
Multi Instance Variable Aggregation
Blog: Flowable Blog
Introduction
Flowable has supported running Sequential and Parallel Multi instance executions since its very beginnings, as it is a fundamental concept in BPMN. It has different use cases, such as allowing multiple users to give review feedback through a task, or executing a complex review (sub) process with multiple user tasks and automatic service tasks, and so on. A very typical use case is that after such multi-instance work there is follow-up “overview task” where you want to see the output of the previous tasks in a collection. Also, the number of reviewers may not be fixed but determined dynamically as part of the process.
If all of this sounds familiar and triggers some (perhaps painful) memories of when you’ve tried to implement such a pattern before … we have some good news for you! In our upcoming 6.6.1 release, it will be extremely easy to create multi instance user tasks (or anything more complex), let the users complete them and then aggregate all of the input in a single collection. For this blog post we are going to work with the following (really simple) process to explain things.

- Get application details – has a form to collect the details for the loan application and who needs to provide feedback
- Review application by – a Parallel multi instance User Task with a form to collect the feedback about the loan from the different reviewers
- Review application – where the final decision for the loan is made and where the feedback of the other reviewers is provided
Task details
Now that we have seen the process we will run it and go through each task to show the variables that it will create. We’ll skip the details of defining the forms used as there’s nothing special there, just collecting values that become process variables used in the aggregation.
In the the first task Get application details we are going to gather the fullname (fullName), age (age) and the requested loan (requestedLoan) of the applicant. Additionally, we are going to capture the reviewers’ names and score weights. We will use a reviewer’s score weight to adjust their score in our final calculations.
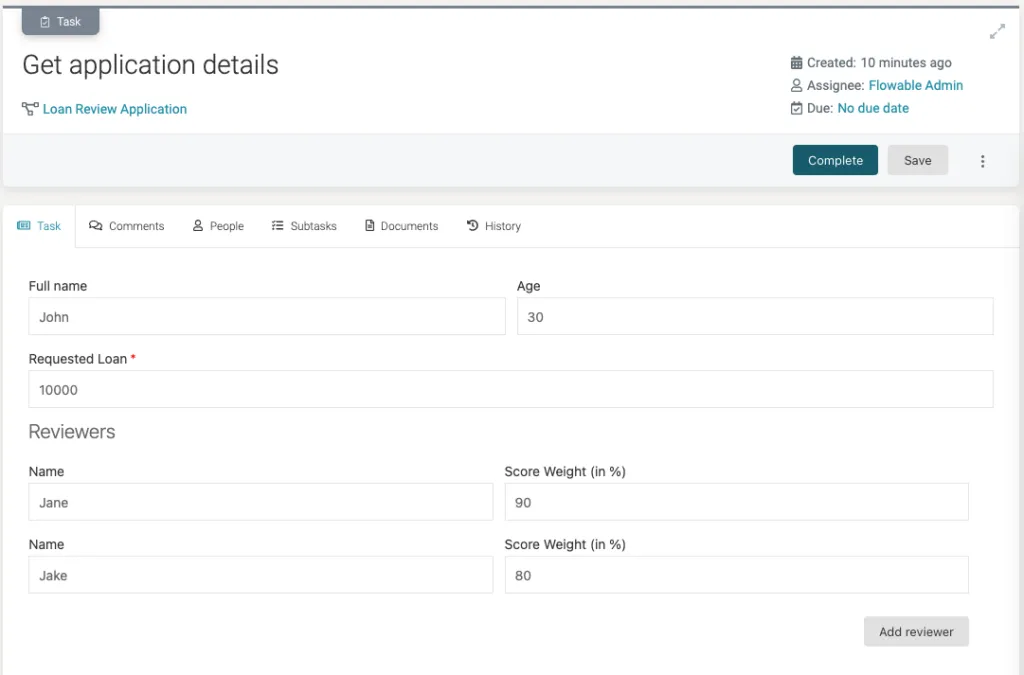
Once we complete the first task we will be greeted with 2 new Review application by tasks. One for Jane and another one for Jake.
