
Preventing Application Fraud with Machine Learning and AI
Blog: Enterprise Decision Management Blog

In 1997, the IBM supercomputer Deep Blue beat chess grandmaster Garry Kasparov. This defeat skyrocketed artificial intelligence (AI) into the headlines. Twenty years on, AI has transformed our daily lives: from the medical field to voice controlled devices that will order your favorite pizza to self-driving autonomous vehicles. But how can it best be used to fight application fraud?
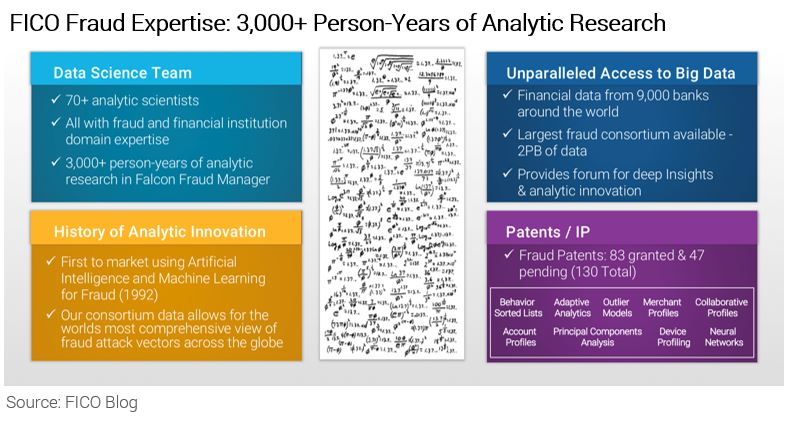
It was not much before Deep Blue, in 1992, that FICO pioneered the use of artificial intelligence and machine learning to fight credit card fraud. Fraud losses on US credit cards were reduced by over 70% since the introduction of FICO’s real-time anti-fraud analytics. This is perhaps one of the earliest use cases of using AI moving past academia to solve a real-world business problem.
FICO didn’t stop there. We continue to innovate with a dedicated team of 70+ data scientists in our R&D arm fighting against fraud cross-product and cross-channel across the enterprise. With over 9,000 financial institutions continually contributing data to the FICO Falcon consortium, we have petabytes of data to learn from.
Now we are tackling an exponentially growing type of fraud — application fraud – and we recognize that machine learning analytics must be a critical part of a financial institution’s control strategy. With everyone talking about machine learning and artificial intelligence, it’s important to level what these terms actually mean and to understand how we can operationalize these analytic innovations in a way that makes sense in a highly regulated lending environment.
How Is AI Different from Machine Learning?
Artificial intelligence uses computers to mimic the human brain and perform tasks that require intelligence and learning. While machine learning and artificial intelligence are often used interchangeably, machine learning is a subset of artificial intelligence that uses algorithms to exhibit intelligent behaviors. Machine learning algorithms do what humans cannot: siphon through massive amounts of data and produce scores that, for example, rank-order transactions from highest to lowest likelihood of fraud.
Scores add precision to the broad-brush approach of rules-based detection. Instead of coding up and alerting on known patterns of how fraud operates, machine learning analytics are sensitive to the complex, multi-variate attributes that predict fraud – whether it’s payments fraud, application fraud, account takeover, mass card compromise, or more.
Generally speaking, machine learning analytics fall into two broad categories: supervised and unsupervised.
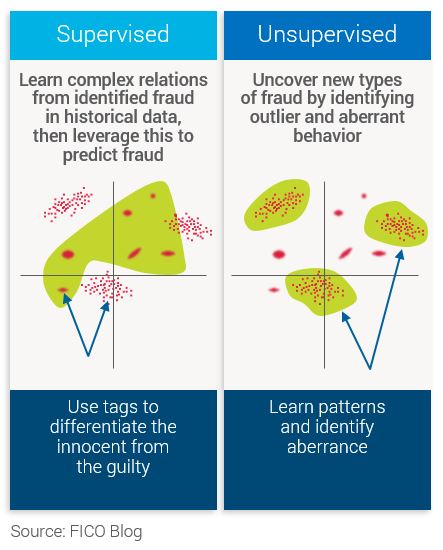
A supervised model is a model that is trained on a rich set of properly tagged or labeled (e.g., fraud and non-fraud) examples. Although typically more accurate, supervised models do require frequent retraining to keep up with evolving fraud modus operandi.
