Kogito Service Discovery for Workflows
Blog: Drools & jBPM Blog
I have recently been wondering: how many times do we find ourselves accessing a specific resource inside a Kubernetes cluster searching for information about how to access it or to expose our awesome service so others can consume it. Right? So, this enhanced service discovery might help you get rid of it by setting a specific static URI that holds all information that the service discovery engine needs to know to translate it to the right service backed by the corresponding Deployment, StatefulSet, Pod, etc.
The service discovery engine, part of the Kogito project, is a Quakus add-on part of Kogito Serverless Workflow engine and for now it can be added to other Quarkus Applications, however it will bring the Kogito Serveriess Workflows dependencies. It is in our roadmap to make the Discovery engine a standalone add-on, allowing it to be added to any Quarkus application. It is expected that you are working with the Kogito Serverless and already have the kogito-quarkus-serverless-workflow extension in the application’s dependencies. For more information about Kogito Serverless Workflow guides.
What’s the problem?
OK, but what problem are we trying to solve here? Well, Kubernetes resources are dynamic and its configuration values can change from time to time, which can require some manual steps later to get the updated configuration, let’s say, by a cluster upgrade or a domain name change that can lead an ingress route being updated or a Knative endpoint being changed as well. The service discovery can help you with that by abstracting these changes from the user keeping the Application that consumes these services up to date.
Instead of rebuilding the whole application so that the Quarkus properties can take effect, just restarting the application is enough. If the application is a Knative Service, then it can be automatically done by Knative if the service doesn’t receive requests for a while since it is scaled to 0 replicas.
But, what’s the difference between the current service discovery that we already have out there?
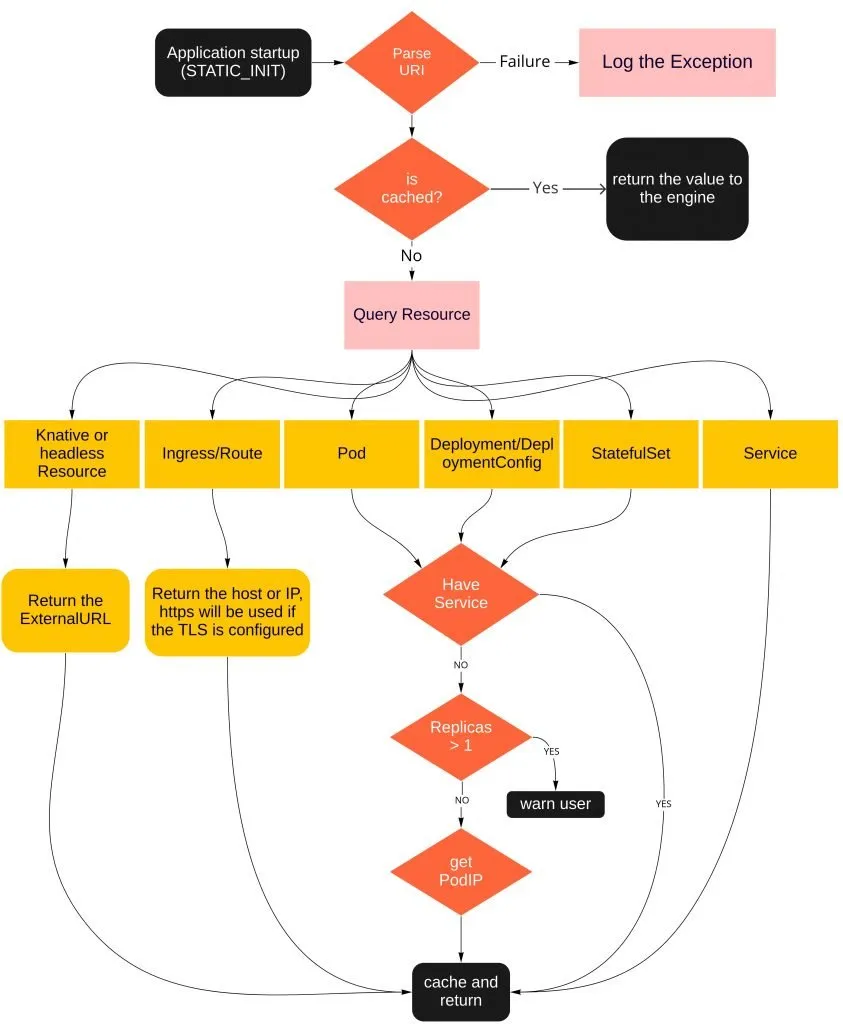
There are a few service discovery engines available. Stork, for example, which is a great option to discover services in a cluster (At the time of publication of this article, we are investigating the new Stork’s new feature that allows custom discovery). However, the Kogito team wanted to move one step forward and, instead of being able to look up only for services, why not be able to search for almost any kind of Kubernetes resources that helps expose the pod? That is where the Kogito Service discovery engine kicks in, with it you can easily discover the most common Kubernetes resources that expose your service or application. Take a look on the picture below that quickly demonstrates how exactly it works:

In a nutshell, the engine scans the Quarkus configuration search for any value that matches the URI that the engine expects. Once found, it queries the Kubernetes API searching for the given resource. Let’s understand how this URI is composed, for more details about it, please visit this link. Take a look in the diagram below:

For the scheme, we have three options to help to better identify where the resource is running on:
- kubernetes
- openshift
- knative
About the Kubernetes resources, identified by the Group,Version and Kind (GVK), there is a list with a few of the most common objects that can be used for discovering:
- v1/service
- serving.knative.dev/v1/service
- v1/pod
- apps/v1/deployment
- apps.openshift.io/v1/deploymentconfig
- apps/v1/statefulset
- route.openshift.io/v1/route
- networking.k8s.io/v1/ingress
Keep in mind that the GVK information is mandatory, however the namespace/project is optional and, if empty, the one where the application is running will be used. The resource to be queried is always the last item in the URI.
Helping the Service Discovery engine be more precise
The engine allows users to set query strings that helps the discovery process to select the correct resource. The available parameters are:
- Custom Labels: Can be used to filter services in cases where two different services that have the same Label Selector but expose different ports. In such cases, the custom label will be used to filter the right service. The custom label accepts multiple values separated by a semicolon. In the following example, we have two labels, app-port and app-revision:
kubernetes:v1/service/test/my-service?labels=app-port=default;app-revision=10
- Port Name: A container can expose more than one port, in which case the engine might not return the expected port. The order of precedence of the engine is/looks like this: user defined port name -> https -> port named as http or web -> first port in the list. The port-name can be defined to help the engine use the correct port for such cases where the precedence shown above is not able to select the correct port. The port name can be defined as:
kubernetes:v1/pod/test/my-pod?port-name=my-port
Debugging the communication between client and the K8s API
By default, the okhttp interceptor logging is disabled to avoid polluting the logs with information that might be not needed. However it can be enabled just by setting the following Quarkus property:
quarkus.log.category."okhttp3.OkHttpClient".level=INFO
Action Time!
Let’s see the service discovery engine into action. For this example we have a very simple application that will consume a serverless application running on Minikube with Knative capability enabled. In this link you can find information about how to install Minukube and here how to enable the Knative addon.
With Minikube running with Knative configured, let’s deploy the serverless-workflow-greeting-quarkus, for that, execute the following commands:
# Create a new namespace and set it as the default
$ kubectl create namespace greeting-quarkus
$ kubectl config set-context --current --namespace=greeting-quarkusNote that there is a tool called kubectx that helps to select the default namespace.
To be able to directly build the container application using the in-cluster Docker Daemon from Minikube, execute the following command:
The post Kogito Service Discovery for Workflows appeared first on KIE Community.