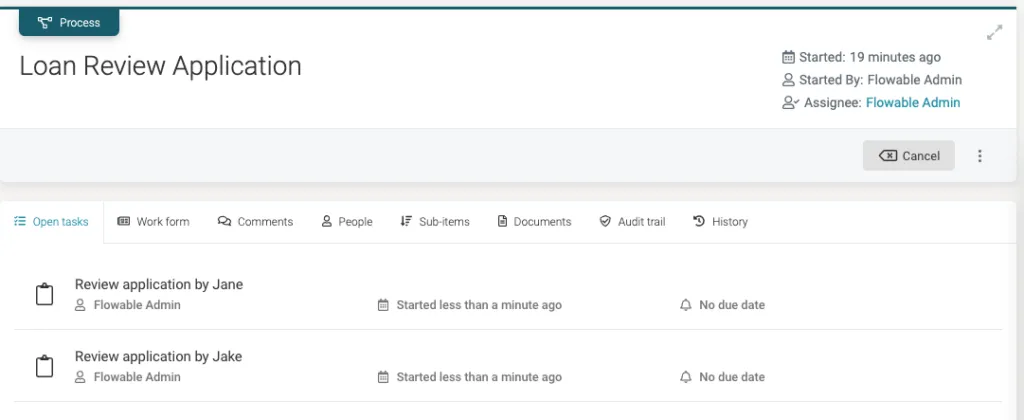
In the Review application by Jane task we can see the information provided for the applicant and can collect the Score (score) and Comment (comment) from the loan reviewer.
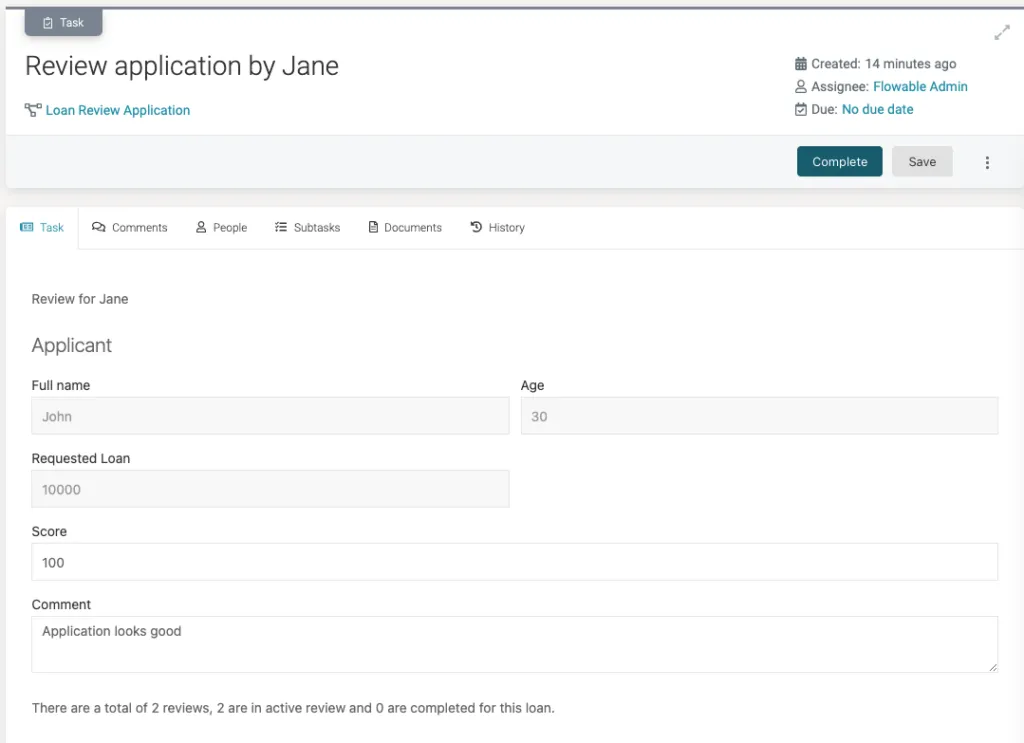
Notice we can show that there are 2 reviews in total and 2 of them are active. We give it a score of 100, leave a comment and then complete it. Once that is done, we head over to the Review application by Jake task.