Unsupervised models, on the other hand, do not require previous tags and rely on outlier detection to find aberrant behavior that is indicative of fraud. This starts with understanding the archetype or peer grouping of a transaction to detect where this transaction is acting differently than expected.
For example, if an applicant for an auto loan is sub-prime, the vehicle is an economy compact vehicle, and the stated salary is $35,000, this application is likely in a very different peer group than an applicant with an 800 FICO Score borrowing money for a Mercedes G-Series. If we understand who we should be comparing each applicant to, the inherent assumption is that higher the aberrance to expected behavior, the higher the likelihood of fraud.
Unsupervised models are handy in situations where there is a lack of fraud exemplars, for example if a new type of product or channel is launched. And although these models do not offer complete protection against all fraud attacks, they do provide an important line of defense against new attacks and alongside supervised models can provide enhanced prediction.
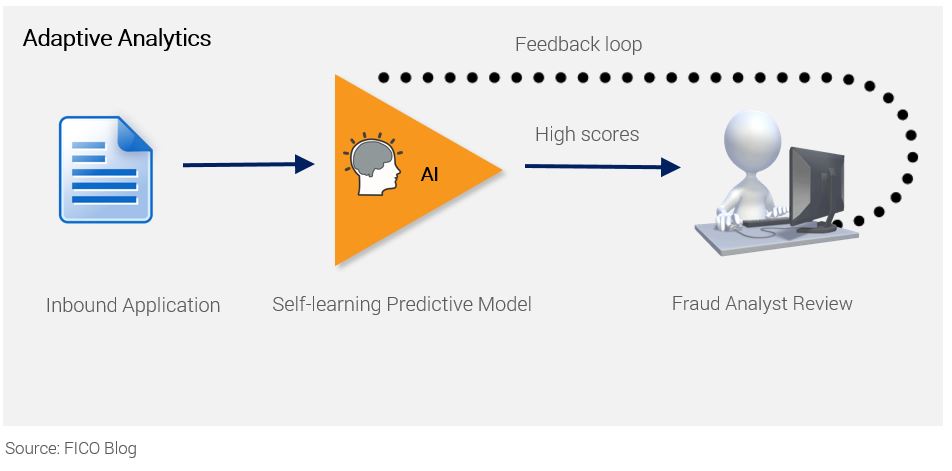
Self-Learning Scores
Whether supervised or unsupervised techniques are used, self-learning models provide an added layer of resiliency and longevity to the robustness of a score. Also known as adaptive analytics, self-learning techniques mean that models can continuously learn about new behavior patterns by using the actual outcomes and feedback that fraud analysts provide on worked cases. These scores fine-tune attribute weights, automatically refresh algorithms, and adjust final scores predictions accordingly.
Machine Learning to Fight Application Fraud
As with most good things, there is a catch: Operationalizing machine learning, particularly in highly regulated environments such as lending, requires significant consideration. Many machine learning algorithms are considered “black box” models that do not give fraud analysts, consumers, or regulators the appropriate insights into decisioning logic, e.g., “Why am I being declined for credit?”
This is why explainable artificial intelligence is so important: to impart the necessary transparency to pass regulatory muster, while maintaining accuracy of prediction.
FICO are very cognizant of the impact of regulations to our business and for our clients. In fact, we pride ourselves in leveraging mathematical innovation to solve problems in the real-word. In the area of account originations, our credit risk and fraud scores are designed to be a tool to assist lenders with compliance to applicable fair lending laws such as the Fair Credit Reporting Act, Regulation B, and the Equal Credit Opportunity Act (ECOA).
Stay tuned because our plan is to dive even deeper into machine learning for application fraud with our next few posts. In the meanwhile, check out our previous posts on application fraud, including:
- Trends in Application Fraud – From Identity Theft to First-Party Fraud
- Best Practices in Establishing Your Fraud Risk Appetite
- ELI5: How Does the Dark Web Work?
- What Data Do I Need to Fight Application Fraud?
- Best Practices in Fraud Management: Q & A with Bob Shiflet
Learn More at FICO World 2018
Want to learn more about AI? Join us at FICO World, April 16-19 in Miami Beach. In addition to presentations from our chief analytics officer, Dr. Scott Zoldi, and others on AI and its applications in fraud, we’re excited to have keynote speaker Garry Kasparov share with us what really happened with Deep Blue.

The post Preventing Application Fraud with Machine Learning and AI appeared first on FICO.
Leave a Comment
You must be logged in to post a comment.






