are incredibly useful, when the nodes open on the side are too many, they are difficult to manage. The RoamJS sidebar extension comes in handy here. It enables expanding and collapsing of all open outlines and references and what’s more, you can save the sidebar configuration and restore it when you resume your work. I use that a lot.
Writing
When writing a longer piece, it’s very important for me to see only the text. It’s not just a focus aid but an aesthetic preference. I was able to achieve that in Roam thanks to Jeff Haris. The focus-mode CSS works at block-level, triggered by a hidden tag. Sometimes I bring back the side-bar, but when not, my workspace looks like this:

Regarding writing a book, I don’t have much to report. I used Roam during the last stages of the work on my book, but that was more on supporting editing, publication and marketing, than the core creative process. I’m looking forward to using Roam or a similar tool for my next writing project. I’ve already experienced what it is to have writing, research, relationships and project management integrated for smaller works, and I can only imagine what it would be for bigger and more complicated ones.
Presentations
In the last year, I made 37 presentations, 35 with Roam and 2 with PowerPoint. I find making a presentation from the graph so valuable, that I have funded some of the capabilities of the Presentation extension. There are limitations, compared with PowerPoint and GoogleSlides, but for me, that’s a small price to pay for the benefits. Some of my Roam presentations I have shared in my public Roam graph.
Training courses
Along with my consulting practice, I design a deliver workshops and training courses. The most popular one is on knowledge graphs and semantic technologies. I often give up to two courses a month. They moved online soon after I started using Roam and so all my online courses have been heavily supported by the tool. This includes references, planning, preparation, checklists, participants, notes, Q&A, exercises, managing code snippets, feedback, and courses improvement workflow. There I utilise templates a lot, from the day they were launched. Now I’m considering using smart blocks.
Mobile
Roam still doesn’t have a native mobile app but it can be installed as an app. In spite of all inconveniences, I tend to use it a lot. Mostly with share to, from other apps, then with quick capture but also directly, often enough to have it in the tray.
When sending to Roam from Telegram, eMail or Calendar, it’s difficult to create tasks with all those brackets, not readily accessible from the keyboard. To deal with that, I have a clipboard shortcut, so that by typing [td], I can insert the whole {{[[TODO]]}} . Apart from TODO, I have shortcuts for frequently used page references from mobile, and for “[[” and “]]”. Of course, they are mostly useful outside the app when the lookup function is not available.
Integrations
Here is a map of my current information flows involving external applications.
![]()
There are highlights, messages, tweets and facts, created by me or by others, which I need to find, refer to, link, recall, and include in other workflows.
Highlights
For highlights from the web, I initially used only the Roam Highlighter extension, which works also for Kindle highlights. But doesn’t write directly in Roam, so I have to manually paste the highlights. That’s one of the reasons I moved to Hypothesis and Readwise. I still use Roam Highlighter a lot for web highlights, in cases I need them right away and in a specific place.
Currently, Kindle highlights, web and PDF highlights made with Hypothes.is, as well as those from Medium and Pocket, are brought to my Roam graph by Readwise. The configuration I use applies automatically RIO properties such as [by:] and [is a::], and classes such as [[Book]] and [[Article]].
is a:: {% if category == "books" %}Book{% elif category == "articles" %}Article{% elif category == "tweets" %}Tweet{% elif category == "podcasts" %}Podcast
{% endif %}
by:: {{author}}
{% if document_tags %}has topic:: {% for tag in document_tags %}#{{tag}} {% endfor %} {% endif %}
{% if url %}URL:: {{url}} {% endif %}
{% if image_url %}<img src="{{image_url}}" alt="" /> {% endif %}
For highlights, I have configured Readwise to add the highlights ID in a way that they work as hyperlinks from Roam so I can quickly check where it came from.
I prefer reading on e-ink devices, so my Pocket articles are automatically sent to my kindle via P2K. The downside is that this way I’m not able to use the Pocket-Readwise integration for the majority of my article highlights directly and I need to upload MyClipping.txt file to Readwsie from time to time, to bring the delta in.
The other e-ink device I use for reading and highlighting, besides sketching and presenting, is reMarkable. So far I haven’t found a way to bring them to Roam. But there are ways.
Highlight from PDF documents I bring via Hypothes.is – Readwsie integration, or annotate them directly in Roam, using the PDF Highlighter extension. The latter is very powerful. It allows jumping directly from a highlight block to the highlighted area inside the PDF document.
Tweets
Initially, I used the RoamJS Twitter extension for importing tweets. Now I use it only for sending tweets; for importing liked tweets, I rely on Readwise. Since they appear in the linked references of the DNP, where I spend most of my Roam time, I can easily add notes and tags.
I often look for specific old tweets that I made, liked and retweeted and it’s not easy to find them on Twitter. Now I’m keeping a copy of my twitter bubble as a knowledge graph, where I can easily find tweets. Users and tags I ready facets of the graph. I keep the backup of my tweets in Markdown (MD), so it was very easy to directly use it with Logseq.
It wasn’t easy to import them in Roam thought. I thought would be the opposite but it turned out Roam is not able to import large MD files. I finally succeeded by splitting the file with my tweets into smaller files.
Forgot to mention that I asked my son to write a Python script to make some cleaning and transformations.
It would’ve been nice if I could import my tweets in the main graph but currently, that’s too much for Roam to handle. I have them in a separate graph.
Wikidata
For integrating my knowledge graph with open knowledge graphs, I use the SPARQL extension. It is currently best adapted to Wikidata but I use it for other knowledge graphs as well.
RIO does a great job here as well.
Messages
To send messages from email and Telegram to my Roam graph, I use Phone2Roam. That works fine for Telegram but not so much for mail as it currently does not retain formatting, and can’t handle attachments. I hope this will come in the future.
There are plenty of other things I use Roam for, including time-tracking, invoicing, managing service subscriptions, trips planning, music, and sport. This post is already quite long so it’s time to stop. But if there is an interest to elaborate on something, please let me know and I’ll be happy to respond and update the current sections or add new ones.
Leave a Comment
You must be logged in to post a comment.