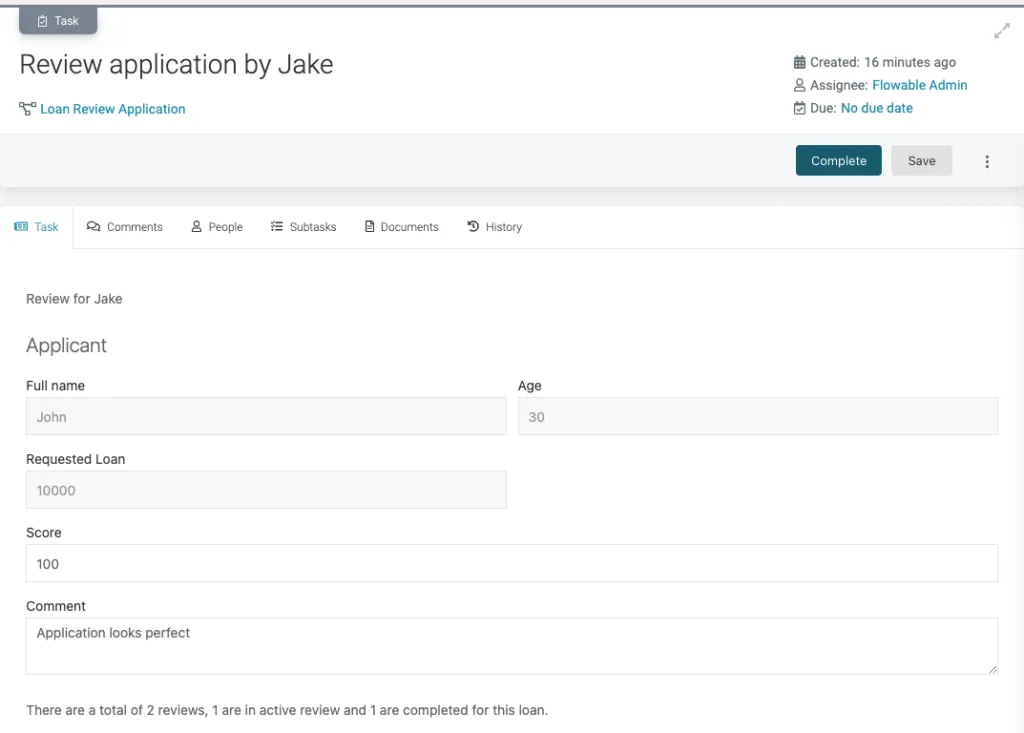
Now we can see that there is 1 completed review (the one from Jane) and 1 active (the one for Jake). Note that the data we provided (score and comment) by Jane is not available as direct variables for this task. Also, those submitted variables are not yet visible at the process instance level. This can be confirmed by checking using the REST API:
[
{
"name": "requestedLoan",
"type": "integer",
"value": 10000,
"scope": "local"
},
{
"name": "initiator",
"type": "string",
"value": "admin",
"scope": "local"
},
{
"name": "fullName",
"type": "string",
"value": "John",
"scope": "local"
},
{
"name": "reviewers",
"type": "json",
"value": [
{
"name": "Jane",
"scoreWeight": 90
},
{
"scoreWeight": 80,
"name": "Jake"
}
],
"scope": "local"
},
{
"name": "age",
"type": "integer",
"value": 30,
"scope": "local"
}
]We can now complete the Review application by Jake task with a score of 100 and a comment. This leads us to the final Review application task.
