
Process Monitoring in the Large — The Control IT Project at T-Systems
_When a company is faced with massive amounts of process-related data, one of the first steps is often to make that data accessible in the first place. A few weeks ago, I met Marco Lotz, a project lead at T-Systems, who showed me their elaborate system to process and organize massive amounts of event log data.
Of course, I saw lot of opportunities for the application of process mining throughout our tour, but first of all, my visit showed me how valuable event log information can be when you take it seriously – whatever method you use to interpret it._
A few weeks ago, I had the opportunity to visit the Control IT project of the T-Systems in Bonn, Germany.
Project lead Marco Lotz showed me their system and what it is capable of. Read on to hear more about an impressive project implementing a process-oriented monitoring solution on a grand scale.
Background
The project started in 2005 due to the need of a Corporate Performance Monitoring solution for one of their clients. The trigger for the client back then was new, legally obligatory Service Level Agreements (SLAs) that had to be monitored. If an SLA was not complied with, then the other party could sue their client for large compensation payments.
The need to monitor process SLAs in an insanely complex environment led to the creation of a very powerful process correlation and pattern matching platform that is still maintained and further developed today.
Overall architecture
The overall architecture is nothing short of breathtaking. Messages from more than 100 different input systems are used and correlated to build up history logs for the end-to-end process over the whole system landscape. There are around 16,000 different message types and ca. 11 million messages collected and correlated per day.
The correlation happens asynchronously and using a re-offering mechanism to match process fragments from different parts of the system. Because none of the commercially available correlation technologies (through adapters and rules) were powerful enough to do the job, they had to implement their own solution. This large-scale correlation is very impressive and would be worth an article on its own.
But I found it even more interesting what they do with their neatly correlated history logs: Next to interfacing with a BI reporting system and a BAM solution, they also monitor the processes using a powerful pattern matching mechanism. I want to show you an example in more detail.
Pattern matching
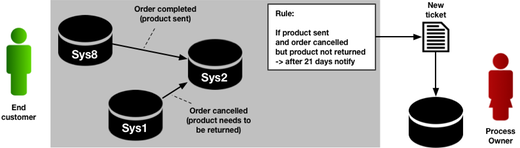
Imagine the following scenario. An end customer has ordered a product. The order was completed and the product is sent to the customer. But then the order is cancelled.

The Control IT system is monitoring the messages sent between the various systems to react in the following way: If both an order completion and a cancellation was observed (occurrence of messages) and the return of the product was not observed (non-occurrence of message) after 21 days (time constraint), then the system automatically creates a ticket for the responsible department, so that they can take over and send a reminder to the customer.
The pattern matching for such rules is achieved in multiple stages.
1. Message classification and correlation
Messages are classified as, for example: completed, cancelled, error, or rollback. Furthermore, all messages that belong to the same process instance are correlated. The result are history logs such as the following history for one of the orders in the example scenario.

Each row reflects one message that was sent for this particular order.
-
The DATE column holds the timestamp for when the message was sent.
-
The SENDER and RECEIVER columns indicate the source and the target systems of the message exchange. If the message occurred within a particular system, the RECEIVER column is blank.1
-
The VALUE reflects the message type (completed, cancelled, etc.).2
-
The CAT_ID is a unique name that identifies the combination of SENDER, RECEIVER, and VALUE for a message.
In the history log above, 37 messages have been sent in total between 10 different systems (all concerning the same end customer order).
2. Grouping of process instances
The second step is the so-called grouping of process instances, which is a categorization based on their specific process sequence pattern.
Groupings can be defined based on:
-
The occurrence of a message (positive statements)
-
The non-occurrence of a message (negative statements)
-
The position of an activity in the message sequence (first message, last message, before, after, or in between other messages)
-
The messages are specified for specific sender/receiver combinations
To make it more concrete, here is the grouping definition for the example scenario above. It consists of two parts: a Positive pattern and a Negative pattern.
The Positive pattern specifies the occurrence of first the Order completed message, and then one of two possible Order cancelled messages. The example history log above matches the positive pattern because first an Order completed message was sent from Sys8 to Sys2 (Message No 21 in yellow mark-up) and later an Order cancelled message was sent from Sys1 to Sys2 (Message No 23, see yellow mark-up).
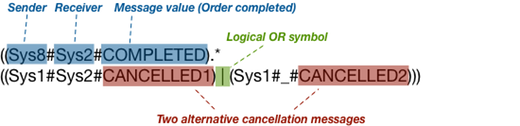
The Negative pattern is specified separately and will be interpreted in the inverse way. So, only if the positive pattern matches and the negative pattern does not match the process instance, then this instance will be matched by the grouping. According to the example scenario above, the negative pattern is that the product may not have been returned by the end customer.

Internally, the Positive and Negative patterns are transformed into regular expressions that are matched against the message sequence of each process instance.
3. Rules
As a third step, rules can be defined over sets of process instances that are determined by one or multiple groupings.
These rules can involve time-based statements, other checks, and trigger real actions in other systems. They are constructed as a sequence of operations.
For the example scenario above, the following three operations are defined based on the grouping described before:
- Check whether the cancellation message (see Message No 23 CANCELLED1 in the history log above) is older than 21 days.
If yes, then perform operation No. 2.
If no, then perform operation No. 3.
-
A new ticket is created in the system of the customer service department, which will trigger an automatic reminder that will be sent to the customer.
-
The process instance will be re-evaluated in 24 hours.
When we looked through other rules and grouping definitions, it became clear that different users (process owners defining rules for their own departments) express their rules and patterns in different ways. Some of them define the patterns with a clear status change or process model in mind: First Message X needs to occur and then Message Y, but not Message Z etc.
Process orientation
The similarities to process mining struck me throughout Marco’s presentation. Their correlated history logs allow them to ask process-oriented questions.
Marco thinks about adding further capabilities that become possible based on the current architecture. For example, what if exceptions or notifications could be defined based on the observation that a run time value for a certain process type is, say, more than twice the standard deviation off the average value?
He tells me that he now starts getting service requests from in-house: “I heard that you could measure the time between arbitrary activities?”. That’s exactly what we hear from people who run into the limits of analyzing process data in Excel, but he’s certainly doing this on a much bigger scale.
_Would you like to see your own process project (development or improvement) be represented on this blog? Contact Anne to tell her more about it. _
Leave a Comment
You must be logged in to post a comment.






