
Recent Drools DMN open source engine performance improvements
Blog: Drools & jBPM Blog
We are always looking to improve the performance of the Drools DMN open source engine. We have recently reviewed a DMN use-case where the actual input population of Input Data nodes varied to some degree; this highlighted a suboptimal behavior of the engine, which we improved in recent releases. I would like to share our findings!
Benchmark development
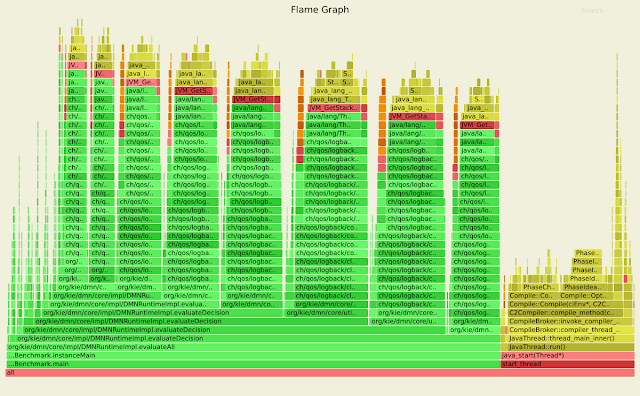
As we started running a supporting benchmark for this use-case, especially when investigating the scenario of large DMN models with sparse-populated input data nodes, we noticed some strange results: the flamegraph data highlighted a substantial performance hit when logging messages, consuming very significant time in comparison to the application logic itself.
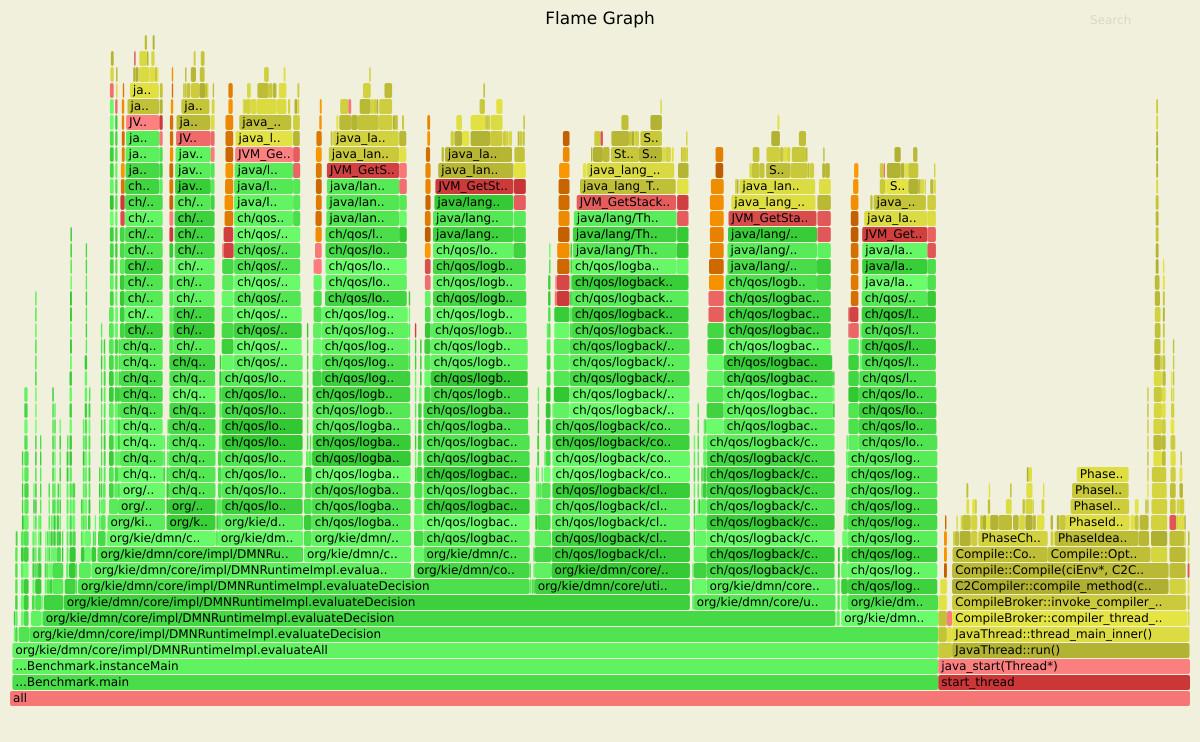
This flamegraph highlight specifically that a large portion of time is consumed by stacktrace synthesis, artificially induced by the logging framework. The correction, in this case, was to tune the logging configuration to avoid this problem; specifically, we disabled a feature of the logging framework which is very convenient during debugging activities, enabling to quickly locate the original calling class and methods: unfortunately this feature come at the expense of synthesizing stacktraces, which originally contaminated the benchmark results. Lesson learned here: always check first if non-functional requirements are actually masking the real issue!