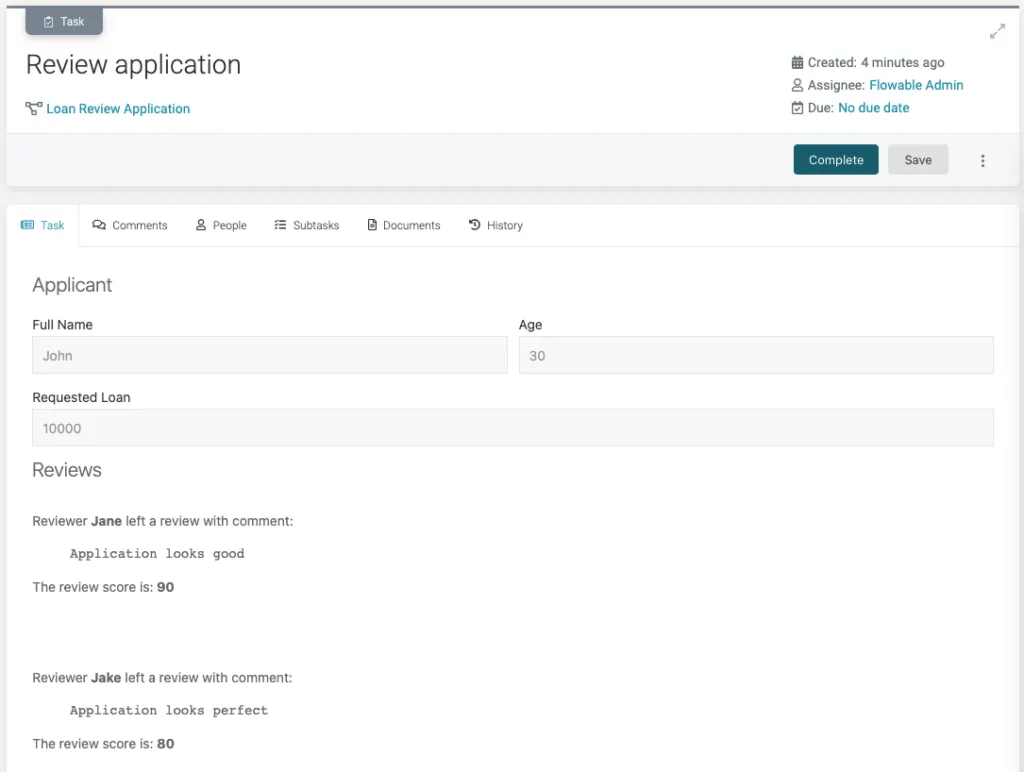
Here we can see the scores and comments that were left by both of the reviewers. If we check the process instance variables through the REST API we will see the following:
[
{
"name": "reviews",
"type": "json",
"value": [
{
"comment": "Application looks good",
"score": 90.0,
"reviewer": "Jane"
},
{
"comment": "Application looks perfect",
"score": 80.0,
"reviewer": "Jake"
}
],
"scope": "local"
},
...
]There is a new reviews JSON array variable with the comments and scores for the reviewers. The scores are different then the ones we provided due to the score weight we gave to each reviewer earlier.
Now we’ve shown how the runtime behaviour works, we’ll go behind the covers in the next section to show how you can do this in your own models.
How can you do this?
In this section we will show you how to do this in your own models. In the screenshots we are going to use Flowable Design (our enterprise modelling tool), but the OSS UI Modeler can also be used. Select a model task in Flowable Design and you will see a new attribute from version 6.6.1 called Variable Aggregations in the Multi instance group.
