Machine Learning: Beyond the Black Box
Blog: The Tibco Blog
In data science circles, the traditional view is that a predictive model does not need to understand why something occurs, it just needs to predict. Very complex models are like black boxes, and the trend has been to create models so black that if you fall into them you’ll end up in a different universe (or — if the film Interstellar is anything to go by — somewhere behind your daughter’s bookcase).
Having a model is generally better than not having one. However, a model is just an approximation of reality and will fail, hopefully as rarely as possible. Understanding why it works, and crucially why and when it does not, is the key to building more knowledge and therefore making better models.
It is therefore refreshing that we are now experiencing a sort of counterflow: if we cannot open up these black boxes, surely we can do something to build trust in what pours out of them. Human nature values insight, new regulations expect us to explain why somebody did not get credit, and we all want to understand what factors lead to cancer.
How good a model is should not simply boil down to a few metrics, such as accuracy or error rate. Yes, it is good to evaluate those metrics, but on top of that, we need a way to “see” how the model behaves. One way to achieve this is by using intelligent visual analytics, to explore not just the data before modeling but, crucially, the results post-machine learning. Another technique that is gaining popularity is to generate simpler, explainable models, such as LIME (Local Interpretable Model-Agnostic Explanations) to test the outcome around particular data — such as people with a similar credit background to mine.
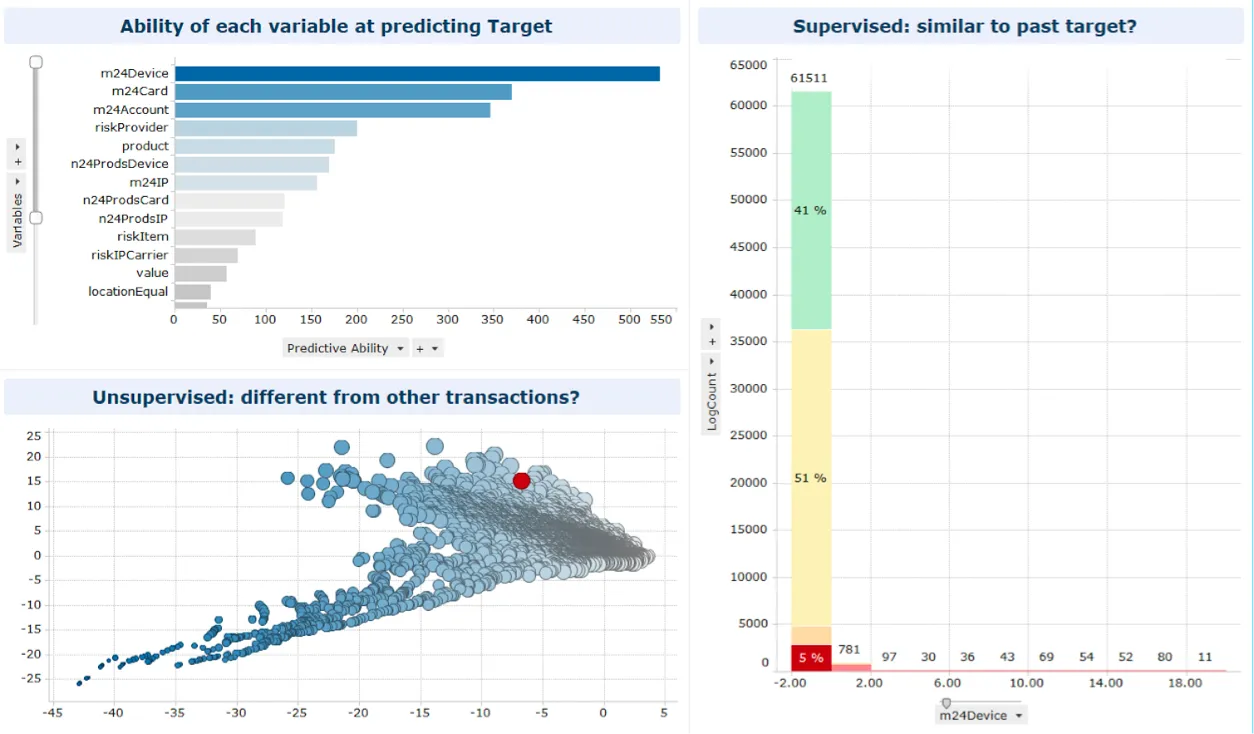
The snapshot below shows a visual example of selecting an individual case among those flagged as a fraud risk, and zooming into the results of two complementary models. The data refers to historical customer transactions and the case at hand is shown in red. The top left plot displays the relative importance of the predictor variables for supervised modeling. On the right, we can see that our case sits within the five percent most suspicious transactions for that value of the most relevant predictor. This is probably why the unsupervised model (bottom left plot) does not identify this transaction as particularly unusual. In conclusion: this is likely to be a fraudulent transaction via a known trick. The combination of these scores helps to form a picture of what features were picked by the model, and how it behaves when predicting.
Whatever the exact techniques, combining the analysis of the global and local behavior of a model is likely to help us build trust, and ultimately produce better algorithms in the future. After all, science is fundamentally the pursuit of knowledge and understanding, why should data science be otherwise?