
Multitenancy in Flowable
Blog: Flowable Blog
Authors: José Antonio Álvarez, Simon Maier
The concept of multitenancy is widely mentioned in modern architectures, especially with the growth of cloud computing. Applications supporting multitenancy allow different organizations (or tenants) to share a single instance of software while keeping their data isolated from each other.
Companies benefit in several ways from the multitenancy concept:
- Economic advantage: The costs of maintaining one instance for N tenants are lower than maintaining N instances. Less infrastructure, monitoring and resources in general are needed to service all customers. In fact, maintaining different instances for different tenants can render the maintenance unmanageable if the number of tenants is large.
- Reduced complexity in releases and upgrades: By upgrading the instance, multiple tenants benefit at once from the new software features and security patches.
- Increased efficiency in reporting: When using multitenancy within an organization to handle multiple departments, company-wide performance reporting can be achieved without having to aggregate the information from several distributed databases.
On the other hand, additional costs can incur because the setup effort for multitenancy is generally higher, and dedicated security testing has to take place to avoid the exposure of information across tenants. Also, all tenants are obliged to upgrade, or be upgraded, at the same time.
Shared-Engine / Shared-Schema
Flowable supports multitenancy by partitioning the data inside the database schema, which allows different tenants to share a single database and schema, sometimes called shared-schema multitenancy.
All objects created by the engine can be assigned to a tenant:
- Deployments
- Process Definitions
- Process Instances
- Tasks (process and standalone)
- Executions
- Async Jobs
- Historic Entities
- …

Technically, this is achieved by using a tenant identifier (database column TENANT_ID_) for all the entities above. This allows an easy retrieval of objects belonging to a specific tenant by just enriching the query with the tenant information. All Flowable APIs provide parameters to define the tenant identifier, for both reading and writing operations. For instance, retrieving all process instances for tenant1 is as easy as:
runtimeService.createProcessInstanceQuery()
.processInstanceTenantId("tenant1")
.list();Shared-schema multitenancy applications have the advantage that the deployment and maintenance is simple, as a single instance provides service to multiple tenants simultaneously. Adding new tenants to the system is straightforward and does not require complex operations. Something worth noting is that besides sharing the database schema, all tenants would share other system resources such as CPU time, memory, threads, and so on.
An out of the box Flowable instance supports multitenancy without requiring further configuration. An important aspect to mention is that Flowable does not implement a default set of rules for multitenancy access: Applications, systems or layers calling Flowable must implement them according to functional requirements. In practice, this means that the developers have to check which queries must return information for a specific tenant and enhance them with the corresponding method. In the example above, processInstanceTenantId guarantees this. The object creation operation is simple, as the Flowable implementation follows an inheritance rule that simplifies the development:
• Deployments can be given a tenantId:
repositoryService.createDeployment()
.addClasspathResource("...")
.tenantId("tenant1")
.deploy();Definitions contained in the deployment inherit the deployment’s tenant ID:
• Created instances inherit the definitions’ tenant ID
• Sub-elements from instances (Process Tasks, Subprocesses, etc.) inherit the parent’s tenant ID
• Other technical entities such as Executions or Async Jobs inherit the tenant ID from the instance.
Models (objects created with the Flowable Design tools) have a tenant ID as well that can be used to restrict access to them from other tenants.
Tenant-specific Async Executor
As mentioned before, all tenants share the same machine resources and it is not possible to give some of them more priority in the allocation of machine resources. However, there is an option to assign different Async Executors for each tenant, so the throughput of Async tasks can be tweaked for specific tenants.
For more information, see the implementation in: org.flowable.job.service.impl.asyncexecutor.multitenant.ExecutorPerTenantAsyncExecutor.
