

Nitro 3.0

It has been less than a year since we first released Nitro, and when I take a look back at version 1.0 it amazes me how far we have come since last September. We have made it simpler to use and get your job done with every release, we have added new analysis, import, and export features, and – last but not least – we have steadily improved its best-of-class performance.
Our product philosophy here at Fluxicon is quite simple. We look at the hardest and most pressing problems faced by process mining professionals, and then we think long and work hard to find new, better solutions. With Nitro, we think we have absolutely nailed the problem of getting your real event logs from CSV and Excel files into the standard MXML and XES formats you need for a process mining analysis. Nitro 3.0, available today, takes a huge leap towards making that procedure much more efficient and enjoyable.
With Nitro 3.0 we are introducing log filters. Almost every real-life log contains errors, inconsistencies, and other undesirable artifacts that you need to fix before you can start mining. Filtering is also an essential tool to focus your analysis, and to drill down into specific aspects of your process. We have been working with existing solutions, like ProM’s set of filters, for a very long time, but we have never been quite happy with the procedure. With the log filters in Nitro 3.0, we think that we have found a much better approach which turns this formerly tedious task into a quick, productive, and rewarding experience.
Nitro 3.0 is available immediately via auto-update, and for download at www.fluxicon.com/nitro/.
Before I get more into our new log filters, let me quickly introduce some of the other new features we are introducing with Nitro 3.0.
Extended log statistics
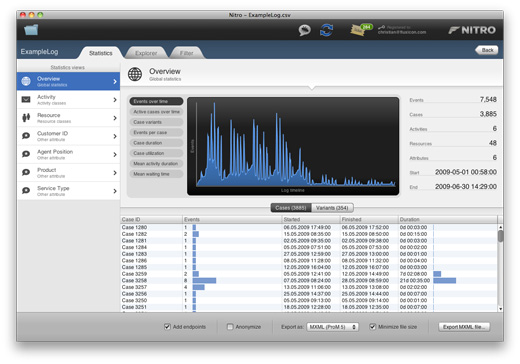
After you have loaded a log Nitro shows you the statistics view, which gives you both a high-level overview of your data, as well as tools to drill down into different dimensions. In Nitro 3.0, we have added three new charts describing performance characteristics of the cases in your log in the Overview panel:
-
Case utilization: See how much time per case is spent executing activities, relative to the total case duration
-
Mean activity duration: See how much time per case is spent, on average, in an activity.
-
Mean waiting time: See how much time per case is spent, on average, between two activities.

Another addition is the ability, in the Overview panel, to show a table giving an overview about the variants in your log, alternatively to the case overview table. This table provides you with a more condensed overview about the variation in your data set.