This was a necessary and propaedeutic step, before proceeding to investigate the use-case in more details.
Improving performance
Moving on and focusing now on DMN optimizations, we specifically developed a benchmark to be general enough, but also highlighting the use-case which was presented to us. This benchmark consists of a DMN model with many (500) decision nodes to be evaluated. Another parameter controls sparseness of input data nodes valorization for evaluation; ranging from a value of 1 where all inputs are populated, to 2 where only one out of two inputs is actually populated, etc.
This specific benchmark proved to be a very instrumental tool to highlight some potential improvements.
Setting the comparison baseline to Drools release 7.23.0.Final, the first optimization implemented with DROOLS-4204 focused on improving context handling while evaluating FEEL expressions and demonstrated to offer a ~3x improvement, while further optimization implemented with DROOLS-4266 focusing on specific case for decision table input clauses demonstrated an additional ~2x improvement on top of DROOLS-4204.
We also collected these measurements in the following graphs.
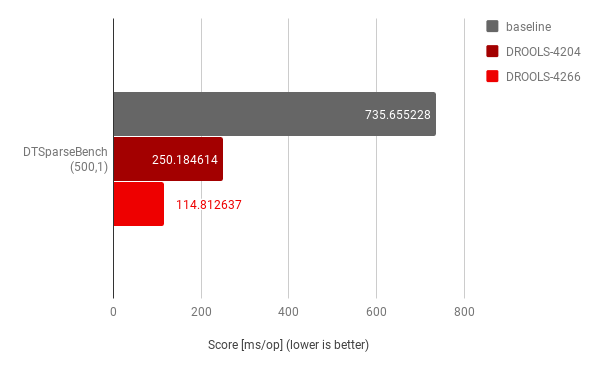
This graph highlights the compounding improvements in the case of sparseness factor equal to 1, where all inputs are populated; this was a very important result, as in fact it did represent the main, “happy path” scenario in the original use-case.
In other words, we achieved a ~6x improvement in comparison to running the same use-case on
7.23.0.Final. The lesson I learned here is to always strive for these kind of compounding improvements when possible, as they really build on top of each other, for greater results!
For completeness, we repeated the analysis with sparseness factor equals to 2 (1 every 2 inputs is actually populate) and 50 (1 every 50 inputs is actually populated) with the following measurements:
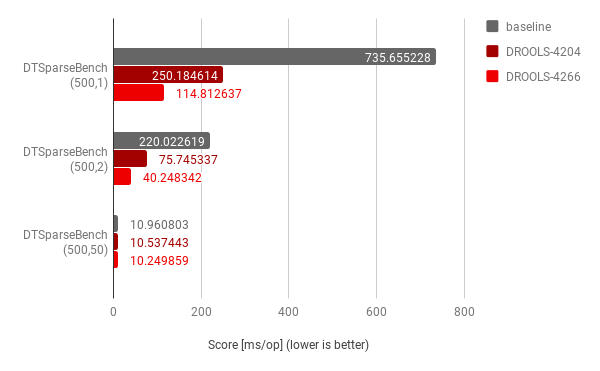
Results show that the optimizations were also significant for sparseness factor equal to 2, but not as relevant improvements as this factor grows — which is expected, as the impact of the decision nodes evaluations on the overall logic of execution become now less relevant.
For completeness, analysis was also performed with another, already existing benchmark for single decision table consisting of many rules rows:
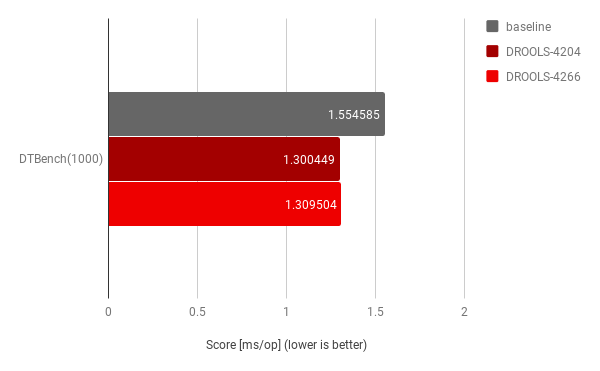
Results show that these code changes considered as a whole, still offered a relevant improvement; although clearly not of the same magnitude as for the original use-case. This was another important check to ensure that these improvements were not overfitting on the specific use-case.
Conclusions
Considering Drools release 7.23.0.Final as the baseline, and a reference benchmark consisting of a DMN model with many decision nodes to be evaluated, we implemented several optimizations that once combined demonstrated to offer a total of ~6x speed-up on that specific use case!
I hope this was an interesting post to highlight some of the dimensions were to look into to achieve better performances; let us know you thoughts and feedback.
You can already benefit today from these Kie DMN open source engine improvements in the most recent releases of Drools!
Leave a Comment
You must be logged in to post a comment.






