

Process Mining Case Story: Copenhagen Airports A/S

This is a guest post by John Hansen, Author of the blog www.processmining.dk, and Claudia Billing from Copenhagen Airports A/S. Both share their experience from applying process mining to a process at Copenhagen Airports based on Bag-tag data extracted from the Bag-tag system.
If you have a process mining case study that you would like to share as well, please contact us at anne@fluxicon.com.
Process and Data
Everyone has dropped off and picked up luggage at the airport, but what happens behind the scenes?
Every bag that is checked in or transferred through the airport gets a bag-tag that contains valuable information about the destination flight. All bags are handled in the baggage sortation factory, ensuring that they end up on the right flight on time.
The Bag-tag is scanned multiple times on its way from check-in, through the baggage factory, and to the aircraft. Furthermore, and you may not know this, when customers arrive early at the airport, then their luggage is actually not directly sent to the place at the airport where it will be picked up for upload to the aircraft, but it is first sent to a storage facility (a kind of “baggage hotel”) for some time before it is retrieved again.
The process needs to meet several performance KPIs. Because of the different scenarios (different destinations, without storage vs. with storage, etc.) the process can vary significantly and the process mining project was started to have a closer look at how exactly the process looks like based on the Bag-tag scan data.
Approach
The approach that was taken in the project was to look at the results in iterative cycles with close collaboration from the domain expert. This way, first analysis results were obtained in an exploratory manner and then refined in the following iterations.
For example, one challenge was to understand and simplify the data from a spaghetti-like process overview into meaningful details by filtering and slicing the process data.
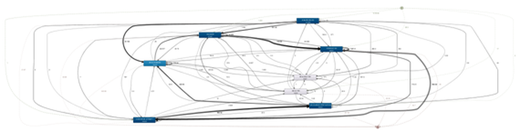
Figure 1: Overall process (starting point of the analysis)
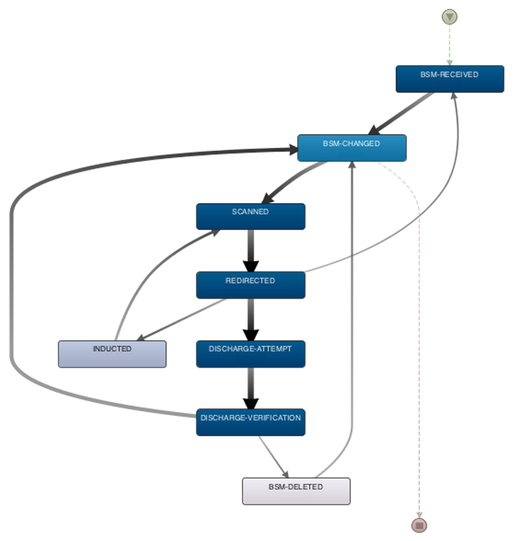
Figure 2: Detail-view of the process after applying filters for focusing on specific aspect
Also, different perspectives were taken on the data, which allowed to explore different questions and analysis views. Overall, the knowledge about the desired process and the operational KPIs were guiding the analysis.
Results
From the process map and the related process statistics, interesting details were discovered such as “Where are the bottlenecks?”, and “Are those primarily in the baggage factory belts or in the surrounding events?”. Furthermore, the Bag Throughput KPI was analysed and possible reasons for discrepancies from the target values were determined.

In one of the analysis perspectives, the location, where the bag was scanned, redirected, etc., was incorporated in the activity (see above). This perspective made it possible to easily see the performance in the process steps related to locations.
For example, the average number of minutes from the operated check-in to the bag being seen for the first time in the baggage factory. Or the average time luggage was stored due to early arrival. Information like this is valuable to get a full picture of the overall process, and having it right at hand is a huge advantage.
This overview then helped to identify the challenge areas and likely root causes. It also helped to rule out other root causes. For example, the process bottlenecks were generally not related to the baggage factory belt performance.
Takeaway Points
Although there was not a specific hypothesis to check prior to the Process Mining analysis, it was possible to to identify valuable insights very quickly. It was a big advantage that not all the questions needed to be defined upfront. Instead, the Copenhagen Airports analysts valued particularly that while the main bag process was mapped out quickly, it was still possible to uncover and analyze variations from the main process in detail in an explorative way.
This way, it was possible to learn more about the process and discover new insights in each iteration. By seeing the actual process without assumptions, and digging into the actual process patterns that were discovered, analyses could be done much quicker and in much more detail than in a question-answer-based, traditional way.
In summary, the takeaway points are:
-
An overall process overview was obtained quickly and interesting facts were easy to identify. For example, weekends have more circulations than other days.
-
It was possible to identify likely reasons for KPI discrepancies.
-
Being able to identify areas with potential process challenges prior to a more in-depth analysis, the analysis could be concentrated on areas with possible process challenges, as opposed to the traditional approaches where the process areas that are analysed in detail are not necessarily those having the most challenges.
-
The easy and fast way of looking at the process from different perspectives (for example considering the locations vs. not considering the locations) revealed many new insights. The perspective could shift from KPIs and bottlenecks, to process performance related to locations.
-
Root cause analyses could be done quickly based on the evidence. For example, the process bottlenecks were generally not related to the baggage factory belt performance.
-
It was possible to compare process performance for special days (e.g. days with mechanical breakdowns) to average or good days.
-
It was fast and easy to get an overview of the process performance.
-
As with all data analyses, the process mining analysis is dependent on getting the right data, which was improved iteratively. It’s an advantage to start quickly with what you have and then to enhance the data in the iterative work.
Authors:
John Hansen, Author of the blog www.processmining.dk
And
Claudia Billing, Copenhagen Airports A/S
Leave a Comment
You must be logged in to post a comment.