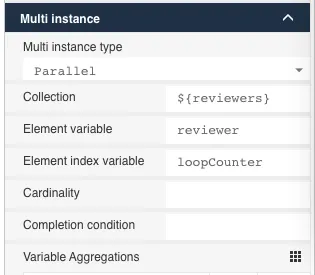
Once we select this attribute, a new dialog will open that looks like:
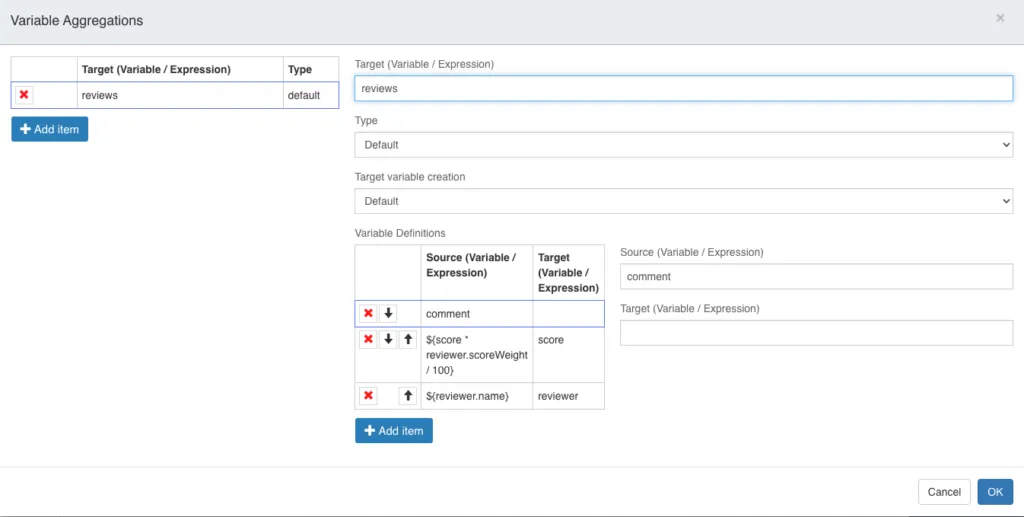
On the left side we can see all the configured variable aggregations (there can be more than one). If we select an existing aggregation or click on Add item, the detailed view is shown on the right hand side.
The first thing we need to do is to give the name of the target variable (or an expression that will provide us with the name). Then specify a type from the following:
- Default – use the out-of-the-box implementation for aggregating the variables
- Custom – define a delegateExpression or class that will resolve to an instance of
VariableAggregator(for BPMN) orPlanItemVariableAggregator(for CMMN). This instance will then be responsible for aggregating the variables.
Next is the target variable creation, which has 3 different options:
- Default – create the variable given in the Target field once the multi instance execution is completed (i.e. when all the child multi instance executions have completed)
- Create overview variable – create a variable when the multi instance is created. This variable will always provide the state of the Target variable when it is accessed. For example, you can access the reviews array at any time from any child execution in order to see the current data. This can be useful in sub processes where you want to access temporary data in the array. Once all the child executions are done it will create a JSON variable in the same way as for Default target variable creation
- Store as transient variable – same as the Default option, but instead of creating a normal persisted process variable it will create a transient variable
Finally, we have the Variable Definitions. Here we can define a mapping between a source variable (or expression) and a target variable. It allows you to decide which variables you want to include in the defined target variable. In the Source section, we give a variable name (or an expression that should be used to extract a value), and in the Target section we give a variable name (or an expression that will give us that name) where we want to store the value from the Source variable. Target is optional when Source is defined as a variable name, which is the same as writing the same value in Source and Target. Let’s go over the example in the screen above:
- We extract the submitted
commentinto a target value namedcomment - We multiple the provided
scorewith thescoreWeightof the review and divide by 100 (${score * reviewer.scoreWeight}) and store that in a target value namedscore - We store the reviewer name
${reviewer.name}in a target value namedreviewer
With the configuration in the screen above, we achieved the state we showed in the previous section. It is important to note that when variable aggregations are provided then the variables stored on a task (or execution or plan item) will actually be stored locally on the first multi instance root instead of the process or case instance. When no variable aggregations are provided then everything works as before. In addition to this, when using variable aggregations only the data provided in the variable aggregations will be retained and the rest will be discarded once the multi instance is completed.
If you’d want to implement this today, it would mean juggling around variables and use hidden task and/or execution listeners to propagate variables. It would be quite hard to do and get right. But now the Flowable engines take care of all of this for you. Also note that we’ve been talking about BPMN here, but all of this is available in CMMN too (called repetition there).
We’ve given the high-level details of how you can use this in your models. If you are interested in the low-level details we suggest that you look at this PR that added this functionality. If you have any questions are comments for this new feature, feel free to post them on our forum.
Wrapping up
This is one of the features that we have wanted to implement for a really long time as it has been a pain point for our users for years. Last September we showed the Top 10 Advances Flowable Made Since Activiti and we are not stopping there. We will continue with the improvements to the core BPMN, CMMN and DMN engines and keep innovating.