Multi-Engine / Multi-Database
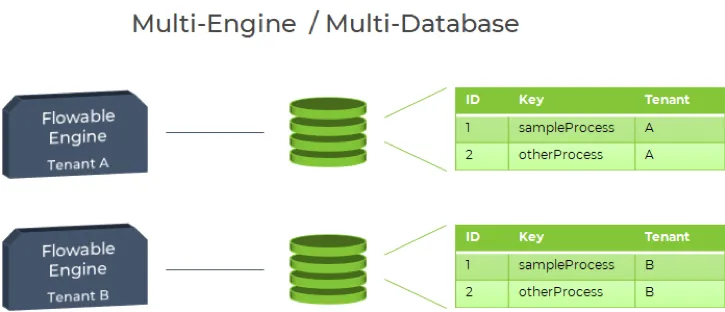
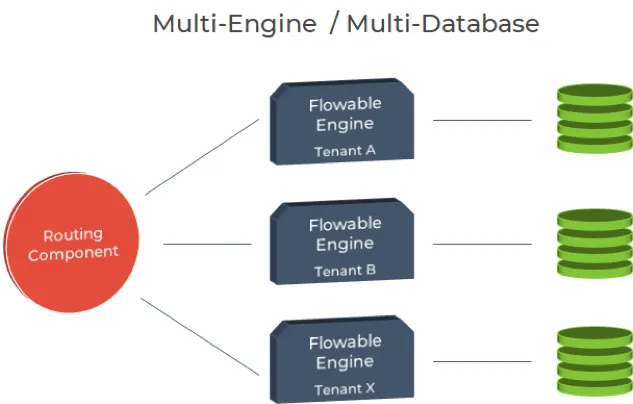
This approach is conceptually the most simple one: each tenant has its own Flowable Engine and database schema. Note that the engines do not have to coexist on the same server, they can run on different servers (real or virtualized). This setup offers the maximum flexibility: each server can be defined with different hardware and engine configurations.
Each Flowable Engine requires a different configuration and setup, which increases the complexity for managing the application. In the case of multiple engines for a single instance, each tenant requires at least the configuration for the database schema and possibly other tenant-specific configurations. In setups where engines reside on different servers, each machine has to be separately configured and managed, meaning the application lifecycle operations (for example, deploying a new version and restarting) have to be performed for each one of them.
Whenever an operation requires the usage of a specific tenant (such as triggering the creation of one task via REST), an application component must resolve (or route to) the appropriate engine. This component is not provided out of the box and has to be written tailored to the application architecture.
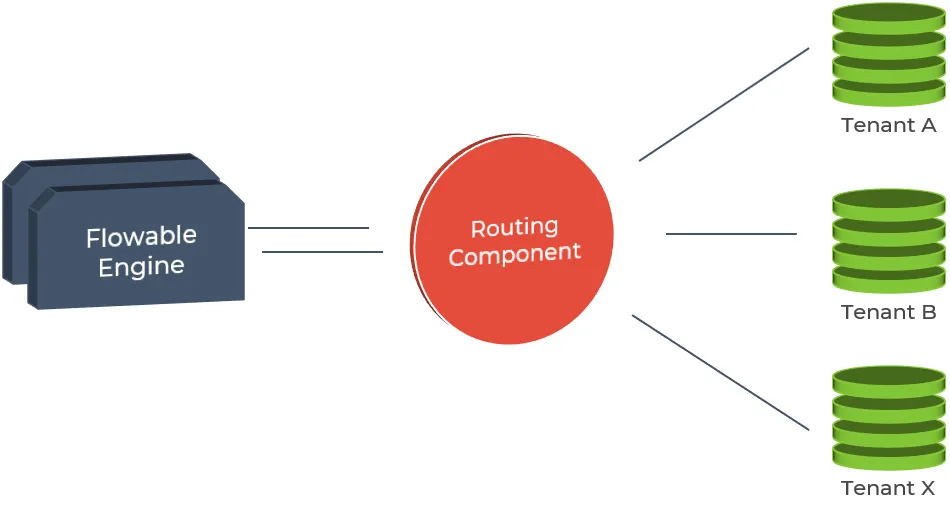
Shared-Engine / Multi-Schema
This mode is a variant of the shared-schema multitenancy and provides the highest level of data isolation. Instead of partitioning the data within the same database schema, each tenant will have its own schema.
The engine configuration is rather simple in this case, as only one engine has to be configured. The only complexity this approach adds is the management of separate database schemas. But this is a low cost investment if achieving effective data separation is a requirement.