The tables on the bottom of the attribute and event class views show statistics for each value of that respective attribute. With Nitro 3.0, you can now switch this table to alternatively show only start or only end values, i.e. only those values which have occurred at the very beginning or end of a case.
Export options
Nitro can export your data to the standard MXML and XES formats for process mining, as well as to the CSV format which is supported by a lot of analysis software. With Nitro 3.0, we have added two export features which makes sharing and further analyzing your data a more seamless experience.
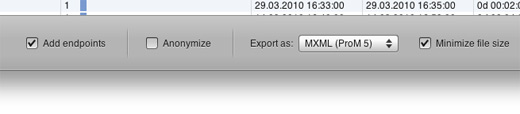
When you enable the add endpoints option, Nitro makes sure that every case starts and ends with the same, single activity. This enables you to clearly see the starting and ending point of your process in mined process models. As you would expect, though, Nitro is smart about adding these endpoints – if your data already has a single start or end activity, it will not change a thing.
Sometimes you would like to share your data with another process mining expert to get their opinion on how to best analyze it. If your data is confidential, though, simply emailing it along is clearly impossible. For these situations, you can now check the new anonymize option, which will hide all concrete data in your log, as well as obfuscate the exact timestamps.
Log filters
Filtering is an essential step in every process mining analysis project. On the one hand you often need to clean up your log (by removing incomplete cases, superfluous or erroneous events, or other anomalies) in order to derive meaningful conclusions from your analysis. On the other hand, filtering also allows you to better focus your analysis into specific subsets of your data. By drilling down into the slowest cases, the ones with the most errors, or simply cases started in a particular month, you can often dramatically increase your insight into particular properties of the analyzed process.
We have added a log filtering tool to Nitro 3.0, which makes both cleaning up your log and drilling down into particular subsets fast, efficient, and effortlessly intuitive.
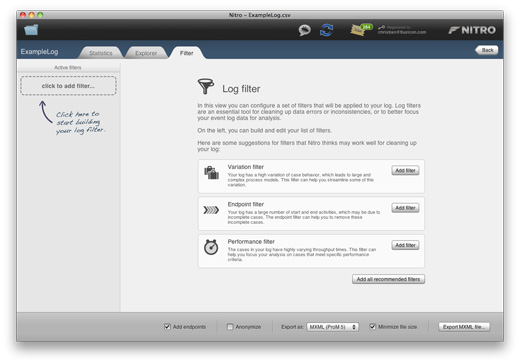
To start filtering your log, simply select the third “Filter” tab in the result screen after loading your log. On the left you can find an, initially empty, list of your configured filters. On the right, Nitro shows you some recommendations for log filters it thinks may be suitable for cleaning up your log, which is a great starting point to get going fast.
You can add recommended filters, or start by directly picking a set of filters on the left. Use the list of active filters on the left to navigate the configuration panel of your added filters, rearrange them (i.e., move filters up or down the list), remove filters you no longer need, or add new filters.
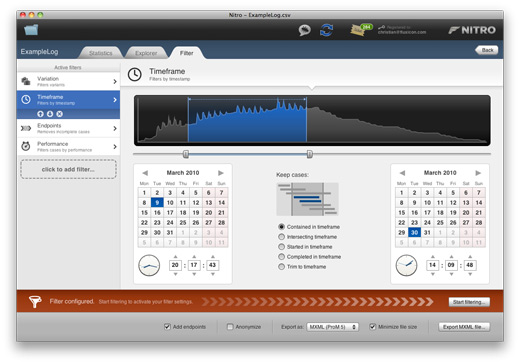
We have created an initial set of six log filters that each address a specific task, and which you can combine to accomplish also complex filtering objectives.
-
Timeframe: This filter, of which you can see the configuration panel above, allows you to restrict the cases and events in your log to a specific timeframe, which is useful for removing events with erroneously-logged timestamps. It is also a great tool for quickly focusing your analysis on a specific timeframe, like only those cases started last month.
-
Variation: Many processes have a lot of “sunny day” cases which all feature the same sequence of activities, as well as a “long tail” of exceptional cases, which are pretty much unique. The variation filter allows you to focus your analysis on the mainstream of behavior, made up by the most frequent variants, on the more unstructured, exceptional end, or on any other part of the spectrum.
-
Performance: With this filter you can easily focus your analysis on a subset of cases with interesting performance characteristics. Whether you want to look at the longest-running cases, those with the longest idle time, or simply those with more than ten activities, this filter makes it a snap to accomplish.
-
Endpoints: Sometimes you know that your process can only start and end with a certain set of activities, but your log contains a lot of incomplete cases that were either started before, or ended after the log was recorded. With this filter, you can specify the subset of allowed start and end activities, and remove incomplete cases. You can also focus your analysis on subsequences of traces between specified endpoints.
-
Attribute: This filter allows you to remove events with certain attribute values. You can also set some values to be mandatory (i.e., only use cases where an event with that value occurs) or forbidden (i.e., remove cases with certain events).
-
Follower: With this filter you can select cases where a specific pattern of activities occurs. You may, for example, be especially interested in cases where the “Request order” activity is eventually followed by an “Approve order” activity. And if you want to know where these two activities were executed by the same person (i.e., a violation of separation of duties), you can easily add that requirement as well.
This is only a short description of what you can do with these filters. We are going to give you a more thorough introduction to some of our new log filters in the coming weeks on this blog.
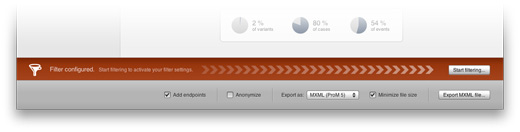
When you have configured filters for your event log, the orange-colored filtering control bar will show up on the bottom of Nitro. Its purpose is to remind you that your filter settings are not yet active. We have managed to make filtering amazingly fast in Nitro, so whenever you want to check the effect your filter settings are having on your log, don’t hesitate to start filtering.
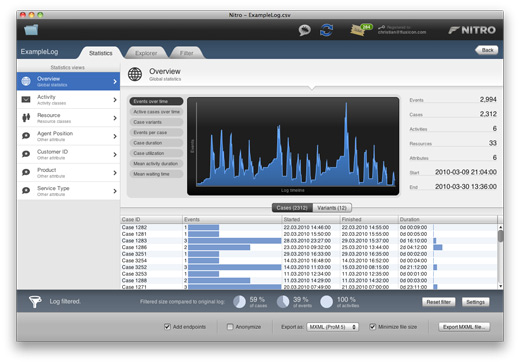
After you have started filtering, Nitro applies your currently set filter configuration to your original log (as loaded from your CSV, Excel, MXML, or XES file), which happens almost instantly for moderately-sized logs. Once finished, the information displayed in the Statistics and Explorer tabs shows the result of filtering. The filtering control bar changes color to a darker blue, and shows you an overview of the size of the filtered log, compared to your original log.
Log filtering in Nitro is non-destructive, i.e. you never lose your original log data. If you click the “Reset filter” button in the filtering control bar, or if you remove all filters from your list of active log filters, you will be back to square one. This means, the Statistics and Explorer tabs will show again your original log data, and you can export it as such (or, of course you can also start configuring a different set of filters).
We have gone to great lengths in designing the Nitro log filters’ user interface to be intuitive and efficient to use. You will also notice that the non-destructive nature of filtering in Nitro enables you to focus your analysis more efficiently. For example, you can filter your log to cover the fastest cases and export that subset. Then, you can change your filter settings to cover only the slower cases, and export that subset. This is just one example of many common use cases which are way faster to perform in Nitro than in other solutions.
Final words
It was no easy task to design a log filter for Nitro that meets both our requirements and our standards. We wanted something fast and efficient that lets you get your job done quickly, and something that was also actually fun to use, just like Nitro itself. We hope that you will love our new filters just as much as we do.
There are lots of other small new features, additions, and bug fixes in Nitro 3.0, and many of these are the result of all your feedback. Thank you so much for using Nitro, and for letting us know what we can do to make it even better! Please keep letting us know about your experience with Nitro, and whatever you’d like to see improved.
Nitro 3.0 can be installed from Nitro itself via auto-update (if you are running a recent version of Nitro). And of course you can always download installer packages for Windows and Mac OS X at www.fluxicon.com/nitro.
Leave a Comment
You must be logged in to post a comment.