Flowable provides an API to ease the setup by providing a configuration class called MultiSchemaMultiTenantProcessEngineConfiguration, where multiple instances of DataSource can be assigned to different tenants. See the following snippet for an example:
config = new MultiSchemaMultiTenantProcessEngineConfiguration(tenantInfoHolder);
config.setDatabaseType(MultiSchemaMultiTenantProcessEngineConfiguration.DATABASE_TYPE_H2);
config.setDatabaseSchemaUpdate(MultiSchemaMultiTenantProcessEngineConfiguration.DB_SCHEMA_UPDATE_DROP_CREATE);
config.registerTenant("tenant1", createDataSource("jdbc:h2:mem:flowable-tenant1;DB_CLOSE_DELAY=1000", "sa", ""));
config.registerTenant("tenant2", createDataSource("jdbc:h2:mem:flowable-tenant2;DB_CLOSE_DELAY=1000", "sa", ""));
config.registerTenant("tenantN", createDataSource("jdbc:h2:mem:flowable-tenantN;DB_CLOSE_DELAY=1000", "sa", ""));
processEngine = config.buildProcessEngine();New tenants can be added by creating new database schemas and adapting the configuration, which can also be done at runtime:
config.registerTenant("new-tenant", createDataSource("jdbc:h2:mem:flowable-new-tenant;DB_CLOSE_DELAY=1000", "sa", ""));After the configuration above takes place, the engine is fully aware of all registered tenants and their DataSources. As a result, there is no need to implement an additional routing component as needed for the multi-database case. Internally, the engine will resolve the corresponding DataSource based on the tenant information provided by the TenantInfoHolder parameter.
This approach requires the implementation of a class that implements the Java interface TenantInfoHolder. The method getCurrentTenantId() must return the tenant ID for the current operation. Usually this information is stored in a ThreadLocal object or in the authenticated user context.
The Right Multitenancy Setup for your Organization
In order to offer a reasonable quality of service, the application setup must scale to adapt to a growing number of tenants or an increasing resource consumption or both.
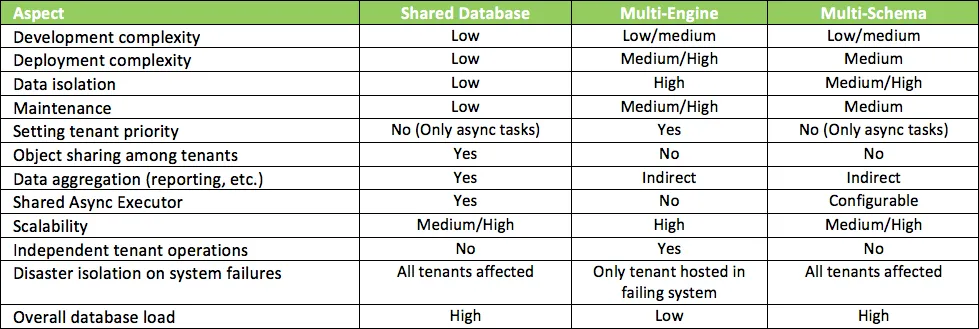
Take, for instance, the Shared-Engine/Shared-Schema mechanism: all tenants share or compete for the same resources (CPU cycles, memory, database schema and so on). For a high number of tenants, in particular when all tenants use resources frequently, the overall performance can be affected. In the Multi-Engine/Multi-Database approach, each tenant requires a different instance, therefore the limit is given by the maximum amount of instances an organization is able to maintain and service.
If a tenant is expected to grow significantly over time, the Shared-Engine/Multi-Schema approach allows easy data migration of a smaller tenant to a dedicated instance in the future.
For large tenant sets, a hybrid solution can be implemented by partitioning the set into smaller subsets, then having a Shared-Engine/Shared-Schema instance for each partition. This still has the advantages of the Shared-Engine/Shared-Schema approach but scales better because instances will work on a smaller dataset. Depending on the partitioning strategy, advanced capabilities can be achieved, as resource-intensive tenants can be deployed in more performant environments. On the other hand, some requirements from the Multi-Engine/Multi-Database mode still apply here, such as the additional effort to maintain several instances, one for each partition, and the prerequisite of a routing component.